二十、Hadoop学记笔记————Hive On Hbase
Hive架构图:
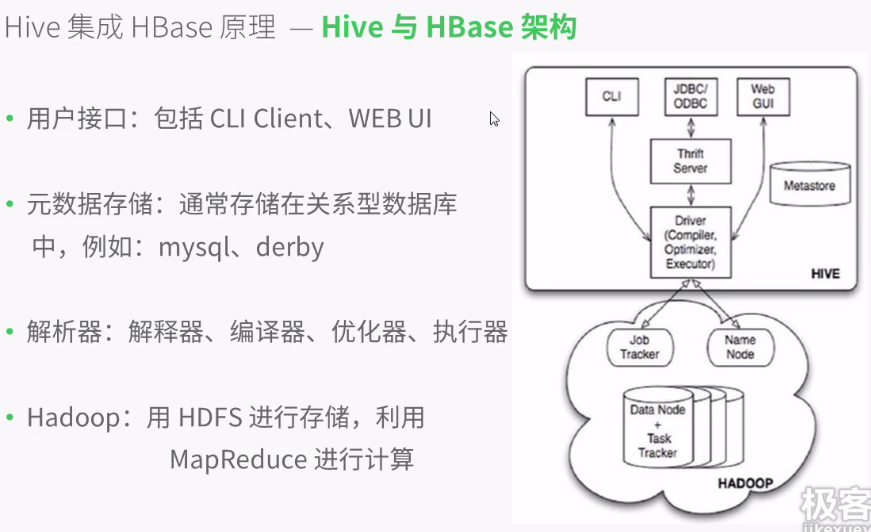
一般用户接口采用命令行操作,
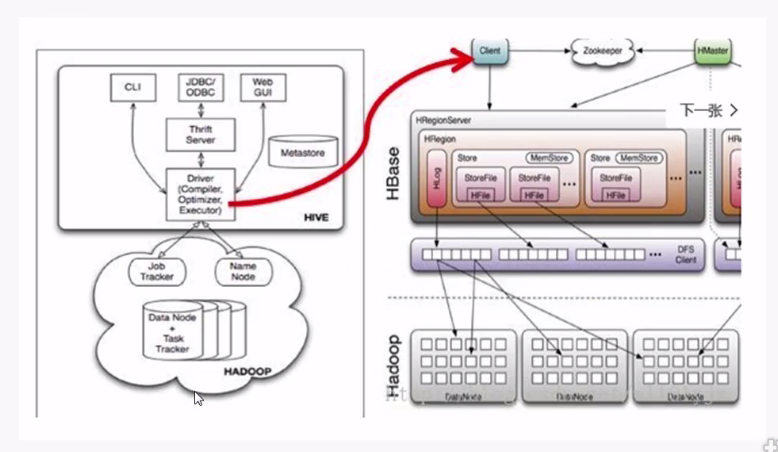
hive与hbase整合之后架构图:
使用场景
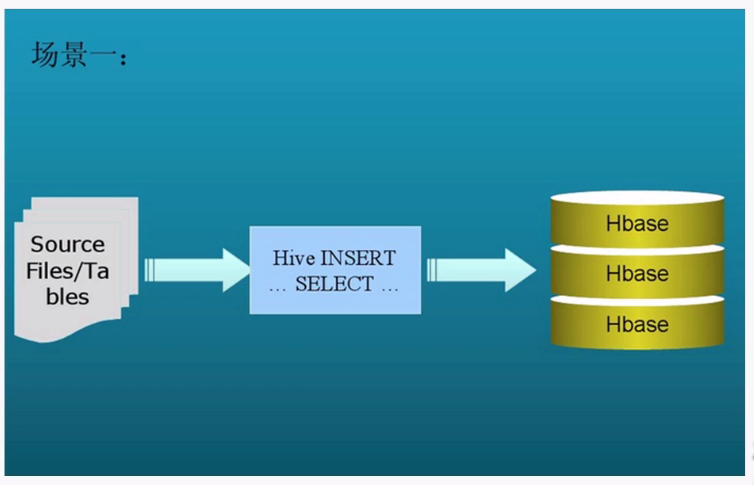
场景一:通过insert语句,将文件或者table中的内容加入到hive中,由于hive和hbase已经整合,因此也会加入到hbase当中
场景二:hbase不支持join或者gruop等,可以通过这种方式,让hbase支持sql语句等

