Spark基础:(二)Spark RDD编程
1、RDD基础
Spark中的RDD就是一个不可变的分布式对象集合。每个RDD都被分为多个分区,这些分区运行在分区的不同节点上。
用户可以通过两种方式创建RDD:
(1)读取外部数据集====》 sc.textFile(inputfile)
(2)驱动器程序中对一个集合进行并行化===》sc.parallelize(List(“pandas”,”I like pandas”))
2、RDD操作
转化(Transformations)和行动*(Actions)操作
(1):转化操作
RDD 经过转化返回一个新的RDD,转化出来的RDD是惰性求值的,只有在行动操作才会进行计算的。
常见的转换操作如下图:
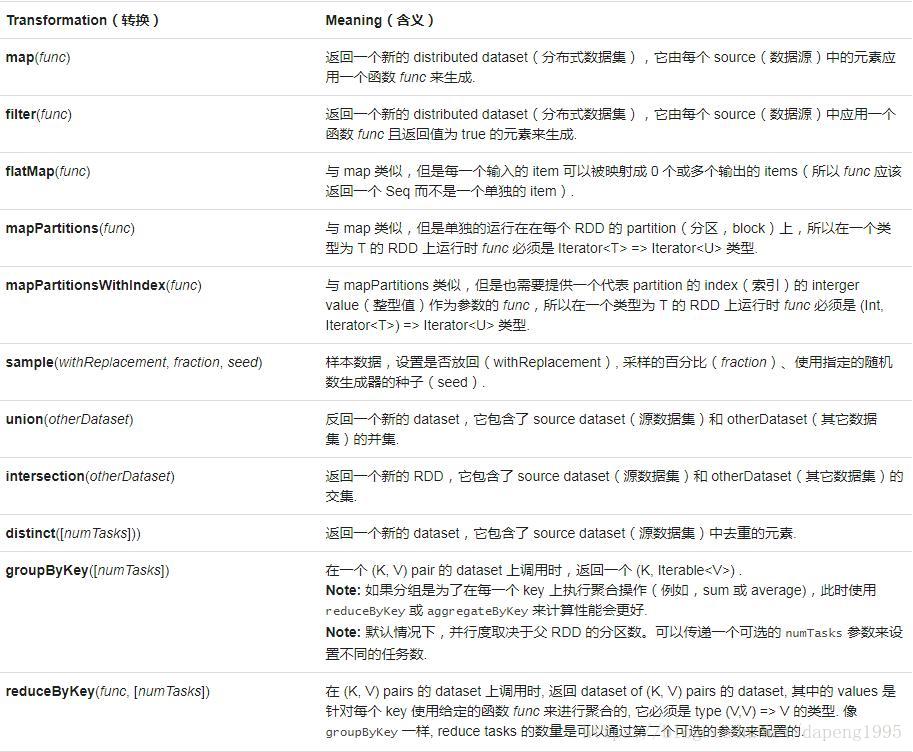
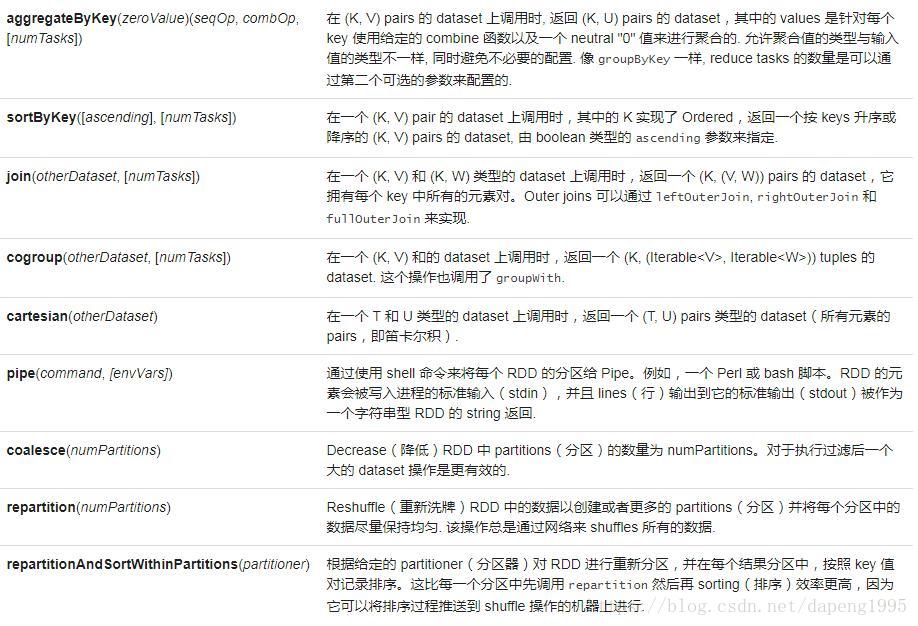
(2):行动操作
对数据集进行实际的计算,这最终求得的结果返回驱动器程序中,或者写入外部程序中。
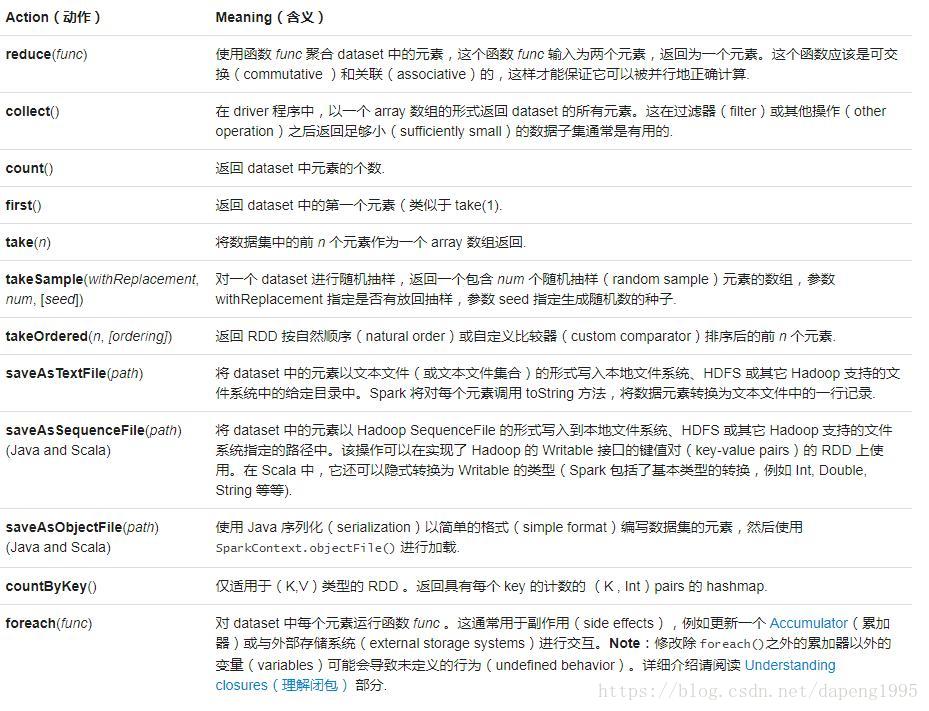
下表列出了一些 Spark 常用的 actions 操作
简单worldcount操作实现
object WordCountScala {
def main(args: Array[String]): Unit = {
//创建Spark配置对象
val conf = new SparkConf();
conf.setAppName("WordCountScala")
//设置master属性
//conf.setMaster("local");
conf.setMaster("local[*]")
//通过conf创建sc
val sc = new SparkContext(conf);
print("hello world");
//加载文本文件
val rdd1 = sc.textFile("F:/spark/b.txt");
//压扁
