Flink sql 之 两阶段聚合与 TwoStageOptimizedAggregateRule(源码分析)
本文源码基于flink1.14
上一篇文章分析了《flink的minibatch微批处理》的源码
乘热打铁分析一下两阶段聚合的源码,因为使用两阶段要先开启minibatch,至于为什么后面会分析到
两阶段聚合的原理,还是简单提一下
如下图,当聚合发生热点的时候,可以在聚合前,先进行一个本地的聚合,先减小数据量,后接正常的数据交换以后聚合,来达到一个解热点的目的,
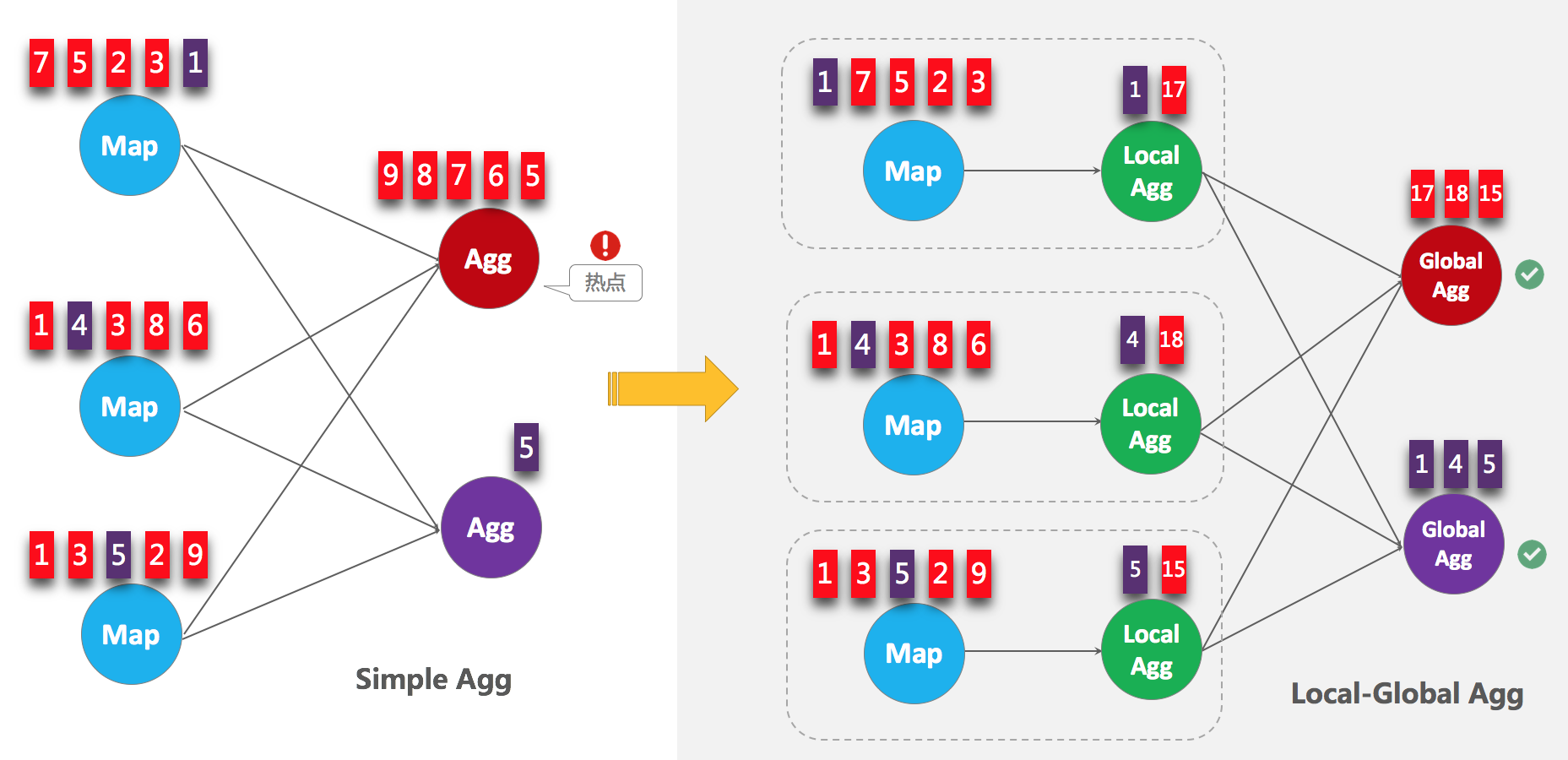
先来看下两阶段聚合的Calcite优化rule

看下什么情况会匹配上

并且在onmatch方法中会判断开启了minibatch,以及二阶段聚合的时候会调用
来看下具体逻辑match方法
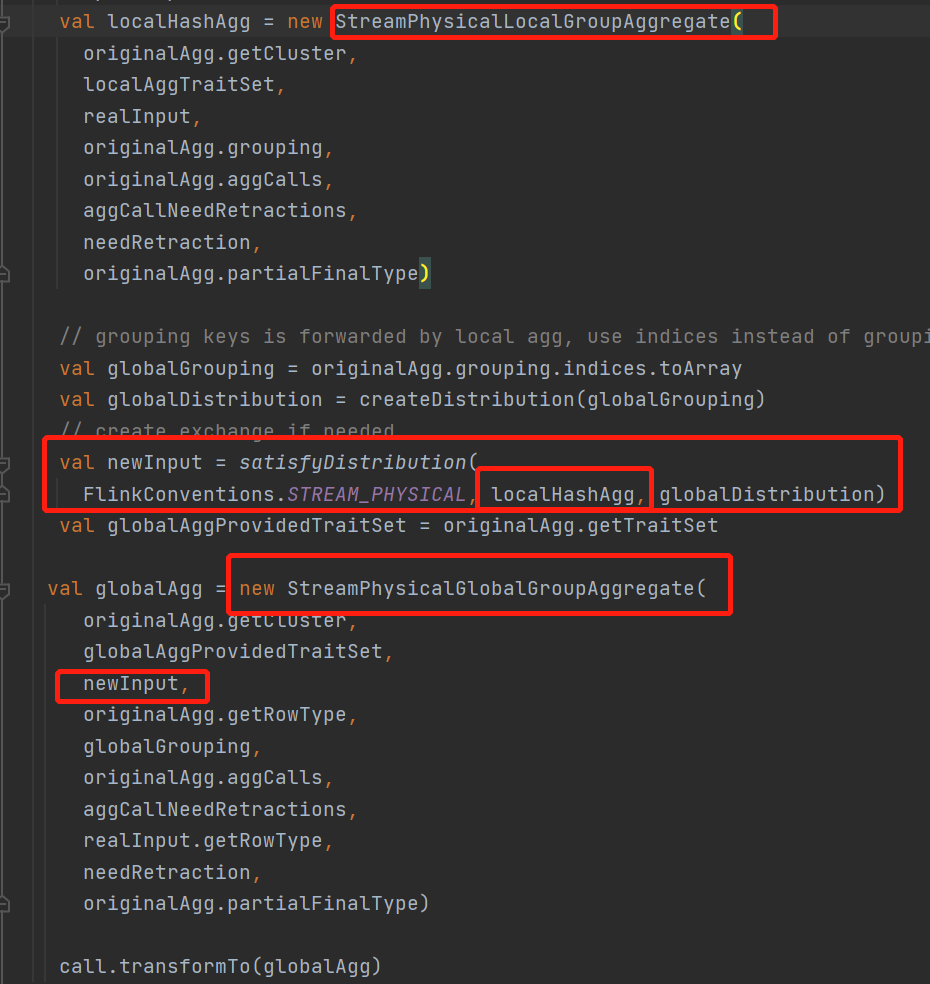
整个两阶段聚合会将原来的一个StreamPhysicalGroupAggregate物理节点,转换成一个
