TensorRT入门
本文转载于:子棐之GPGPU 的 TensorRT系列入门篇 学习一下加深印象
Why TensorRT
训练对于深度学习来说是为了获得一个性能优异的模型,其主要的关注点在与模型的准确度、精度等指标。推理(inference)则不一样,其没有了训练中的反向迭代过程,是针对新的数据进行预测,而我们日常生活中使用的AI服务都是推理服务。相较于训练,推理的关注点不一样,从而也给现有的技术带来了新的挑战。
|
需求 |
现有框架的局限性 |
影响 |
|---|---|---|
| 高吞吐率 | 无法处理大量和高速的数据 | 增加了单次推理的开销 |
| 低响应时间 | 应用无法提供实时的结果 | 损害了用户体验(语音识别、个性化推荐和实时目标检测) |
| 高效的功耗以及显存消耗控制 | 非最优效能 | 增加了推理的开销甚至无法进行推理部署 |
| 部署级别的解决方案 | 非专用于部署使用 | 框架复杂度和配置增加了部署难度以及生产率 |
根据上图可知,推理更关注的是高吞吐率、低响应时间、低资源消耗以及简便的部署流程,而TensorRT就是用来解决推理所带来的挑战以及影响的部署级的解决方案。
TensorRT的部署流程

TensorRT的部署分为两个部分:
1. 优化训练好的模型并生成计算流图
2. 使用TensorRT Runtime部署计算流图
那么我们很自然的就会想到下面几个问题?
1. TensorRT支持什么框架训练出来的网络模型呢?
2. TensorRT支持什么网络结构呢?
3. TensorRT优化器做了哪些优化呢?
4. TensorRT优化好的计算流图可以运行在什么设备上呢?
TensorRT的神通

输入篇之网络框架:TensorRT3支持所有常见的深度学习框架包括Caffe、Tensorflow、Pytorch、MXnet、PaddlePaddle、Theano等
输入篇之网络层:TensorRT3支持的网络层包括
|
Convolution LSTM and GRU Activation: ReLU, tanh, sigmoid Pooling: max and average Scaling ElementWise LRN Fully-connected SoftMax Deconvolution |
Concatenation Flatten Padding Plugin RNN: RNN, GRU, LSTM Scale Shuffle Softmax Squeeze Unary |
输入篇之接口方式:TensorRT3 支持模型导入方式包括C++ API、Python API、NvCaffeParser和NvUffParser
输出篇之支持的系统平台:TensorRT3支持的平台包括Linux x86、Linux aarch64、Android aarch64和QNX aarch64
输出篇之支持的硬件平台:TensorRT3可以运行在每一个GPU平台,从数据中心的Tesla P4/V100到自动驾驶和嵌入式平台的DrivePX及TX1/TX2
