Spark中的Wordcount
通过scala语言基于local编写spark的Wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// Spark配置文件对象
val conf: SparkConf = new SparkConf()
// 设置Spark程序的名字
conf.setAppName("WordCount")
// 设置运行模式为local模式 即在idea本地运行
// local : 一个并行度
// local[2] : 两个并行度
// local[*] : 有多少用多少
conf.setMaster("local")
// Spark的上下文环境,相当于Spark的入口
val sc: SparkContext = new SparkContext(conf)
// 词频统计
// 1、读取文件
/**
* RDD : 弹性分布式数据集(可以先当成scala中的集合去使用)
*/
val linesRDD: RDD[String] = sc.textFile("scala/data/words.txt")
// 2、将每一行的单词切分出来
// flatMap: 在Spark中称为 算子
// 算子一般情况下都会返回另外一个新的RDD
val wordsRDD: RDD[String] = linesRDD.flatMap(kv=>kv.split(","))
// 3、按照单词分组
val groupRDD: RDD[(String, Iterable[String])] = wordsRDD.groupBy(kv=>kv)
// 4、统计每个单词的数量
val countRDD: RDD[String] = groupRDD.map(kv => {
val key: String = kv._1
val values: Iterable[String] = kv._2
// words.size直接获取迭代器的大小
// 因为相同分组的所有的单词都会到迭代器中
// 所以迭代器的大小就是单词的数量
val size: Int = values.size
key + "," + size
})
countRDD.saveAsTextFile("spark/data/wordcount.txt")
}
}

会报这个错
解决方案:
新建一个文件夹,放入这个文件

配置环境变量
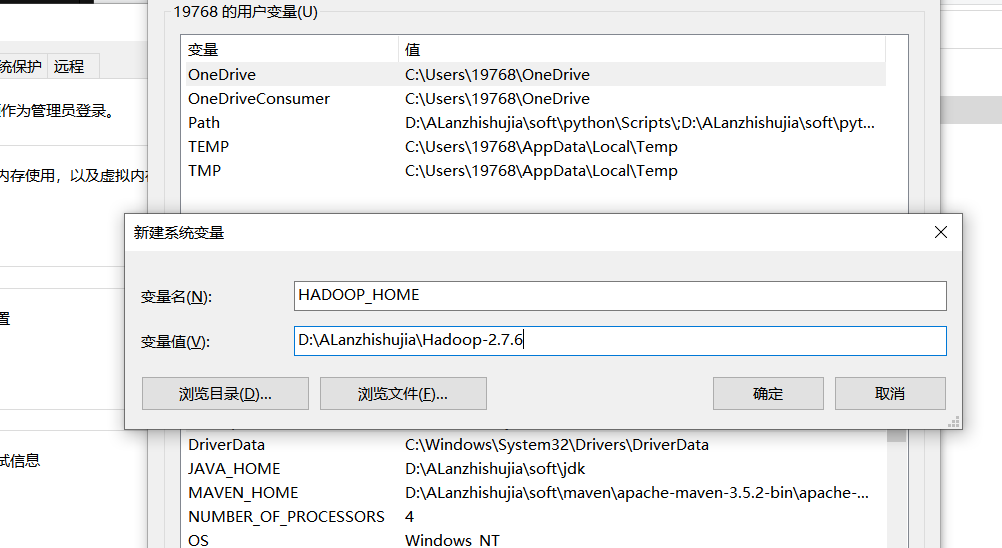
需要导入的依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
基于yarn去调度WordCount
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 1、去除setMaster("local")
* 2、修改文件的输入输出路径(因为提交到集群默认是从HDFS获取数据,需要改成HDFS中的路径)
* 3、在HDFS中创建目录
* hdfs dfs -mkdir -p /spark/data/words/
* 4、将数据上传至HDFS
* hdfs dfs -put words.txt /spark/data/words/
* 5、将程序打成jar包
* 6、将jar包上传至虚拟机,然后通过spark-submit提交任务
* spark-submit --class WordCount2 --master yarn-client spark-1.0.jar
* spark-submit --class WordCount2 --master yarn-cluster spark-1.0.jar
*/
object WordCount2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("WordCount2")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("/spark/data/words")
val wordsRDD: RDD[String] = linesRDD.flatMap(s=>s.split(","))
val groupRDD: RDD[(String, Iterable[String])] = wordsRDD.groupBy(s=>s)
val resRDD: RDD[String] = groupRDD.map(kv => {
kv._1 + "," + kv._2.size
})
// 使用HDFS的JAVA API判断输出路径是否已经存在,存在即删除
val conff: Configuration = new Configuration()
// core-site.xml
conff.set("fs.defaultFS", "hdfs://master:9000")
val sys = FileSystem.get(conff)
if (sys.exists(new Path("/spark/data/wordcount"))){
sys.delete(new Path("/spark/data/wordcount"),true)
}
resRDD.saveAsTextFile("/spark/data/wordcount")
}
}
打成jar包去运行
默认会有两个分区Task