StreamPhysicalLocalGroupAggregate本地聚合节点 + StreamPhysicalGlobalGroupAggregate聚合节点
来看下这个新添加的StreamPhysicalLocalGroupAggregate本地聚合算子的计算逻辑是什么样子的
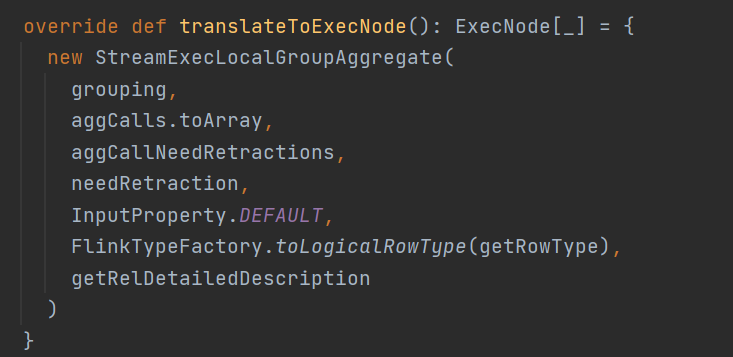
StreamExecLocalGroupAggragate就是StreamPhysicalLocalGroupAggregate本地聚合具体的ExecNode节点了
来看下具体的operator
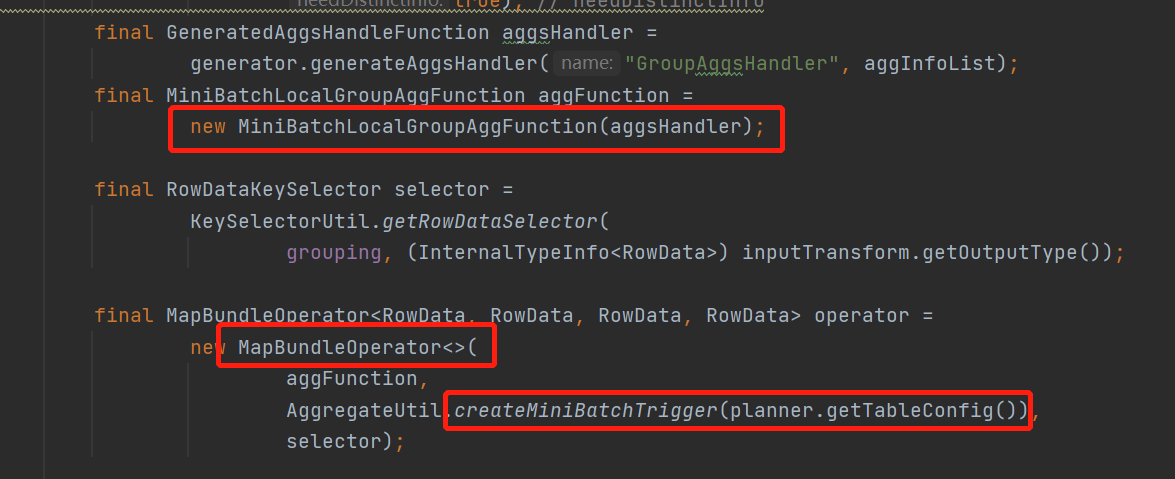
看到这里是不是看到了熟悉的 MapBundleOperator ,如果看过上一篇minibatch优化的就知道,两阶段提交也是使用的这个有界operator作为抽象
在了解一下这个MapBundleOperator
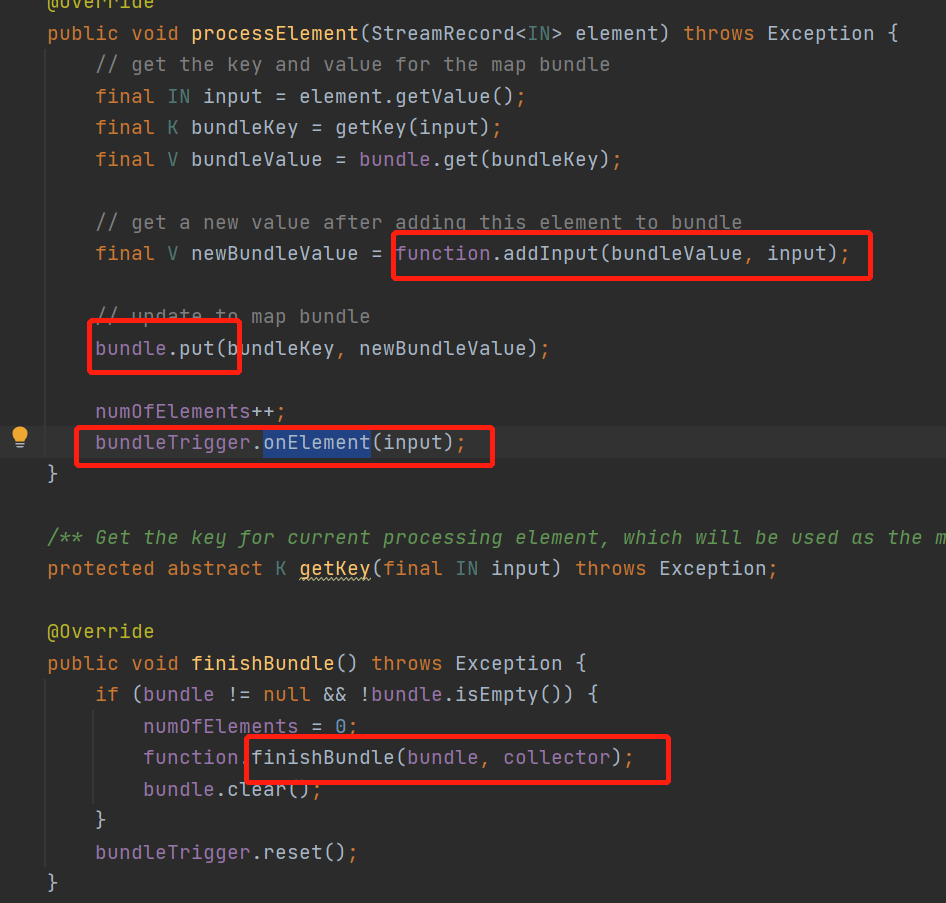
