reduceByKey和groupByKey区别与用法
在spark中,我们知道一切的操作都是基于RDD的。在使用中,RDD有一种非常特殊也是非常实用的format——pair RDD,即RDD的每一行是(key, value)的格式。这种格式很像Python的字典类型,便于针对key进行一些处理。
针对pair RDD这样的特殊形式,spark中定义了许多方便的操作,今天主要介绍一下reduceByKey和groupByKey,因为在接下来讲解《在spark中如何实现SQL中的group_concat功能?》时会用到这两个operations。
首先,看一看spark官网是怎么解释的:
reduceByKey(func, numPartitions=None)
Merge the values for each key using an associative reduce function. This will also perform the merginglocally on each mapper before sending results to a reducer, similarly to a “combiner” in MapReduce. Output will be hash-partitioned with numPartitions partitions, or the default parallelism level if numPartitions is not specified.
也就是,reduceByKey用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义。
groupByKey(numPartitions=None)
Group the values for each key in the RDD into a single sequence. Hash-partitions the resulting RDD with numPartitions partitions. Note: If you are grouping in order to perform an aggregation (such as a sum or average) over each key, using reduceByKey or aggregateByKey will provide much better performance.
也就是,groupByKey也是对每个key进行操作,但只生成一个sequence。需要特别注意“Note”中的话,它告诉我们:如果需要对sequence进行aggregation操作(注意,groupByKey本身不能自定义操作函数),那么,选择reduceByKey/aggregateByKey更好。这是因为groupByKey不能自定义函数,我们需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。
为了更好的理解上面这段话,下面我们使用两种不同的方式去计算单词的个数[2]:
- val words = Array("one", "two", "two", "three", "three", "three")
- val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
- val wordCountsWithReduce = wordPairsRDD.reduceByKey(_ + _)
- val wordCountsWithGroup = wordPairsRDD.groupByKey().map(t => (t._1, t._2.sum))
上面得到的wordCountsWithReduce和wordCountsWithGroup是完全一样的,但是,它们的内部运算过程是不同的。
(1)当采用reduceByKeyt时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合。借助下图可以理解在reduceByKey里究竟发生了什么。 注意在数据对被搬移前同一机器上同样的key是怎样被组合的(reduceByKey中的lamdba函数)。然后lamdba函数在每个区上被再次调用来将所有值reduce成一个最终结果。整个过程如下:
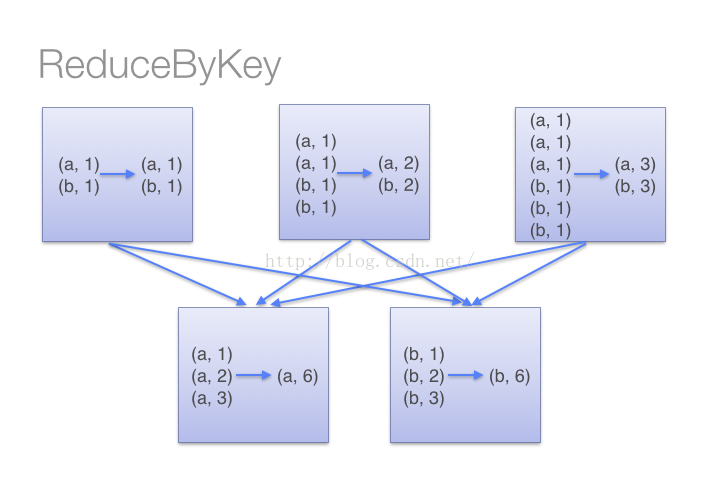
(2)当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对(key-value pair)都移动,这样的后果是集群节点之间的开销很大,导致传输延时。整个过程如下:
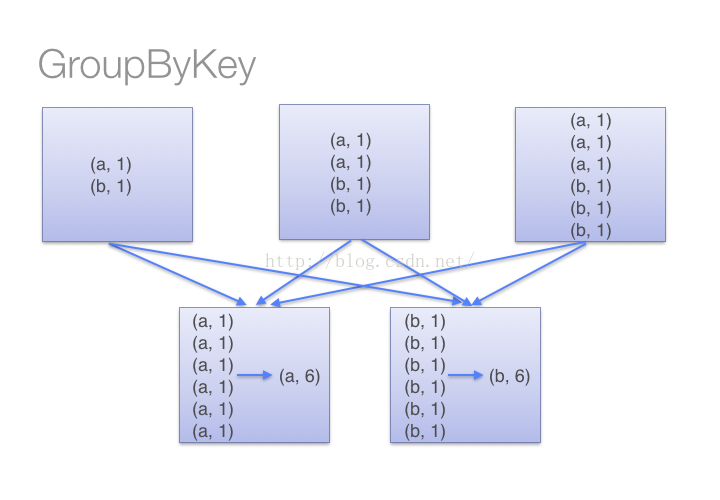
因此,在对大数据进行复杂计算时,reduceByKey优于groupByKey。
另外,如果仅仅是group处理,那么以下函数应该优先于 groupByKey :
(1)、combineByKey 组合数据,但是组合之后的数据类型与输入时值的类型不一样。
(2)、foldByKey合并每一个 key 的所有值,在级联函数和“零值”中使用。
最后,对reduceByKey中的func做一些介绍:
如果是用Python写的spark,那么有一个库非常实用:operator[3],其中可以用的函数包括:大小比较函数,逻辑操作函数,数学运算函数,序列操作函数等等。这些函数可以直接通过“from operator import *”进行调用,直接把函数名作为参数传递给reduceByKey即可。如下:
from operator import add
rdd = sc.parallelize([("a", ), ("b", ), ("a", )])
sorted(rdd.reduceByKey(add).collect())
[('a', ), ('b', )]</span>
转载:https://blog.csdn.net/zongzhiyuan/article/details/49965021
reduceByKey和groupByKey区别与用法的更多相关文章
- 转载-reduceByKey和groupByKey的区别
原文链接-https://www.cnblogs.com/0xcafedaddy/p/7625358.html 先来看一下在PairRDDFunctions.scala文件中reduceByKey和g ...
