ElasticSearch高可用集群环境搭建和分片原理
1、ES是如何实现分布式高并发全文检索
2、简单介绍ES分片Shards分片技术
3、为什么ES主分片对应的备分片不在同一台节点存放
4、索引的主分片定义好后为什么不能做修改
5、ES如何实现高可用容错方案
6、搭建Linux上环境三台ES高可用集群环境
ES是如何解决高并发
ES是一个分布式全文检索框架,隐藏了复杂的处理机制,核心内容 分片机制、集群发现、分片负载均衡请求路由。
ES基本概念名词
Cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
Shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
Recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
ES为什么要实现集群
ES集群中索引可能由多个分片构成,并且每个分片可以拥有多个副本。通过将一个单独的索引分为多个分片,我们可以处理不能在一个单一的服务器上面运行的大型索引,简单的说就是索引的大小过大,导致效率问题。不能运行的原因可能是内存也可能是存储。由于每个分片可以有多个副本,通过将副本分配到多个服务器,可以提高查询的负载能力。
GET _cat/health
ES集群核心原理分析:
数据存储。
1、每个索引会被分成多个分片shards进行存储,默认创建索引是分配5个分片进行存储。
每个分片都会分布式部署在多个不同的节点上进行部署,该分片成为primary shards。
注意:索引的主分片primary shards定义好后,后面不能做修改。
2、为了实现高可用数据的高可用,主分片可以有对应的备分片replics shards,replic shards分片承载了负责容错、以及请求的负载均衡。
注意: 每一个主分片为了实现高可用,都会有自己对应的备分片,主分片对应的备分片不能存放同一台服务器上(单台ES没有备用分片的)。主分片primary shards可以和其他replics shards存放在同一个node节点上。
在往主分片服务器存放数据时候,会对应实时同步到备用分片服务器:
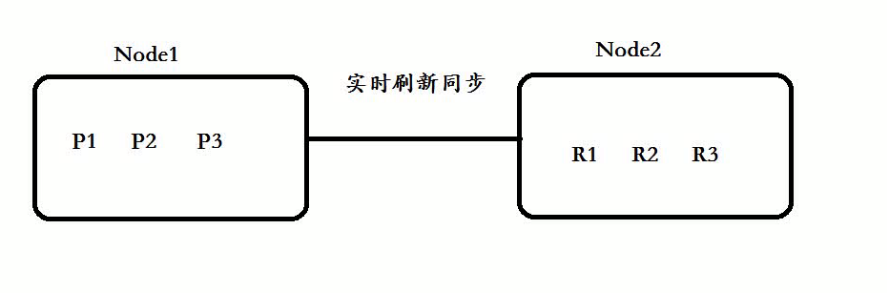
但是查询时候,所有(主、备)都进行查询。
主的可以存放副的:
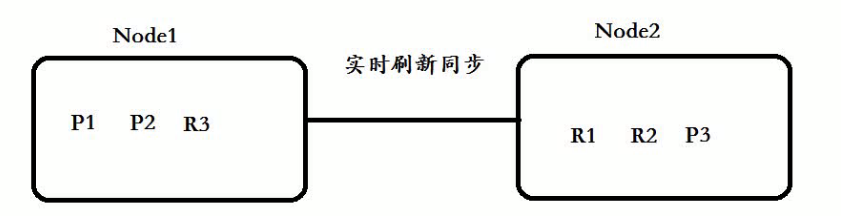
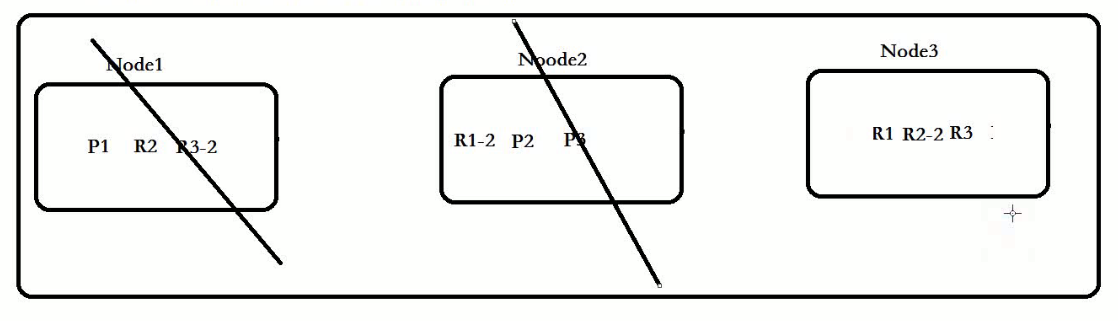
Node1 :P1+P2+R3组成了完整 的数据! 分布式存储
EA核心存放的核心数据是索引!