就是每来一条数据,都会调用传入的fun的addInput方法
然后把每个key的结果put保存在一个本地变量,就是个map<Rowdata,Rowdata>里面
然后调用自己的trigger触发器,当这条数据可以触发触发器就会调用finishBundle
这里说到触发器,回到初始化mapBundle的时候通过createMiniBatchTrigger创建的一个minibatch的触发器,看看具体逻辑
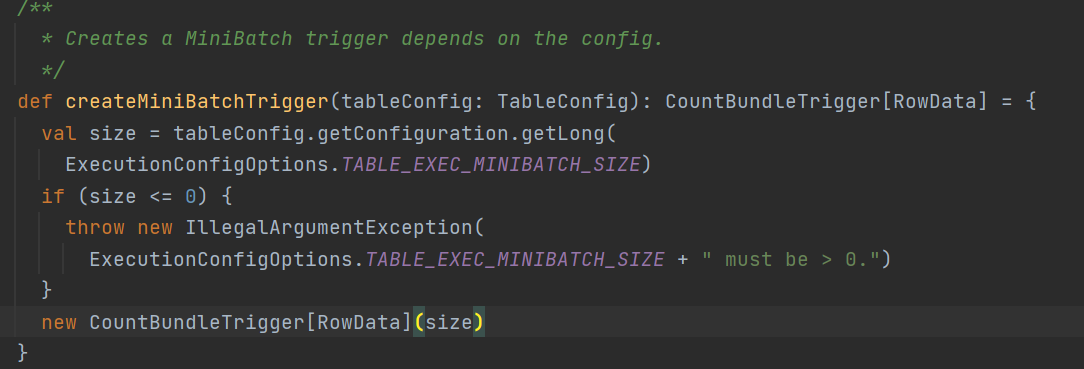
其实就是一个普通的count触发器,触发条件就是直接使用的minibatch配置的size参数, 所以这里知道了为什么两阶段提交要先开minibatch了
先看下每来一条数据会触发的addInput方法,在来看看攒一个批次后触发的finishBundle
minibatch会包装成一个MiniBatchLocalGroupAggFunction这个funtion的addInput来看看
