MapReduce的初次尝试
====前提:
搭建好集群环境(zookeeper、hadoop、hbase)。
搭建方法这里就不进行介绍了,网上有很多博客在介绍这些。
====简单需求:
WordCount单词计数,号称Hadoop的HelloWorld。所以,我打算通过这个来初体验一下Hadoop。需求如下:
①、计算文件中出现每个单词的频数
②、输入结果按照字母顺序进行排序

====Map过程:
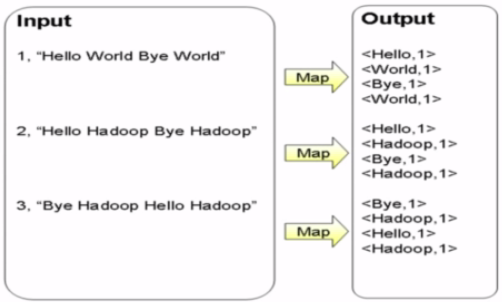
首先将文件进行切分成单词。将所有单词的项目都聚到一起。生成key-value的中间结果。
====Reduce过程
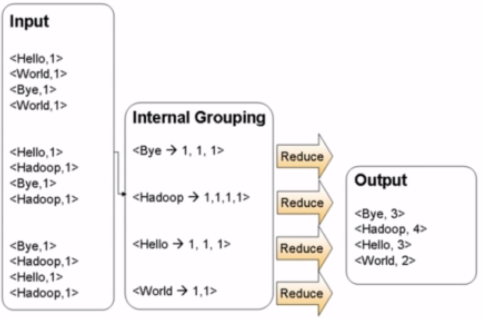
拿到之前Map的中间结果,进行合并(归约)。
====源代码
源代码来自慕课网,由于我自己学习需要,放到了我的Github空间上了。
https://github.com/quchunhui/WordCount
====上传Jar包
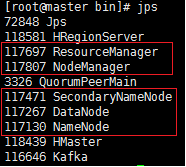
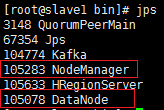
首先需要确认Linux集群运转是否正常。使用jps命令查看。确保hadoop相关进程的存在。
需要注意一点,不同版本的Hadoop的jps结果可能不一样。我在看慕课网的视频的时候,