val rdd2 = rdd1.flatMap(line => {
println("map :"+line)
line.split(" ")
}) ;
//映射w => (w,1)
val rdd3 = rdd2.map(word=>{
println("map :"+word)
(word,1)
})
val rdd4 = rdd3.reduceByKey(_ + _)
val r = rdd4.collect()
r.foreach(println)
}
}3、RDD的持久化
因为Spark RDD是惰性求值的,有时候我们希望能够多次使用同一个RDD。如果简单的对RDD调用行动操作,Spark会重算RDD以及它的所有的依赖。造成算法的开销很大。处于不同的目的,我们可以为RDD选择不同的持久化级别。RDD 可以使用 persist() 方法或 cache() 方法进行持久化。数据将会在第一次 action 操作时进行计算,并缓存在节点的内存中。Spark 的缓存具有容错机制,如果一个缓存的 RDD 的某个分区丢失了,Spark 将按照原来的计算过程,自动重新计算并进行缓存。默认的存储级别是 StorageLevel.MEMORY_ONLY(将反序列化的对象存储到内存中) ,如果您想手动删除 RDD 而不是等待它掉出缓存,使用 RDD.unpersist() 方法。

例如: Scala中的两次执行
val result=input.map(x=>x*x)
result.persist(StorageLevel.DISK_ONLY)
println(result.count())
println(result.collect().mkString(","))Spark基础:(二)Spark RDD编程的更多相关文章
- 大数据入门第二十二天——spark(二)RDD算子(1)
一.RDD概述 1.什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的 ...