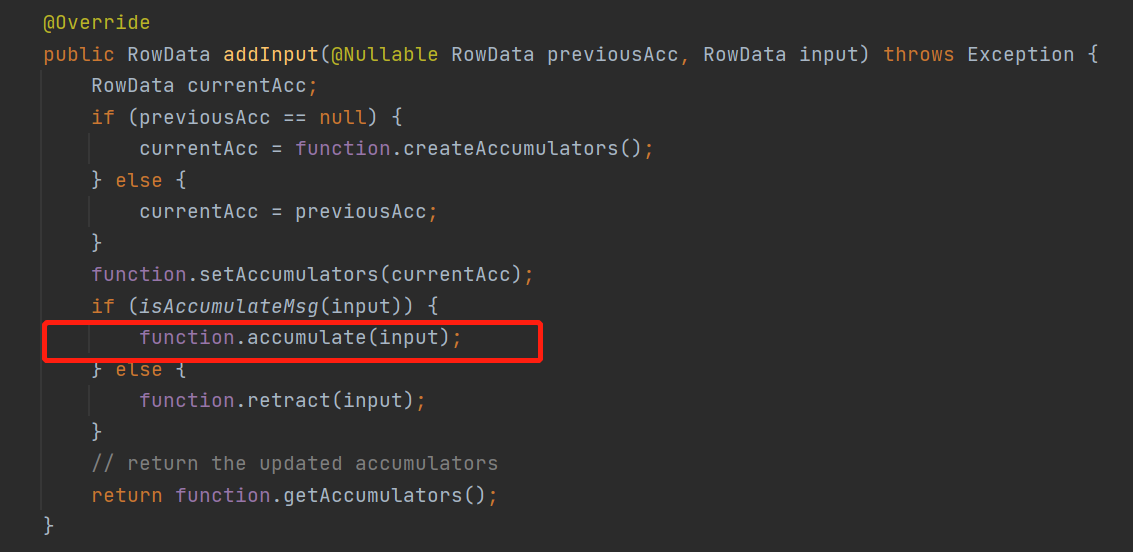
就是来一条数据直接调用聚合函数的accumulate直接计算结果了,虽然计算结果但是还没有往下游发送
来看下当攒一批后,集体是怎么往下游发送的 finishBundle 方法
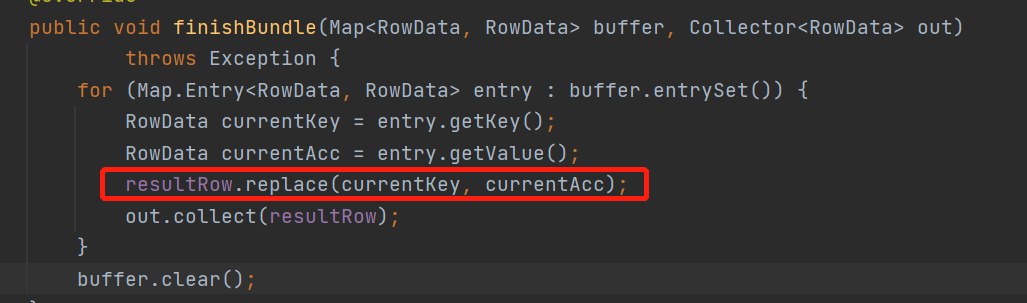
结果都已经计算好了,攒一个批次还能干嘛,就是把当前的计算结果往下游发送呗
那整个二次聚合的优化就讲完了
总结一下
sql会将agg拆成 localminiagg + agg
先在本地聚合localConbine一遍,再往下游发送
下游就正常聚合,优化了热点的问题
Flink sql 之 两阶段聚合与 TwoStageOptimizedAggregateRule(源码分析)的更多相关文章
- 从flink-example分析flink组件(3)WordCount 流式实战及源码分析
前面介绍了批量处理的WorkCount是如何执行的 <从flink-example分析flink组件(1)WordCount batch实战及源码分析> <从flink-exampl ...
- Flink Sql 之 Calcite Volcano优化器(源码解析)
Calcite作为大数据领域最常用的SQL解析引擎,支持Flink , hive, kylin , druid等大型项目的sql解析 同时想要深入研究Flink sql源码的话calcite也是必备 ...
- Flink 如何通过2PC实现Exactly-once语义 (源码分析)
Flink通过全局快照能保证内部处理的Exactly-once语义 但是端到端的Exactly-once还需要下游数据源配合,常见的通过幂等或者二阶段提交这两种方式保证 这里就来分析一下Sink二阶段 ...
- Flink中接收端反压以及Credit机制 (源码分析)
先上一张图整体了解Flink中的反压 可以看到每个task都会有自己对应的IG(inputgate)对接上游发送过来的数据和RS(resultPatation)对接往下游发送数据, 整个反压机制通 ...