发现人家里面还有TaskTracker和JobTracker呢,但是新版本的Hadoop就已经没有。
并不是集群环境的问题。具体什么是正确的,可以去查看官网的帮助文档。
①、在Master端的jps结果
②、在Slave端的jps结果
然后,将写完的代码达成jar包。由于我使用的是Mave环境,所以在Maven环境下使用mvn package进行打包即可。
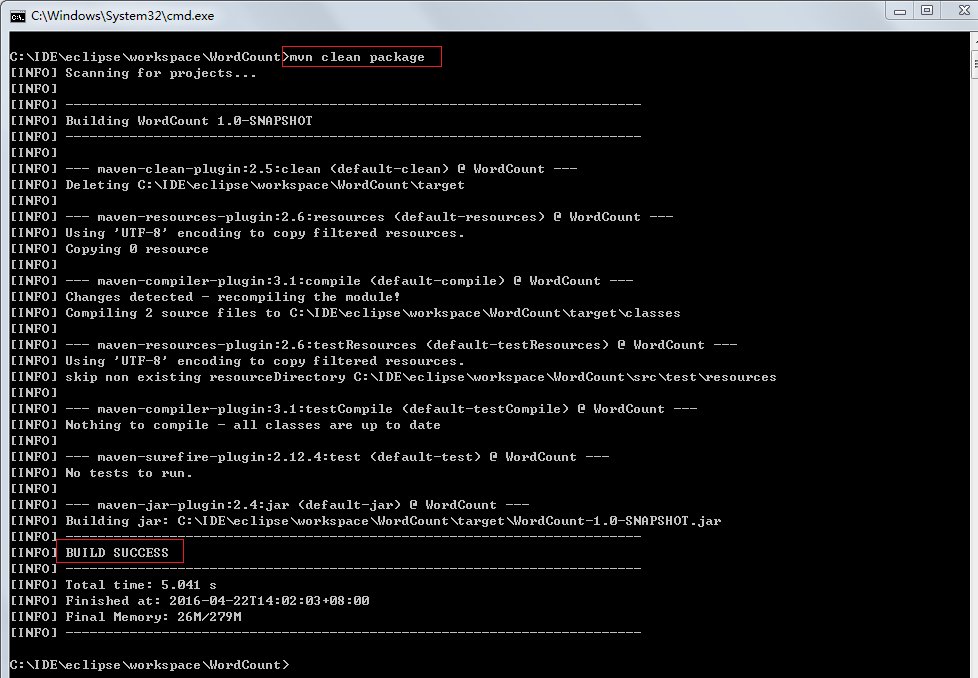
====上传文件至hdfs文件目录
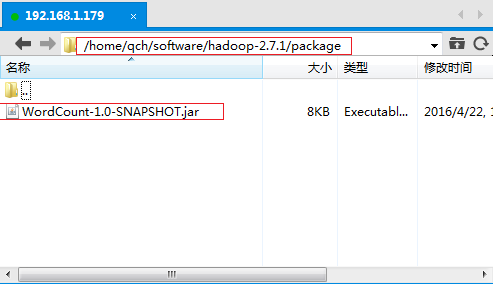
①、将上述步骤中生成的jar包上传到Linux服务器上。
我在HDOOP_HOME的根目录下创建了一个专门用于存放jar包的文件夹package。将生成的jar包上传到这里
/home/qch/software/hadoop-2.7.1/package
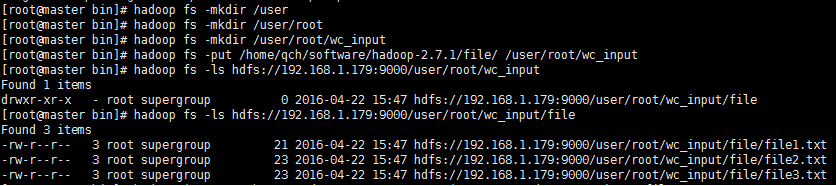
②、使用hadoop fs -put命令将数据源文件到hdfs文件目录
注意,这里是hdfs文件目录,并非是Linux系统上的某个文件夹。如果目录不存在,需要通过hadoop fs -mkdir命令自己手动去逐层创建。
我这里将上述3个文件上传到了hdfs文件目录[/user/root/wc_input]上了。
====程序运行
①、通过【hadoop jar <jar> [mainClass] args…】命令来运行程序。