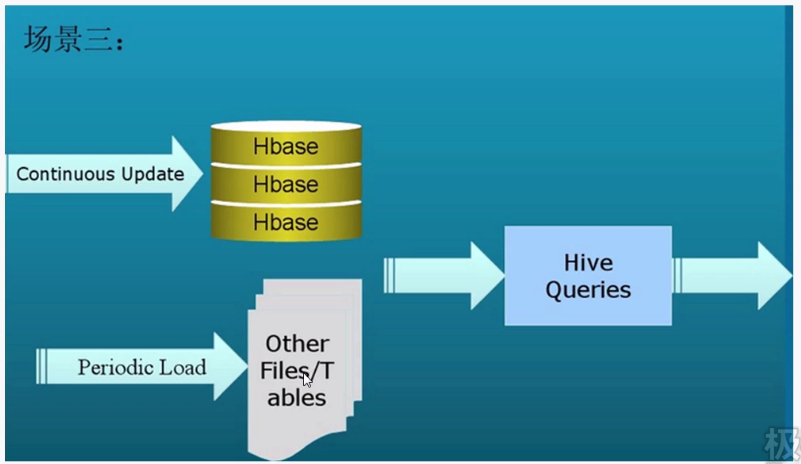
场景三,使用Hbase加载数据,然后用Hive查询数据,这样既有了Hbase的高速读写数据,也有了Hive的sql语句方便查询:
部署hive整合hbase环境:
先把Hbase中的lib包考入hive里的lib中,这样就不需要再配置环境变量:

进入hive命令行,在hive中创建一个能直接管理Hbase的表:

查询发现xyz创建完毕:
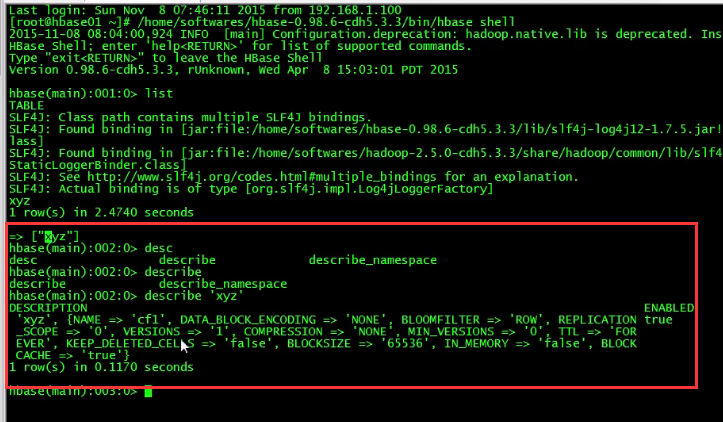
创建插入数据表:

创建文件准备插入hive的poke表:
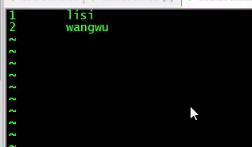
数据插入poke表,并且利用poke表插入之前创建的Hive和Hbase关联表:

而后利用poke表,将poke表中的数据插入hbase_table_1测试表中:
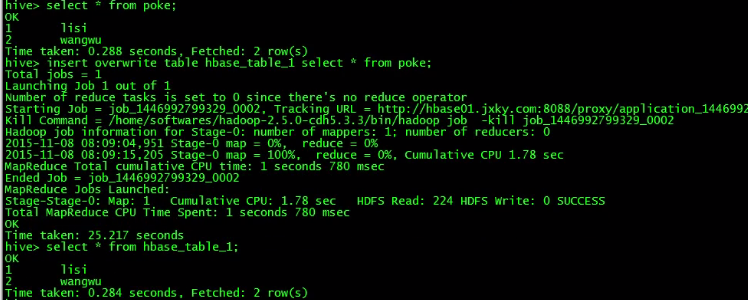
查询hbase的xyz表,发现数据已经插入,此时hive中的hbase_table_1表和hbase中的xyz表已经完成映射

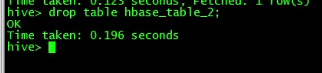
在hive中删除表hbase_table_1的同时hbase中的xyz表也会删除


之后模拟在hive中创建一个外部表与hbase相关联:
先在hbase中创建一个user表:

之后在hive中创建hbase关联外部表:

hbase中插入数据:

此时hive表中数据也同时加载了:

以这种方式关联映射的hive表,在删除之后并不会删除hbase中的表:



二十、Hadoop学记笔记————Hive On Hbase的更多相关文章
- 二十五、Hadoop学记笔记————Hive复习与深入
Hive主要为了简化MapReduce流程,使非编程人员也能进行数据的梳理,即直接使用sql语句代替MapReduce程序 Hive建表的时候元数据(表明,字段信息等)存于关系型数据库中,数据存于HD ...
- 二十二、Hadoop学记笔记————Kafka 基础实战 :消费者和生产者实例
kafka的客户端也支持其他语言,这里主要介绍python和java的实现,这两门语言比较主流和热门 图中有四个分区,每个图形对应一个consumer,任意一对一即可 获取topic的分区数,每个分区 ...
- 十九、Hadoop学记笔记————Hbase和MapReduce
概要: hadoop和hbase导入环境变量: 要运行Hbase中自带的MapReduce程序,需要运行如下指令,可在官网中找到: 如果遇到如下问题,则说明Hadoop的MapReduce没有权限访问 ...
- 二十四、Hadoop学记笔记————Spark的架构
master为主节点 一个集群中可能运行多个application,因此也可能会有多个driver DAG Scheduler就是讲RDD Graph拆分成一个个stage 一个Task对应一个Spa ...
- 二十三、Hadoop学记笔记————Spark简介与计算模型
spark优势在于基于内存计算,速度很快,计算的中间结果也缓存在内存,同时spark也支持streaming流运算和sql运算 Mesos是资源管理框架,作为资源管理和任务调度,类似Hadoop中的Y ...
- 二十一、Hadoop学记笔记————kafka的初识
这些场景的共同点就是数据由上层框架产生,需要由下层框架计算,其中间层就需要有一个消息队列传输系统 Apache flume系统,用于日志收集 Apache storm系统,用于实时数据处理 Spark ...
- 十八、Hadoop学记笔记————Hbase架构
Hbase结构图: Client,Zookeeper,Hmaster和HRegionServer相互交互协调,各个组件作用如下: 这几个组件在实际使用过程中操作如下所示: Region定位,先读取zo ...
- 十七、Hadoop学记笔记————Hbase入门
简而言之,Hbase就是一个建立在Hdfs文件系统上的数据库(mysql,orecle等),不同的是Hbase是针对列的数据库 Hbase和普通的关系型数据库区别如下: Hbase有一些基本的术语,主 ...
- 十、Hadoop学习笔记————Hive与Hbase以及RDBMS(关系型数据库)的关系
Hive目的是为了简化MapReduce编程 实际应用中,Hive与Hbase不经常链接
随机推荐
- LeetCode之“链表”:在O(1)时间删除链表节点
下边讨论暂不包括尾节点. 一般来说,我们要删除链表中的一个节点是需要知道其上一节点的.但我们真的需要吗? 其实我们可以将待删节点的下一节点的值和指向的下一节点赋予待删节点,然后删除待删节点的下一节点. ...
- 报表软件公司高价悬赏BUG,100块1个我真是醉了
一直在用帆软的报表软件FineReport来做项目,也一直关注着这个公司的发展. 看到<提BUG,拿奖金>的这个活动,有些疑问和思考. 一般FineReport新版本在正式发布前,都会经过 ...
- Linux常用命令(第二版) --网络通信命令
网络通信命令 1.write /usr/bin/write 格式: write [用户名] #用于向用户发送信息,前提是这个用户已经登录到了这台服务器主机,不然的话,也没有办法给他留言,所以,writ ...
- 【UML 建模】UML建模语言入门-视图,事物,关系,通用机制
. 作者 :万境绝尘 转载请注明出处 : http://blog.csdn.net/shulianghan/article/details/18964835 . 一. UML视图 1. Ration ...
- LeetCode之“动态规划”:Distinct Subsequences
题目链接 题目要求: Given a string S and a string T, count the number of distinct subsequences of T in S. A s ...
- Leetcode_223_Rectangle Area
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/46868363 Find the total area co ...
- IP封包的封装 - 首部内容
IP 封包的封装 目前因特网社会的 IP 有两种版本,一种是目前使用最广泛的 IPv4 (Internet Protocol version 4, 因特网协定第四版), 一种则是预期未来会热门的 IP ...
- SQLite数据库中多线程使用问题
由于项目是接手之前的烂尾项目,经常被吐槽说界面卡半天,后来发现项目里的网络请求,数据库操作都是在主线程.将一些长时间的操作换到多线程或者异步之后后,用户交互是变的顺畅多了,可是经常出现莫名其妙的闪退, ...
- 详解linux进程间通信-消息队列
前言:前面讨论了信号.管道的进程间通信方式,接下来将讨论消息队列. 一.系统V IPC 三种系统V IPC:消息队列.信号量以及共享内存(共享存储器)之间有很多相似之处. 每个内核中的 I P C结构 ...
- ios项目开发汇总
UI界面 iOS和Android 界面设计尺寸规范 http://www.alibuybuy.com/posts/85486.html iPhone app界面设计尺寸规范 http://www. ...