爬虫入门之反反爬虫机制cookie UA与中间件(十三)
1. 通常防止爬虫被反主要有以下几个策略
(1)动态设置User-Agent(随机切换User-Agent,模拟不同的浏览器)
方法1: 修改setting.py中的User-Agent
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Hello World' #User-Agent
方法2: 修改setting中的 DEFAULT_REQUEST_HEADERS
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Hello World'
}
方法3 : 在代码中修改
class HeadervalidationSpider(scrapy.Spider):
name = 'headervalidation'
allowed_domains = ['helloacm.com']
def start_requests(self):
header={'User-Agent':'Hello World'}
yield scrapy.Request(url='http://helloacm.com/api/user-agent/',headers=header,callback=self.parse)
def parse(self, response):
print ('*'*20)
print response.body
(2)禁用Cookies
就是不启用cookies middleware,不向Server发送cookies,有些网站通过cookie的使用发现爬虫行为
可以通过settings.py中的
COOKIES_ENABLED, 控制 CookiesMiddleware 开启或关闭设置延迟下载(防止访问过于频繁,设置为 2秒 或更高)
DOWNLOAD_DELAYGoogle Cache 和 Baidu Cache:如果可能的话,使用谷歌/百度等搜索引擎服务器页面缓存获取页面数据。
使用IP地址池:VPN和代理IP,现在大部分网站都是根据IP来ban的
使用Crawlera(专用于爬虫的代理组件),正确配置和设置下载中间件后,项目所有的request都是通过crawlera发出。在settings中打开下载中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_crawlera.CrawleraMiddleware': 600
}
CRAWLERA_ENABLED = True
CRAWLERA_USER = '注册/购买的UserKey'
CRAWLERA_PASS = '注册/购买的Password'
2.设置下载中间件(Downloader Middlewares)
下载中间件是处于引擎(crawler.engine)和下载器(crawler.engine.download())之间的一层组件,可以有多个下载中间件被加载运行。
- 当引擎传递请求给下载器过程中,下载中间件可以对请求进行处理 (增加http header信息 proxy信息等);
- 在下载器完成http请求,传递响应给引擎过程中,下载中间件可以对响应进行处理(例如进行gzip的解压等)
要激活下载器中间件组件,将其加入到 DOWNLOADER_MIDDLEWARES 设置中。 该设置是一个字典(dict),键为中间件类的路径,值为其中间件的顺序(order)。
#开放下载中间件
DOWNLOADER_MIDDLEWARES = {
'mySpider.middlewares.MyDownloaderMiddleware': 543,
}
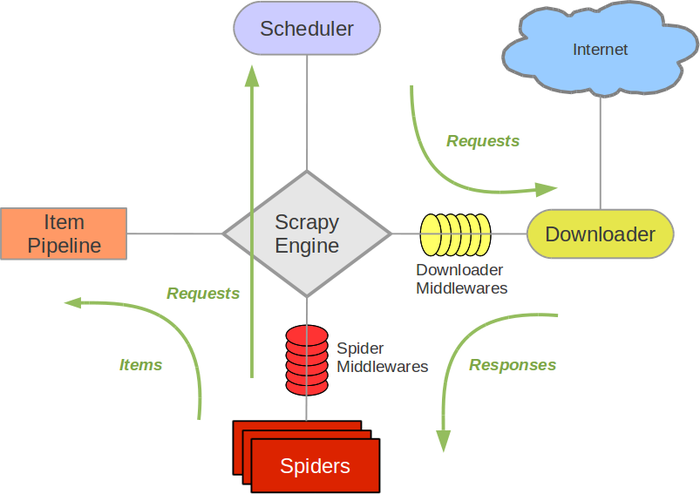
一般下载中间件可以定义一下一个或多个方法:
process_request(self, request, spider)
- 当每个request通过下载中间件时,该方法被调用。
- process_request() 返回其中之一:None 、 Response 对象、 Request 对象或 raise IgnoreRequest:
- 如果其返回 None ,Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用, 该request被执行(其response被下载)。
- 如果返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或 process_exception() 方法。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
- 如果其返回 Request 对象,Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
- 如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。
- 参数:
request (Request 对象)– 处理的requestspider (Spider 对象)– 该request对应的spider
process_response(self, request, response, spider)