可以通过sc.textFile(Path,分区个数)
on yarn的两种模式
yarn client模式:driverzai当前提交任务的节点上,可以打印任务运行的日志信息,而
yarn cluster模式:driver在AppMaster所有节点上,分布式分配,不能再提交任务的本机打印日志信息
Spark中的Wordcount的更多相关文章
- 006 Spark中的wordcount以及TopK的程序编写
1.启动 启动HDFS 启动spark的local模式./spark-shell 2.知识点 textFile: def textFile( path: String, minPartitions: ...
- Spark中的wordCount程序实现
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.s ...
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- 大话Spark(3)-一图深入理解WordCount程序在Spark中的执行过程
本文以WordCount为例, 画图说明spark程序的执行过程 WordCount就是统计一段数据中每个单词出现的次数, 例如hello spark hello you 这段文本中hello出现2次 ...
- Spark初步 从wordcount开始
Spark初步-从wordcount开始 spark中自带的example,有一个wordcount例子,我们逐步分析wordcount代码,开始我们的spark之旅. 准备工作 把README.md ...
- 【Spark篇】---Spark中Shuffle机制,SparkShuffle和SortShuffle
一.前述 Spark中Shuffle的机制可以分为HashShuffle,SortShuffle. SparkShuffle概念 reduceByKey会将上一个RDD中的每一个key对应的所有val ...
- intellij-idea打包Scala代码在spark中运行
.创建好Maven项目之后(记得添加Scala框架到该项目),修改pom.xml文件,添加如下内容: <properties> <spark.version></spar ...
- spark中的RDD以及DAG
今天,我们就先聊一下spark中的DAG以及RDD的相关的内容 1.DAG:有向无环图:有方向,无闭环,代表着数据的流向,这个DAG的边界则是Action方法的执行 2.如何将DAG切分stage,s ...
- Tachyon在Spark中的作用(Tachyon: Reliable, Memory Speed Storage for Cluster Computing Frameworks 论文阅读翻译)
摘要: Tachyon是一种分布式文件系统,能够借助集群计算框架使得数据以内存的速度进行共享.当今的缓存技术优化了read过程,可是,write过程由于须要容错机制,就须要通过网络或者 ...
随机推荐
- Vue2和Vue3技术整理3 - 高级篇
3.高级篇 前言 基础篇链接:https://www.cnblogs.com/xiegongzi/p/15782921.html 组件化开发篇链接:https://www.cnblogs.com/xi ...
- DOM Document.readyState 属性
感谢原文作者:MDN 原文地址:https://developer.mozilla.org/zh-CN/docs/Web/API/Document/readyState 描述 一个document 的 ...
- Webpack 多html入口、devServer、热更新配置
一.clean-webpack-plugin: 在每次生成dist目录前,先删除本地的dist文件(每次自动删除太麻烦) 1.安装clean-webpack-plugin npm/cnpm i c ...
- 随机数类 Random
import java.util.Random; /* 随机数类 Random 需求: 编写一个函数随机产生四位的验证码. */ public class Demo5 { public static ...
- ASP.NET Core 6框架揭秘实例演示[01]: 编程初体验
作为<ASP.NET Core 3框架揭秘>的升级版,<ASP.NET Core 6框架揭秘>提供了很多新的章节,同时对现有的内容进行大量的修改.虽然本书旨在对ASP.NET ...
- Spark算子 - aggregateByKey
释义 aggregateByKey逻辑类似 aggregate,但 aggregateByKey针对的是PairRDD,即键值对 RDD,所以返回结果也是 PairRDD,结果形式为:(各个Key, ...
- idea导入mavenJar、mavenWeb项目
两种项目都是一样的,都是maven项目,所以主要是找到pom.xml,项目最好先放在idea的工作目录下,且工作目录最好为英文 1.打开idea,选择import project 2.把项目放到ide ...
- pandas中常用的操作一
pandas中常用的功能: 1.显示所有的列的信息,999表示显示最大的列为999 pd.options.display.max_columns=999 2.读取excel时设置使用到列的名称,和列的 ...
- 37、python并发编程之协程
目录: 一 引子 二 协程介绍 三 Greenlet 四 Gevent介绍 五 Gevent之同步与异步 六 Gevent之应用举例一 七 Gevent之应用举例二 一 引子 本节的主题是基于单线程来 ...
- Solution -「HNOI 2009」「洛谷 P4727」图的同构计数
\(\mathcal{Description}\) Link. 求含 \(n\) 个点的无标号简单无向图的个数,答案模 \(997\). \(\mathcal{Solution}\) 首先 ...