- reduceByKey和groupByKey的区别
先来看一下在PairRDDFunctions.scala文件中reduceByKey和groupByKey的源码 /** * Merge the values for each key using a ...
- spark:reducebykey与groupbykey的区别
从源码看: reduceBykey与groupbykey: 都调用函数combineByKeyWithClassTag[V]((v: V) => v, func, func, partition ...
- 【Spark算子】:reduceByKey、groupByKey和combineByKey
在spark中,reduceByKey.groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结: 我的代码实践:https://github.com/wwcom ...
- Position属性四个值:static、fixed、absolute和relative的区别和用法
Position属性四个值:static.fixed.absolute和relative的区别和用法 在用CSS+DIV进行布局的时候,一直对position的四个属性值relative,absolu ...
- Python中内置数据类型list,tuple,dict,set的区别和用法
Python中内置数据类型list,tuple,dict,set的区别和用法 Python语言简洁明了,可以用较少的代码实现同样的功能.这其中Python的四个内置数据类型功不可没,他们即是list, ...
- angularjs中provider,factory,service的区别和用法
angularjs中provider,factory,service的区别和用法 都能提供service,但是又有差别 service 第一次被注入时实例化,只实例化一次,整个应用的生命周期中是个单例 ...
- [转]div与span区别及用法
DIV与SPAN区别及div与san用法篇 接下来了解在div+css开发的时候在html网页制作,特别是标签运用中div和span的区别及用法.新手在使用web标准(div css)开发网页的时候, ...
- GROUP BY,WHERE,HAVING之间的区别和用法
GROUP BY,WHERE,HAVING之间的区别和用法 分类: Oracle学习2009-11-01 23:40 21963人阅读 评论(6) 收藏 举报 mathmanagersql数据库m ...
随机推荐
- HTML5中的data-*属性和jQuery中的.data()方法使用
原文地址链接:http://blog.csdn.net/fly_zxy/article/details/50687691: HTML5中的data-*属性 我们往往会根据需要在HTML标记上添加自定义 ...
- python学习 day01 基础介绍
一.编程的目的 1.什么是语言?编程语言又为何? 语言是一种事物与另外一种事物沟通的介质.编程语言是程序员和计算机沟通的介质. 2.什么是编程? 程序员把自己想要计算机做的事用编程语言表达出来,编程的 ...
- php优秀框架codeigniter学习系列——constants.php
该文件位于application/config/constants.php.
- linux 基本命令大全
系统信息 arch 显示机器的处理器架构(1) uname -m 显示机器的处理器架构(2) uname -r 显示正在使用的内核版本 dmidecode -q 显示硬件系统部件 - (SMBIOS ...
- 爬虫框架存储pymysql方式
爬虫框架存储pymysql方式# -*- coding: utf-8 -*-import pymysql# Define your item pipelines here## Don't forget ...
- wx小程序用canvas生成图片流程与注意事项
1.需要画入canvas的 图片都需要先缓存到本地 let ps = [] ps.push(that.loadImageFun(this.statusInfo.avatar_url, "he ...
- HDU 2585 Hotel(字符串的模糊匹配+递归)
Problem Description Last year summer Max traveled to California for his vacation. He had a great tim ...
- 【webdriver自动化】使用unittest实现自动登录163邮箱然后新建一个联系人
#练习:登录163邮箱然后新建一个联系人 import unittest import time from selenium import webdriver from selenium.webdri ...
- 【Python】unittest-5
#练习9: import unittest from selenium import webdriver import time class GloryRoad(unittest.TestCase): ...
- c++ 继承(二)
不能自动继承的成员函数 1.构造函数 2.析构函数 3.=运算符 继承与构造函数 1.基类的构造函数不被继承,派生类中需要声明自己的构造函数 2.声明构造函数时,只需要对本类中新增成员进行初始化,对继 ...