当下载器完成http请求,传递响应给引擎的时候调用
- process_response() 必须返回以下其中之一: 返回一个 Response 对象、 返回一个 Request 对象或raise一个 IgnoreRequest 异常。
- 如果其返回一个 Response (可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
- 如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
- 如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
- 参数:
request (Request 对象)– response所对应的requestresponse (Response 对象)– 被处理的responsespider (Spider 对象)– response所对应的spider
3 案例
创建
middlewares.py文件Scrapy代理IP、Uesr-Agent的切换都是通过
DOWNLOADER_MIDDLEWARES进行控制,我们在settings.py同级目录下创建middlewares.py文件,包装所有请求。
# middlewares.py
import random
from settings import USER_AGENTS
from settings import PROXIES
# 随机的User-Agent
class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
request.headers.setdefault("User-Agent", useragent)
# 随机代理IP
class RandomProxy(object):
def process_request(self, request, spider):
proxy = random.choice(PROXIES)
request.meta['proxy'] = "http://" + proxy['ip_port']
- 修改settings.py配置USER_AGENTS和PROXIES
添加USER_AGENTS
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)"]
添加代理IP设置PROXIES:
PROXIES = [
{'ip_port': '111.8.60.9:8123'},
{'ip_port': '101.71.27.120:80'},
{'ip_port': '122.96.59.104:80'},
{'ip_port': '122.224.249.122:8088'},
]
除非特殊需要,禁用cookies,防止某些网站根据Cookie来封锁爬虫。
COOKIES_ENABLED = False
设置延迟
DOWNLOAD_DELAY = 3
最后设置setting.py里的DOWNLOADER_MIDDLEWARES,添加自己编写的下载中间件类
DOWNLOADER_MIDDLEWARES = {
#'mySpider.middlewares.MyCustomDownloaderMiddleware': 543,
'mySpider.middlewares.RandomUserAgent': 81,
'mySpider.middlewares.ProxyMiddleware': 100
}
爬虫入门之反反爬虫机制cookie UA与中间件(十三)的更多相关文章
- 【爬虫入门手记03】爬虫解析利器beautifulSoup模块的基本应用
[爬虫入门手记03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.Bea ...
- Python爬虫入门教程 57-100 python爬虫高级技术之验证码篇3-滑动验证码识别技术
滑动验证码介绍 本篇博客涉及到的验证码为滑动验证码,不同于极验证,本验证码难度略低,需要的将滑块拖动到矩形区域右侧即可完成. 这类验证码不常见了,官方介绍地址为:https://promotion.a ...
- Python爬虫入门教程 64-100 反爬教科书级别的网站-汽车之家,字体反爬之二
说说这个网站 汽车之家,反爬神一般的存在,字体反爬的鼻祖网站,这个网站的开发团队,一定擅长前端吧,2019年4月19日开始写这篇博客,不保证这个代码可以存活到月底,希望后来爬虫coder,继续和汽车之 ...
- Python爬虫入门教程 58-100 python爬虫高级技术之验证码篇4-极验证识别技术之一
目录 验证码类型 官网最新效果 找个用极验证的网站 拼接验证码图片 编写自动化代码 核心run方法 模拟拖动方法 图片处理方法 初步运行结果 拼接图 图片存储到本地 @ 验证码类型 今天要搞定的验证码 ...
- Python爬虫入门教程 53-100 Python3爬虫获取三亚天气做旅游参照
爬取背景 这套课程虽然叫爬虫入门类课程,但是里面涉及到的点是非常多,十分检验你的基础掌握的牢固程度,代码中的很多地方都是可以细细品味的. 为什么要写这么一个小东东呢,因为我生活在大河北,那雾霾醇厚的很 ...