TensorRT模型导入流程
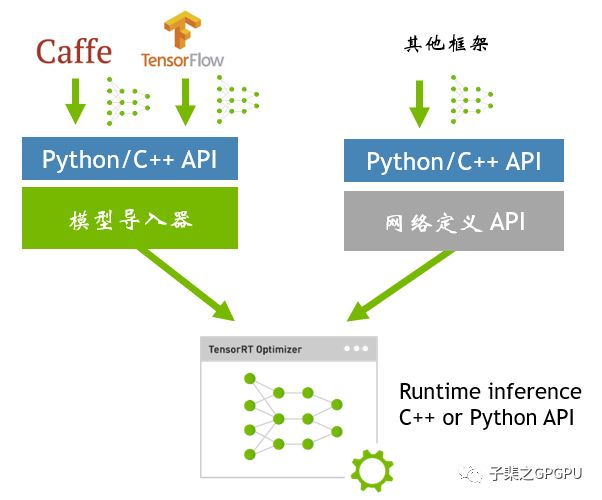
如上图所示,模型导入方法可以根据框架种类分成三种:Caffe、Tensorflow和其他
caffe
1. 使用C++/Python API导入模型:通过代码定义网络结构,并载入模型weights的方式导入;
2. 使用NvCaffeParser导入模型:导入时输入网络结构prototxt文件及caffemodel文件即可
Tensorflow
1. 训练完成后,使用uff python接口将模型转成uff格式,之后使用NvUffParser导入;
2. 对于Tensorflow或者keras的,利用Freezegraph来生成.pb(protobuf)文件,之后使用convert-to-uff工具将.pb文件转化成uff格式,然后利用NvUffParser导入
其他框架
使用C++/Python API导入模型:通过代码定义网络结果,载入模型weights的方式导入。以Pytorch为例,在完成训练后,通过stat_dict()函数获取模型的weights,从而定义网络结构时将weights载入
TensorRT优化细节
网络模型在导入至TensorRT后会进行一系列的优化,主要优化内容如下图所示
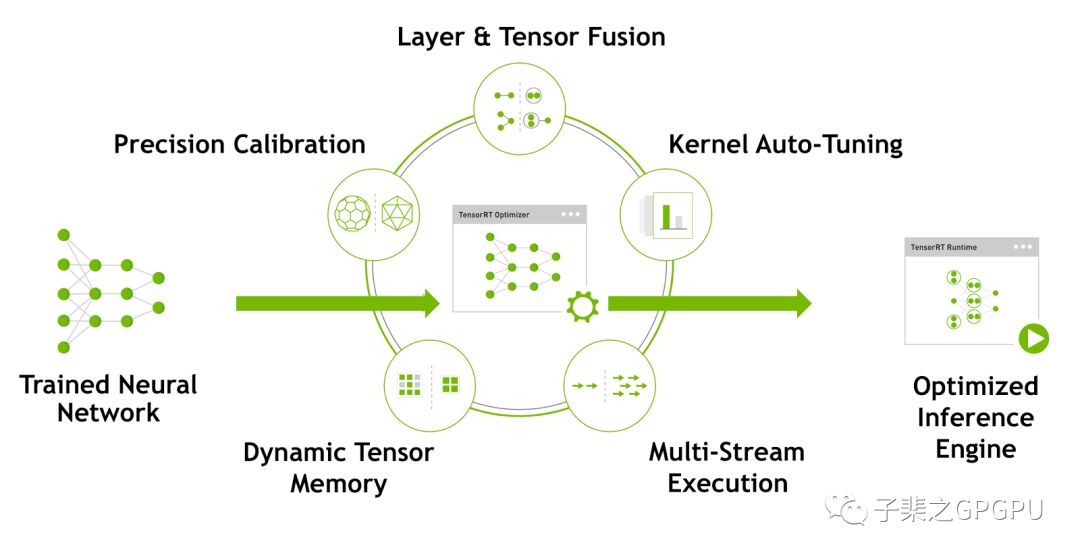
TensorRT在获得网络结算流图后会针对计算流图进行优化,这部分优化不会改变图中最底层的计算内容,而是会去重构计算图来获得更快更高效的执行方式,即计算不变,优化计算方法。
以下图为例:

深度学习框架在做推理时,会对每一层调用多个/次功能函数。而由于这样的操作都是在GPU上运行的,从而会带来多次的CUDA Kernel launch过程。相较于Kernel launch以及每层tensor data读取来说,kernel的计算是更快、更轻量的,从而使得这个程序受限于显存带宽并损害了GPU利用率。
TensorRT通过以下三种方式来解决这个问题:
Kernel纵向融合:通过融合相同顺序的操作来减少Kernel Launch的消耗以及避免层之间的显存读写操作。如上图所示,卷积、Bias和Relu层可以融合成一个Kernel,这里称之为CBR。
Kernel横向融合:TensorRT会去挖掘输入数据且filter大小相同但weights不同的层,对于这些层不是使用三个不同的Kernel而是使用一个Kernel来提高效率,如上图中超宽的1x1 CBR所示。
消除concatenation层,通过预分配输出缓存以及跳跃式的写入方式来避免这次转换。
通过这样的优化,TensorRT可以获得更小、更快、更高效的计算流图,其拥有更少层网络结构以及更少Kernel launch次数。下表列出了常见几个网络在TensorRT优化后的网络层数量,很明显的看到TensorRT可以有效的优化网络结构、减少网络层数从而带来性能的提升。