命令:hadoop jar ../package/WordCount-1.0-SNAPSHOT.jar test.WordCount wc_input/file wc_output
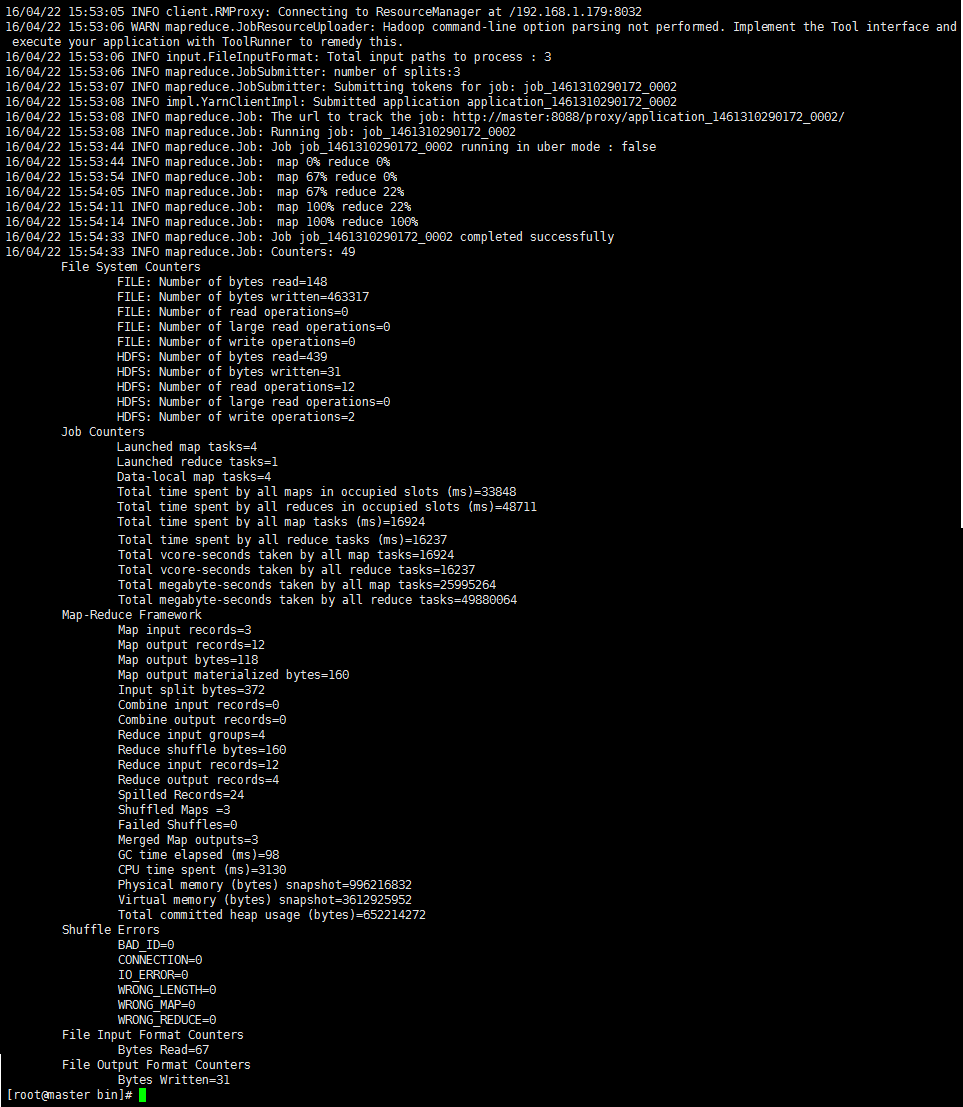
②、运行成功之后,可以通过命令来查看hdfs上的生成结果是否正确。
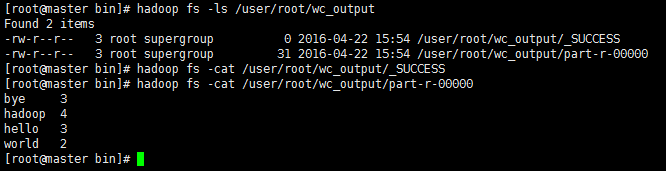
====总结:
我犯的最小白的错误就是,不知道需要将文件上传到hdfs文件目录下面。希望以后加深对hdfs的了解。
这也就是我今天(2016/4/22。)的第一个mapreduce成果。
下一步需要真正去进行我的MapReduce工作了,需要考虑按照什么规则进行Map和Reduce。这才是重中之重。
--END--
MapReduce的初次尝试的更多相关文章
- 20145330《Java学习笔记》第一章课后练习8知识总结以及IDEA初次尝试
20145330<Java学习笔记>第一章课后练习8知识总结以及IDEA初次尝试 题目: 如果C:\workspace\Hello\src中有Main.java如下: package cc ...
- 初次尝试使用jenkins+python+appium构建自动化测试
初次尝试使用jenkins+python+appium构建自动化测试 因为刚刚尝试使用jenkins+python+appium尝试,只是一个Demo需要很多完善,先记录一下今天的成果,再接再厉 第一 ...