如果ES实现了集群的话,会将单台服务器节点的索引文件使用分片技术,分布式存放在多个不同的物理机器上。
分片就是将数据拆分成多台节点进行存放
在ES分片技术中,分为主(primary)分片、副(replicas)分片。这样做是为了容错性
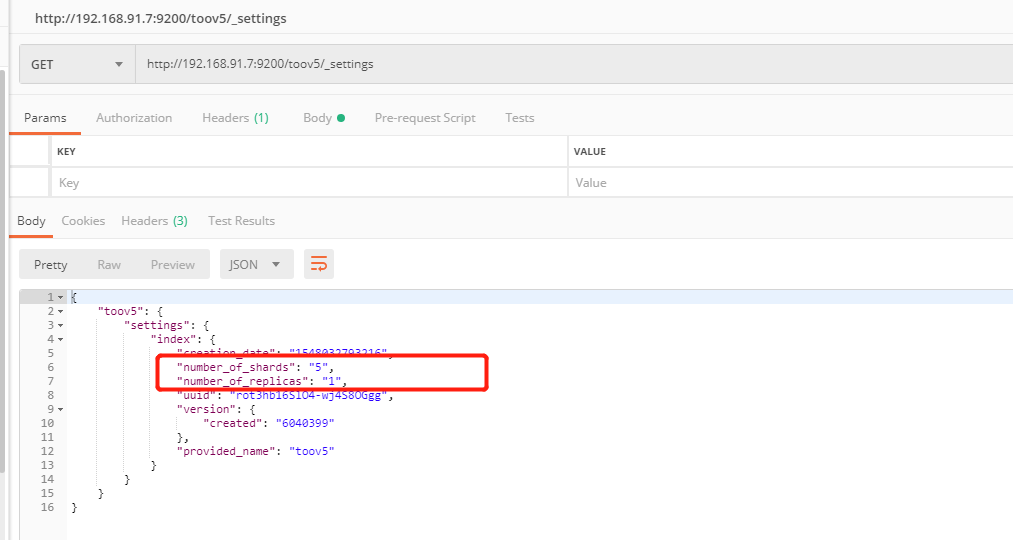
5: 每个索引拆分5片存储
1:备份一份
在ES中每一个主分片都对应一个副分片