| Network | Layers | Layers after fusion |
|---|---|---|
| VGG19 | 43 | 27 |
| Inception V3 | 309 | 113 |
| ResNet-152 | 670 | 159 |
FP16 & INT 8精度校准
大多数的网络都是使用FP32进行模型训练,因此模型最后的weights也是FP32格式。但是一旦完成训练,所有的网络参数就已经是最优的,在推理过程中无需进行反向迭代,因此可以在推理中使用FP16或者INT8精度计算从而获得更小的模型。低的显存占用率和延迟以及更高的吞吐率。
TensorRT可以采用FP32、FP16和INT8精度部署模型,只需要在uff_to_trt_engine函数中指定相应数据类型即可:
对于FP32,使用trt.infer.DataType.FLOAT
对于FP16指令以及Volta GPU内的Tensor Cores,使用trt.infer.DataType.HALF
对于INT8,使用trt.infer.DataType.INT8
Kernel Auto-Tuning
TensorRT会针对大量的Kernel进行参数优化和调整。例如说,对于卷积计算有若干种算法,TensorRT会根据输入数据大小、filter大小、tensor分布、batch大小等等参数针对目标平台GPU进行选择和优化。
Dynamic Tensor Memory
TensorRT通过为每一个tensor在其使用期间设计分配显存来减少显存的占用,增加显存的复用率,从而避免了显存的过度开销以获得更快和更高效的推理性能。
优化结果如图所示
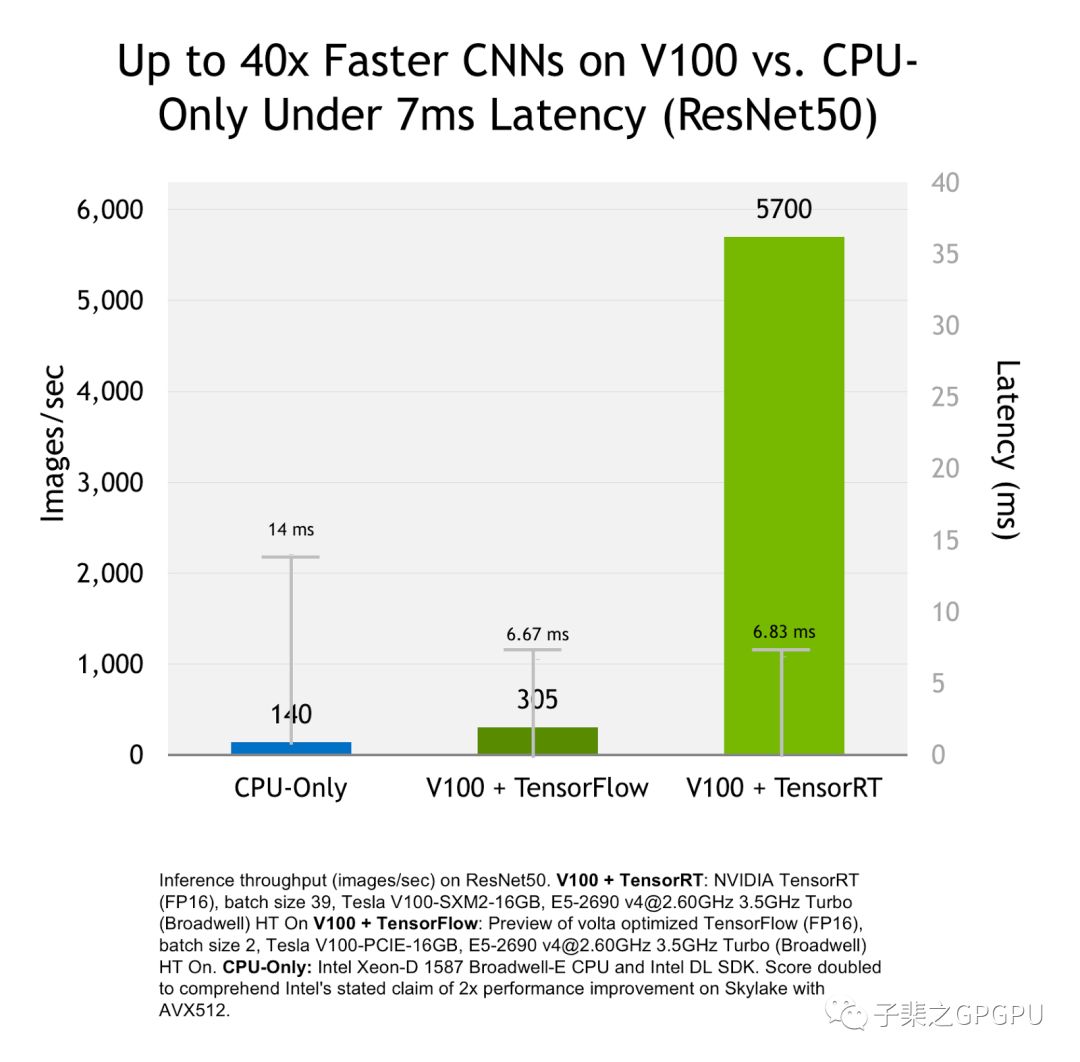
上图为基于Resnet50网络,分别在CPU、V100+Tensorflow、V100+TensorRT上进行推理时的性能比较,纵轴为每秒处理的图片数量。想较于CPU和Tensorflow,TensorRT可以带来40倍和18倍的吞吐率的提升,而这部分的提升只需要在拥有GPU的前提下使用TensorRT即可免费获得。
TensorRT部署方法
完成TensorRT优化后可以得到一个Runtime inference engine,这个文件可以被系列化保存至硬盘中,而这个保存的序列化文件我们称之为"Plan"(流图),之所以称之为流图,因为其不仅保存了计算时所需的网络weights也保存了Kernel执行的调度流程。TensorRT提供了write_engine_to_file()函数来保存流图。
在获得流图之后就可以使用TensorRT部署应用。为了进一步的简化部署流程,TensorRT提供了TensorRT Lite API,它是高度抽象的接口会自动处理大量的重复的通用任务例如创建一个Logger、反序列化流图并生成Runtime inference engine、处理输入的数据。以下代码提供了一个使用TensorRT Lite API的范例教程,只需使用API创建一个Runtime Engine即可完成前文提到的通用任务,之后将需要推理的数据载入并送入Engine即可推理。