- Python爬虫入门教程 50-100 Python3爬虫爬取VIP视频-Python爬虫6操作
爬虫背景 原计划继续写一下关于手机APP的爬虫,结果发现夜神模拟器总是卡死,比较懒,不想找原因了,哈哈,所以接着写后面的博客了,从50篇开始要写几篇python爬虫的骚操作,也就是用Python3通过 ...
- Python爬虫入门教程 59-100 python爬虫高级技术之验证码篇5-极验证识别技术之二
图片比对 昨天的博客已经将图片存储到了本地,今天要做的第一件事情,就是需要在两张图片中进行比对,将图片缺口定位出来 缺口图片 完整图片 计算缺口坐标 对比两张图片的所有RBG像素点,得到不一样像素点的 ...
- Python爬虫入门教程 56-100 python爬虫高级技术之验证码篇2-开放平台OCR技术
今日的验证码之旅 今天你要学习的验证码采用通过第三方AI平台开放的OCR接口实现,OCR文字识别技术目前已经比较成熟了,而且第三方比较多,今天采用的是百度的. 注册百度AI平台 官方网址:http:/ ...
- Python爬虫入门教程 55-100 python爬虫高级技术之验证码篇
验证码探究 如果你是一个数据挖掘爱好者,那么验证码是你避免不过去的一个天坑,和各种验证码斗争,必然是你成长的一条道路,接下来的几篇文章,我会尽量的找到各种验证码,并且去尝试解决掉它,中间有些技术甚至我 ...
随机推荐
- Python爬虫:微博粉丝列表
前言 本来打算做一个关于微博粉丝列表的爬虫,可以统计一下某个微博账号的粉丝里面,僵尸粉(水军)的数量,大V数量. 结果写完爬虫才发现,现在微博只给人看粉丝列表的前5页.......哈哈,好吧.挺无奈的 ...
- 描边shader(法线外拓)
描边的思路是需要两个pass.第一个pass让顶点沿着法线方向延伸出去,使得模型变大一圈.第二个pass正常渲染,让正常渲染的模型挡在第一个pass之上,这样就会露出延伸出去的部分,延伸出去的就是我们 ...
- Python+Selenium之常用模块
要用webdriver:from selenium import webdriver eg: driver = webdriver.Chrome() driver.maximize_wind ...
- 初次使用github的艰难尝试。
序言 github是全英文的网站,初次使用在没有翻译成中文的情况下很容易做出很多无意义或误操作. 当对本地的文件进行修改后,有时候只是想更新到fork下来的自己的仓库里,看看改得效果如何 .有时候是想 ...
- Session.Abandon和Session.Clear有何不同 (转)
Session.Clear()就是把Session对象中的所有项目都删除了, Session对象里面啥都没有.但是Session对象还保留.Session.Abandon()就是把当前Session对 ...
- 使用 Qt 获取 UDP 数据并显示成图片(2)
本文首发于 BriFuture 的 个人博客 在我的前一篇文章 使用 Qt 获取 UDP 数据并显示成图片 中,我讲了如何用 Python 模拟发送数据,如何在 Qt 中高效的接收 UDP 数据包并将 ...
- Git - 远程库的创建与认证
前些日子因为某些原因,需要在windows上创建一个remote仓库. 由于实在是太麻烦而且时间紧急,就直接用了gitstack. 发现这个东西居然需要付费,未认证时只能创建两个用户. 其实对我而言足 ...
- java 散列运算浅分析 hash()
文章部分代码图片和总结来自参考资料 哈希和常用的方法 散列,从中文字面意思就很好理解了,分散排列,我们知道数组地址空间连续,查找快,增删慢,而链表,查找慢,增删快,两者结合起来形成散列 ...
- Java温故而知新(5)设计模式详解(23种)
一.设计模式的理解 刚开始“不懂”为什么要把很简单的东西搞得那么复杂.后来随着软件开发经验的增加才开始明白我所看到的“复杂”恰恰就是设计模式的精髓所在,我所理解的“简单”就是一把钥匙开一把锁的模式,目 ...
- Java String、string[]、List初始化方法
String初始化: 1.String str = new String("string1"); 2.String str = "string1"; Strin ...