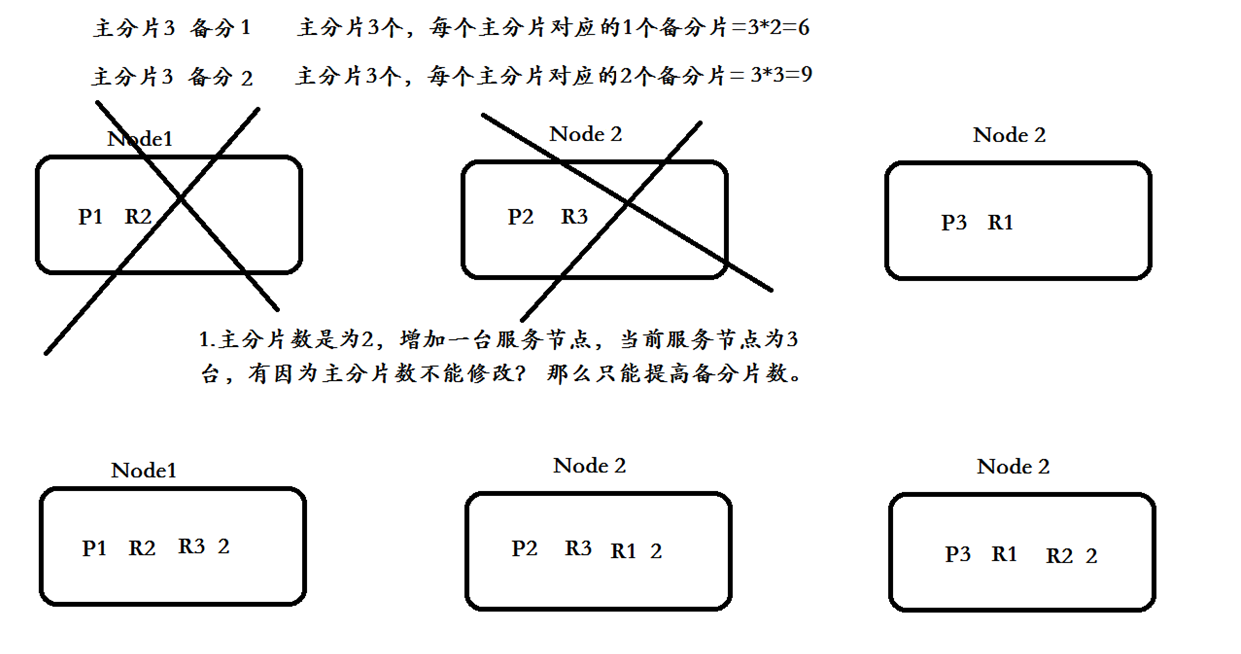
三个节点 6/3 为 2 每个节点存放两个分片
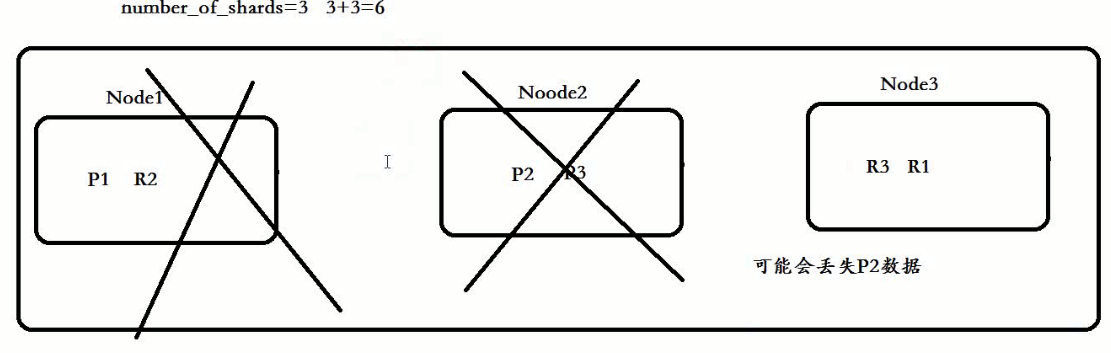
在创建索引时候,主分片数量定义好后是不能修改的
修改副的分片 number_of_replica 2 3个主分片6个备分片 一共9个
官方建议 节点的平方数 !!