- Flink中TaskManager端执行用户逻辑过程(源码分析)
TaskManager接收到来自JobManager的jobGraph转换得到的TDD对象,启动了任务,在StreamInputProcessor类的processInput()方法中 通过一个whi ...
- [源码分析] 带你梳理 Flink SQL / Table API内部执行流程
[源码分析] 带你梳理 Flink SQL / Table API内部执行流程 目录 [源码分析] 带你梳理 Flink SQL / Table API内部执行流程 0x00 摘要 0x01 Apac ...
- 鸿蒙内核源码分析(Shell编辑篇) | 两个任务,三个阶段 | 百篇博客分析OpenHarmony源码 | v71.01
子曰:"我非生而知之者,好古,敏以求之者也." <论语>:述而篇 百篇博客系列篇.本篇为: v71.xx 鸿蒙内核源码分析(Shell编辑篇) | 两个任务,三个阶段 ...
- [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版)
[源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码生成 (修订版) 目录 [源码分析]从"UDF不应有状态" 切入来剖析Flink SQL代码 ...
- Flink sql 之AsyncIO与LookupJoin的几个疑问 (源码分析)
本文源码基于flink 1.14 被同事问到几个关于AsyncIO和lookUp维表的问题所以翻了下源码,从源码的角度解惑这几个问题 对于AsyncIO不了解的可以看看之前写的这篇 <Flin ...
随机推荐
- Synchronized深度解析
概览: 简介:作用.地位.不控制并发的影响 用法:对象锁和类锁 多线程访问同步方法的7种情况 性质:可重入.不可中断 原理:加解锁原理.可重入原理.可见性原理 缺陷:效率低.不够灵活.无法预判是否成功 ...
- 【C/C++】C++ warning: control reaches end of non-void function return
控制到达非void函数的结尾. 一些本应带有返回值的函内数到容达结尾后可能并没有返回任何值. 这时候,最好检查一下是否每个控制流都会有返回值. 我是ostream声明的时候没有写return out; ...
- 从一次解决Nancy参数绑定“bug”开始发布自己的第一个nuget包(上篇)
起因 最近,同事跟我说,他们负责的一个Api程序出现了一些很奇怪的事情.这个Api是为环保局做的一个扬尘质控大屏提供数据的,底层是基于Nancy做的.因为发现有些接口的数据出现异常,他就去调试了一下, ...
- Mysql资料 锁机制
目录 一.简介 二.类型 三.操作 四.死锁 第一种情况 第二种情况 第三种情况 一.简介 数据库和操作系统一样,是一个多用户使用的共享资源.当多个用户并发地存取数据 时,在数据库中就会产生多个事务同 ...
- ubuntu 10.04安装和配置Samba
1. 安装samba服务器 sudo apt-get install samba //主程序包 sudo apt-get install smbfs //文件下载挂载工具 2. 创建共享目录 mk ...
- ciscn_2019_s_4***(栈迁移)
这是十分经典的栈迁移题目 拿到题目例行检查 32位程序开启了nx保护 进入ida,发现了很明显的system 我们进入main函数查看vul 可以看到溢出的部分不够我们rop所以这道题通过栈迁移去做 ...
- 日程选项卡的设置(Project)
<Project2016 企业项目管理实践>张会斌 董方好 编著 在使用任何一个软件之前,都有一些默认的东东要改,比如在Excel里有人不待见单元格里的0,一定要设置成不显示零值:在Wor ...
- LuoguB2044 有一门课不及格的学生 题解
Content 给出一名学生的语数英三门成绩,请判断该名学生是否恰好有一门不及格(成绩小于 \(60\) 分). 数据范围:成绩在 \(0\sim 100\) 之间. Solution 强烈建议先去做 ...
- java 数据类型String 【正则表达式】匹配
1,什么是正则表达式 正则表达式是用来处理字符串的,其实正则表达式是非常复杂的,专门去系统学习需要花很长的时间,我们课程主要就是把常用的基础的给大家讲解. 正则表达式可以用来干什么: (1),匹配字符 ...
- linux服务器加入AD域(sssd)~ 通过域用户ssh登录加域的linux服务器
搭建域控:参考 https://www.cnblogs.com/taosiyu/p/12009120.html 域控计算机全名: WIN-3PLKM2PLE6E.zhihu.test.com 域:zh ...