- 大数据入门第二十二天——spark(二)RDD算子(2)与spark其它特性
一.JdbcRDD与关系型数据库交互 虽然略显鸡肋,但这里还是记录一下(点开JdbcRDD可以看到限制比较死,基本是鸡肋.但好在我们可以通过自定义的JdbcRDD来帮助我们完成与关系型数据库的交互.这 ...
- 【Spark基础】:RDD
我的代码实践:https://github.com/wwcom614/Spark 1.RDD是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式 ...
- 什么是spark(二) RDD
其实你会发现很多概念都是基于RDD提出来的,比如分区,缓存这些操作的对象其实都是RDD:所以不要讲spark的分区,这其实很不专业,分区其实是属于RDD的概念(只有pair RDD才有分区概念) RD ...
- spark(2.2) - spark-shell RDD编程
[基本操作] 1* 从文件系统中加载数据创建RDD -> 本地文件系统 ->HDFS 2* 转换操作 [ 会创建新的RDD ,没有真正计算 ] >> filter() > ...
- Spark 基础操作
1. Spark 基础 2. Spark Core 3. Spark SQL 4. Spark Streaming 5. Spark 内核机制 6. Spark 性能调优 1. Spark 基础 1. ...
- spark入门(二)RDD基础操作
1 简述 spark中的RDD是一个分布式的元素集合. 在spark中,对数据的所有操作不外乎创建RDD,转化RDD以及调用RDD操作进行求值,而这些操作,spark会自动将RDD中的数据分发到集群上 ...
- Spark菜鸟学习营Day1 从Java到RDD编程
Spark菜鸟学习营Day1 从Java到RDD编程 菜鸟训练营主要的目标是帮助大家从零开始,初步掌握Spark程序的开发. Spark的编程模型是一步一步发展过来的,今天主要带大家走一下这段路,让我 ...
- Spark学习之RDD编程总结
Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称 RDD).RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外 ...
随机推荐
- MVC下垃框的使用
--------------模型-------------------- /// <summary> /// 状态 /// =0 下架 =1 上架 /// </summary> ...
- Mysql 5.7 集群部署,keepalived
参考文章: https://blog.csdn.net/f18770366447/article/details/80703347 https://www.cnblogs.com/benjamin77 ...
- kvm 安装 windows 虚拟机
作者:SRE运维博客 博客地址: https://www.cnsre.cn/ 文章地址:https://www.cnsre.cn/posts/211108848062/ 相关话题:https://ww ...
- 小入门 Django(做个疫情数据报告)
Django 是 Python web框架,发音 [ˈdʒæŋɡo] ,翻译成中文叫"姜狗". 为什么要学框架?其实我们自己完全可以用 Python 代码从0到1写一个web网站, ...
- Bootstrap-2栅格系统
栅格系统(使用最新版本bootstrap) Grid options(网格配置) Responsive classes(响应式class) Gutters(间距) Alignment(对齐方式) Re ...
- thread pool
thread pool import concurrent.futures import urllib.request URLS = ['http://www.foxnews.com/', 'http ...
- airflow 安装问题
sasl Debian/Ubuntu: apt-get install python-dev libsasl2-dev gcc CentOS/RHEL: yum install gcc-c++ pyt ...
- MyBatis 中为什么不建议使用 where 1=1?
最近接手了一个老项目,"愉悦的心情"自然无以言表,做开发的朋友都懂,这里就不多说了,都是泪... 接手老项目,自然是要先熟悉一下业务代码,然而在翻阅 mapper 文件时,发现 ...
- Python基础(条件判断)
# age = 103 # if age < 90: # print('%s小于90' %age) # elif age > 90 and age < 95: # print('%s ...
- JS表格显示时间格式
<!-- JS代码区 --> <script type='text/javascript'> $(function() { var grid_selector23 = &quo ...