数据路由
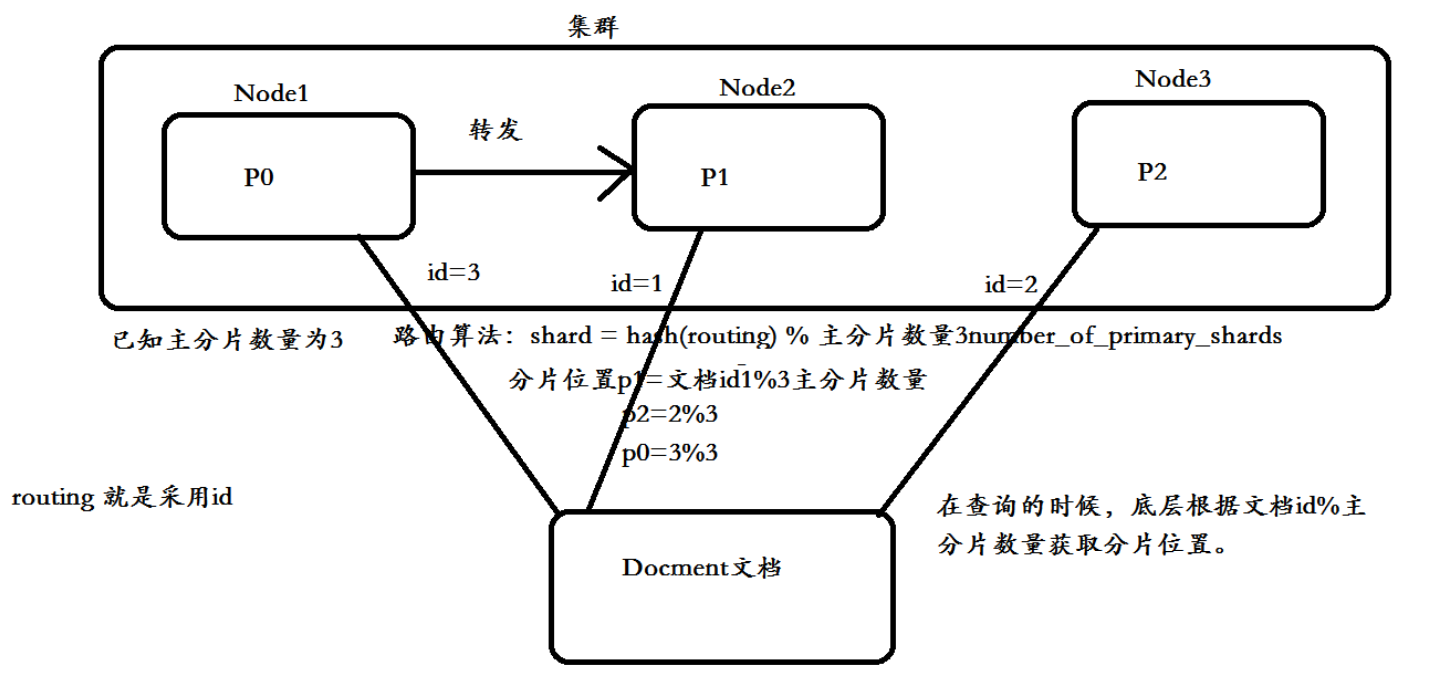
documnet routing(数据路由)
当客户端发起创建document的时候,es需要确定这个document放在该index哪个shard上。这个过程就是数据路由。
路由算法:shard = hash(routing) % number_of_primary_shards
如果number_of_primary_shards在查询的时候取余发生的变化,无法获取到该数据
画图演示
注意:索引的主分片数量定义好后,不能被修改
计算的算法 取模时候 除数改变了 查询时候 怎么办?! 所以 不能乱改啊~
集群环境的搭建
如果连接P0查询不到的话 会自动转发到另一台去查询。
集群的搭建:核心思想无非就是 配置不同的节点id 配置形同集群名称
4台服务器实现集群的话,会配置三个不同的elasticsearch.yml
配置:
vi elasticsearch.yml
cluster.name: myes ###保证三台服务器节点集群名称相同
node.name: node-1 #### 每个节点名称不一样 其他两台为node-2 ,node-3
network.host: 192.168.91.7 #### 实际服务器ip地址 实际项目外网ip 哦
discovery.zen.ping.unicast.hosts: ["192.168.91.7", "192.168.91.8","192.168.91.9"]
##多个服务集群ip
discovery.zen.minimum_master_nodes: 1
集群通信是走9300端口通信
注意如果你是虚拟机克隆data文件会导致数据不同步
报该错误解决办法 进入到data中 删除 node这个目录 重启就OK了
failed to send join request to master
因为克隆导致data文件也克隆呢,直接清除每台服务器data文件。

启动配置好的三台节点:
随便访问一台主机: http://192.168.91.8:9200/_cat/nodes?pretty
验证:

带 * 为master
如果某一台宕机了 可以自动选举~~ *会转移哦
ES分布式做的特别好~
ElasticSearch高可用集群环境搭建和分片原理的更多相关文章
- Kafaka高可用集群环境搭建
zk集群环境搭建:https://www.cnblogs.com/toov5/p/9897868.html 三台主机每台的Java版本1.8 下面kafka集群的搭建: 3台虚拟机均进行以下操作: ...