from tensorrt.lite import Engine
from tensorrt.infer import LogSeverity
import tensorrt
# Create a runtime engine from plan file using TensorRT Lite API
engine_single = Engine(PLAN="keras_vgg19_b1_FP32.engine",
postprocessors={"dense_2/Softmax":analyze})
images_trt, images_tf = load_and_preprocess_images()
results = []
for image in images_trt:
result = engine_single.infer(image) # Single function for inference
results.append(result)
TensorRT3带来的三个重大更新:
TensorFlow Model Importer - 便捷的API用于导入TensorFLow训练的模型,优化并生成推理Engine。
Python API - Python API用于进一步提高开发效率。
Volta Tensor Core支持 - 带来相较于Tesla P100高达3.7倍的更快的推理性能。
TensorRT入门的更多相关文章
- Attention Mechanism in Computer Vision
前言 本文系统全面地介绍了Attention机制的不同类别,介绍了每个类别的原理.优缺点. 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结.最新技术跟踪.经典论文解读.CV招聘信息. 概 ...
- CV技术指南免费版知识星球
最近公众号的交流群满了,我们决定搞一个免费的知识星球,让大家在里面交流.以往都是我们写原创,大家阅读,读者之间没什么交流.与此同时,在CV技术指南交流群里,大部分问题都得到了很好地解决,但从来没有 ...
- YOLO系列梳理(三)YOLOv5
前言 YOLOv5 是在 YOLOv4 出来之后没多久就横空出世了.今天笔者介绍一下 YOLOv5 的相关知识.目前 YOLOv5 发布了新的版本,6.0版本.在这里,YOLOv5 也在5.0基 ...
- EdgeFormer: 向视觉 Transformer 学习,构建一个比 MobileViT 更好更快的卷积网络
前言 本文主要探究了轻量模型的设计.通过使用 Vision Transformer 的优势来改进卷积网络,从而获得更好的性能. 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结.最新技术跟 ...