- 孤荷凌寒自学python第五十七天初次尝试使用python来连接远端MongoDb数据库
孤荷凌寒自学python第五十七天初次尝试使用python来连接远端MongoDb数据库 (完整学习过程屏幕记录视频地址在文末) 今天是学习mongoDB数据库的第三天.感觉这个东西学习起来还是那么困 ...
- 孤荷凌寒自学python第五十二天初次尝试使用python读取Firebase数据库中记录
孤荷凌寒自学python第五十二天初次尝试使用python读取Firebase数据库中记录 (完整学习过程屏幕记录视频地址在文末) 今天继续研究Firebase数据库,利用google免费提供的这个数 ...
- 孤荷凌寒自学python第五十一天初次尝试使用python连接Firebase数据库
孤荷凌寒自学python第五十一天初次尝试使用python连接Firebase数据库 (完整学习过程屏幕记录视频地址在文末) 今天继续研究Firebase数据库,利用google免费提供的这个数据库服 ...
- 微信小程序开发初次尝试-----实验应用制作(一)
初次尝试微信小程序开发,在此写下步骤以做记录和分享. 1.在网上找了很多资料,发现这位知乎大神提供的资料非常全面. 链接 https://www.zhihu.com/question/50907897 ...
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- Docker Compose + Traefik v2 快速安装, 自动申请SSL证书 http转https 初次尝试
前言 昨晚闲得无聊睡不着觉,拿起服务器尝试部署了一下Docker + Traefik v2.1.6 ,以下是一些配置的总结,初次接触,大佬勿喷. 我的系统环境是 Ubuntu 18.04.3 LTS ...
- 百度地图API试用--(初次尝试)
2016-03-17: 百度地图API申请key的步骤相对简单,不做过多阐述. 初次使用百度地图API感觉有点神奇,有些功能加进来以后有点问题,注释掉等有空再解决. 代码如下: <%@ page ...
随机推荐
- (转)Inno Setup入门(十)——操作注册表
本文转载自:http://blog.csdn.net/yushanddddfenghailin/article/details/17250871 有些程序需要随系统启动,或者需要建立某些文件关联等问题 ...
- python学习 (二十八) Python的for 循环
1: for 循环可以循环如下类型: my_string = "abcabc" // 字符串类型 for c in my_string: print(c, end=' ') car ...
- jdbc调用sparksql on yarn
spark sql访问hive表 1.将hive-site.xml拷贝到spark目录下conf文件夹 2.(非必需)将mysql的jar包引入到spark的classpath,方式有如下两种: 方式 ...
- java 红包规则
java 红包规则 拼手气红包: 规则:最大金额:全部金额/个数*倍数 最小金额:0.01 最后一个红包是全部金额-领取金额 随机分配 package com.utils; import java.m ...
- C# 在根据窗体中的表格数据生成word文档时出错
出错内容为:
- 一分钟学会 ConstraintLayout 之从属性角度理解布局
ConstraintLayout 在 Android 开发中,我们通常是手写布局,很少会用拖动来写布局,虽然 ConstraintLayout 在 I/O 上以拖动来展现了各种功能,我估计在以后开发中 ...
- tornado 自定义session (一)
tornado 中没有session功能,需要我们自己实现. 目录: settings: settings = { 'template_path': 'templates', 'static': 's ...
- C/C++字符串查找函数 <转>
C/C++ string库(string.h)提供了几个字符串查找函数,如下: memchr 在指定内存里定位给定字符 strchr 在指定字符串里定位给定字符 strcspn 返回在字符串str1里 ...
- 塔防游戏 Day3
1. 添加按钮动画 选择 Button->Transition 为 Animation ,然后自定义四种状态动画即可. 2. 控制升级面板的显示和隐藏 // 升级处理 // 若点击同一炮塔,并且 ...
- idea使用jrebel热部署插件
首先通过idea下载JReble插件 访问http://idea.lanyus.com/网站 跟着弹出框的步骤走就可以实现了: 在idea中使用tomcat部署项目 不要使用war:使用下面的文件