- SpringCloud之Eureka高可用集群环境搭建
注册中心集群 在微服务中,注册中心非常核心,可以实现服务治理,如果一旦注册出现故障的时候,可能会导致整个微服务无法访问,在这时候就需要对注册中心实现高可用集群模式. Eureka集群相当简单:相互注册 ...
- rabbitmq+haproxy+keepalived高可用集群环境搭建
1.先安装centos扩展源: # yum -y install epel-release 2.安装erlang运行环境以及rabbitmq # yum install erlang ... # yu ...
- CentOS下RabbitMq高可用集群环境搭建
准备工作 1,准备两台或多台安装有rabbitmq-server服务的服务器 我这里准备了两台,分别如下: 192.168.40.130 rabbitmq01192.168.40.131 rabbit ...
- Mysql高可用集群环境介绍
MySQL高可用集群环境搭建 01.MySQL高可用环境方案 02.MySQL主从复制原理 03.MySQL主从复制作用 04.在Linux环境上安装MySQL 05.在MySQL集群环境上配置主从复 ...
- Apache httpd和JBoss构建高可用集群环境
1. 前言 集群是指把不同的服务器集中在一起,组成一个服务器集合,这个集合给客户端提供一个虚拟的平台,使客户端在不知道服务器集合结构的情况下对这一服务器集合进行部署应用.获取服务等操作.集群是企业应用 ...
- Flink的高可用集群环境
Flink的高可用集群环境 Flink简介 Flink核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布,数据通信以及容错机制等功能. 因现在主要Flink这一块做先关方面的学习, ...
- centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课
centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课 heartbeat是Linu ...
- Mysql双主双从高可用集群的搭建且与MyCat进行整合
1.概述 老话说的好:瞻前顾后.患得患失只会让我们失败,下定决心,干就完了. 言归正传,之前我们聊了Mysql的一主一从读写分离集群的搭建,虽然一主一从或一主多从集群解决了并发读的问题,但由于主节点只 ...
随机推荐
- 61、常规控件(4)TabLayout-便捷实现标签
<android.support.design.widget.TabLayout android:id="@+id/tabs" android:layout_width=&q ...
- 《ASP.NET1200例》C#在网页上编写动态时钟
包含Timer类的命名空间有3个 Timer Class (System.Threading) Timer Class (System.Windows.Forms) 一般用于窗体程序 Timer ...
- MVC、MVP、MVVM
1 简介 演变:MVC ——> MVP ——> MVVM 英文原文:MVC vs. MVP vs. MVVM 三者的目的都是分离关注,使得UI更容易变换(从Winform变为Webform ...
- 【BZOJ4709】[Jsoi2011]柠檬 斜率优化+单调栈
[BZOJ4709][Jsoi2011]柠檬 Description Flute 很喜欢柠檬.它准备了一串用树枝串起来的贝壳,打算用一种魔法把贝壳变成柠檬.贝壳一共有 N (1 ≤ N ≤ 100,0 ...
- iOS 下载
#import "ViewController.h" @interface ViewController () @property (strong, nonatomic) NSMu ...
- 170120、java 如何在pdf中生成表格
1.目标 在pdf中生成一个可变表头的表格,并向其中填充数据.通过泛型动态的生成表头,通过反射动态获取实体类(我这里是User)的get方法动态获得数据,从而达到动态生成表格. 每天生成一个文件夹存储 ...
- c# public private protected internal protected internal
一个 访问修饰符 定义了一个类成员的范围和可见性.C# 支持的访问修饰符如下所示: public:所有对象都可以访问: private:对象本身在对象内部可以访问: protected:只有该类对象及 ...
- delphi------项目类型
Console Application:控制台应用程序 writeln('HelloWorld'); //接收用户输入字符 readln: //直到用户输入回车结束 VCL Forms Applica ...
- 解决 free(): invalid pointer: 0x00000000019ff700 运行时报错(caffe)(libtool使用)
编译成功,运行时报错: 在使用 pytorch or tensorflow or caffe 时,都可能存在这个问题: *** Error in `xxx': free(): invalid poin ...
- Css选择器定位详解
1.使用 class 属性来定位元素,方法如下: driver.findElement(By.cssSelector("input.login")); 即可以先指定一个 HTML的 ...