- NMS技术总结(NMS原理、多类别NMS、NMS的缺陷、NMS的改进思路、各种NMS方法)
前言 本文介绍了NMS的应用场合.基本原理.多类别NMS方法和实践代码.NMS的缺陷和改进思路.介绍了改进NMS的几种常用方法.提供了其它不常用的方法的链接. 本文很早以前发过,有个读者评论说 ...
- 从零搭建Pytorch模型教程(四)编写训练过程--参数解析
前言 训练过程主要是指编写train.py文件,其中包括参数的解析.训练日志的配置.设置随机数种子.classdataset的初始化.网络的初始化.学习率的设置.损失函数的设置.优化方式的设置. ...
- 基于TensorRT优化的Machine Translation
基于TensorRT优化的Machine Translation 机器翻译系统用于将文本从一种语言翻译成另一种语言.递归神经网络(RNN)是机器翻译中最流行的深度学习解决方案之一. TensorRT机 ...
- Recommenders with TensorRT
Recommenders with TensorRT 推荐系统用于向社交网络.媒体内容消费和电子商务平台的用户提供产品或媒体推荐.基于MLP的神经协作滤波器(NCF)推荐器使用一组完全连接或矩阵乘法层 ...
- NVIDIA TensorRT高性能深度学习推理
NVIDIA TensorRT高性能深度学习推理 NVIDIA TensorRT 是用于高性能深度学习推理的 SDK.此 SDK 包含深度学习推理优化器和运行时环境,可为深度学习推理应用提供低延迟和高 ...
随机推荐
- String、StringBuffer、StringBuilder葫芦三兄弟
今年因为疫情的原因,本打算在读研期间好好做项目,写论文,在今年9月份能找个好工作,但现在迟迟不能开学,也无法正常的给导师打工,所以干脆就打算好好准备工(fan)作(wan)的事儿. 接触Java也有好 ...
- MySQL学习之路7-索引、事务、函数、存储过程、游标
索引 使用索引快速定位某列中特定值的行,不需要遍历数据表所有行. 创建索引的数据结构:BTREE and HASH. 主键也是一种索引,Primary key. show index from ord ...
- Git应用详解第五讲:远程仓库Github与Git图形化界面
前言 前情提要:Git应用详解第四讲:版本回退的三种方式与stash 这一节将会介绍本地仓库与远程仓库的一些简单互动以及几款常用的Git图形化界面,让你更加方便地使用git. 一.Git裸库 简单来说 ...
- winform怎么实现财务上凭证录入和打印
序言 现如今存在的财务软件层出不穷,怎么样让自己的业务系统与财务系统相结合,往往是很多公司头痛的问题.大多数公司也没有这个能力都去开发一套属于自己的财务软件,所以只有对接像金蝶用友这类的财务软件,花费 ...
- centos7安装puppet详细教程(简单易懂,小白也可以看懂的教程)
简介: Puppet是一种linux.unix平台的集中配置管理系统,使用ruby语言,可配置文件.用户.cron任务.软件包.系统服务等.Puppet把这些系统实体称之为资源,它的设计目标是简化对这 ...
- 记一次pgsql中查询优化(子查询)
记一次pgsql的查询优化 前言 这是一个子查询的场景,对于这个查询我们不能避免子查询,下面是我一次具体的优化过程. 优化策略 1.拆分子查询,将需要的数据提前在cte中查询出来 2.连表查询,直接去 ...
- 如何使用python,才能像人民日报的“点亮”武汉景点
如何使用python,才能像人民日报的“点亮”武汉景点 前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:Allen P ...
- stand up meeting 12/24/2015 && end sprint1
part 组员 工作 工作耗时/h 明日计划 工作耗时/h UI 冯晓云 解决单词本显示页面的问题 4 完善显示页面的功能 4 ...
- Maven+JSP+Servlet+JDBC+Redis+Mysql实现的黑马旅游网
项目简介 项目来源于:https://gitee.com/haoshunyu/travel 本系统是基于Maven+JSP+Servlet+JdbcTemplate+Redis+Mysql实现的旅游网 ...
- [V&N2020 公开赛]TimeTravel 复现
大佬友链(狗头):https://www.cnblogs.com/p201821440039/ 参考博客: https://www.zhaoj.in/read-6407.html https://cj ...