IDEA创建本地Spark程序,并本地运行
1 IDEA创建maven项目进行测试
v创建一个新项目,步骤如下:
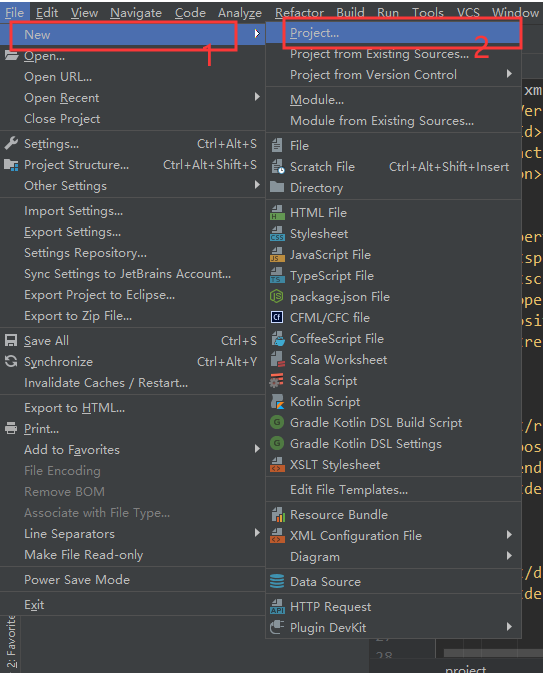

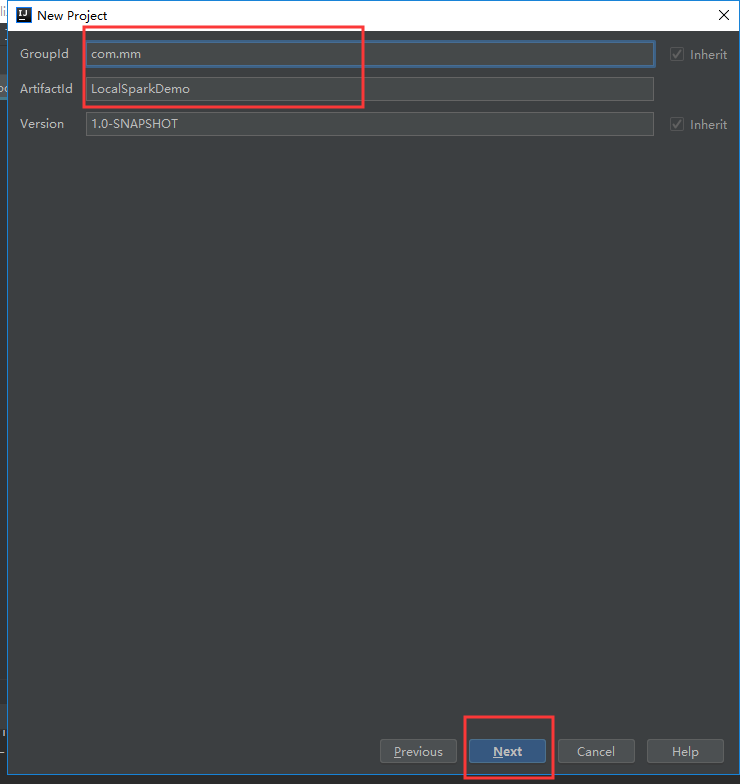
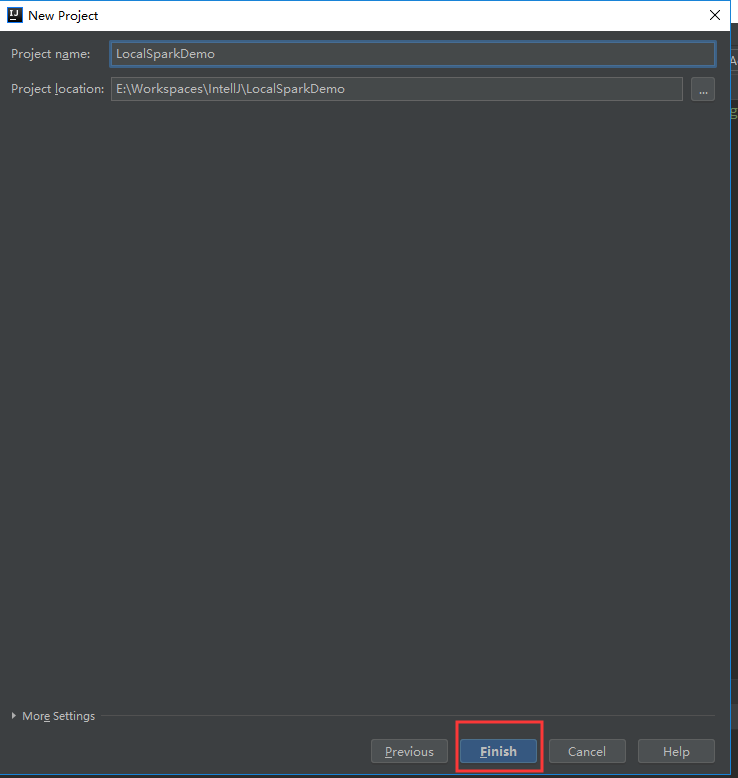
选择“Enable Auto-Import”,加载完后:选择“Enable Auto-Import”,加载完后: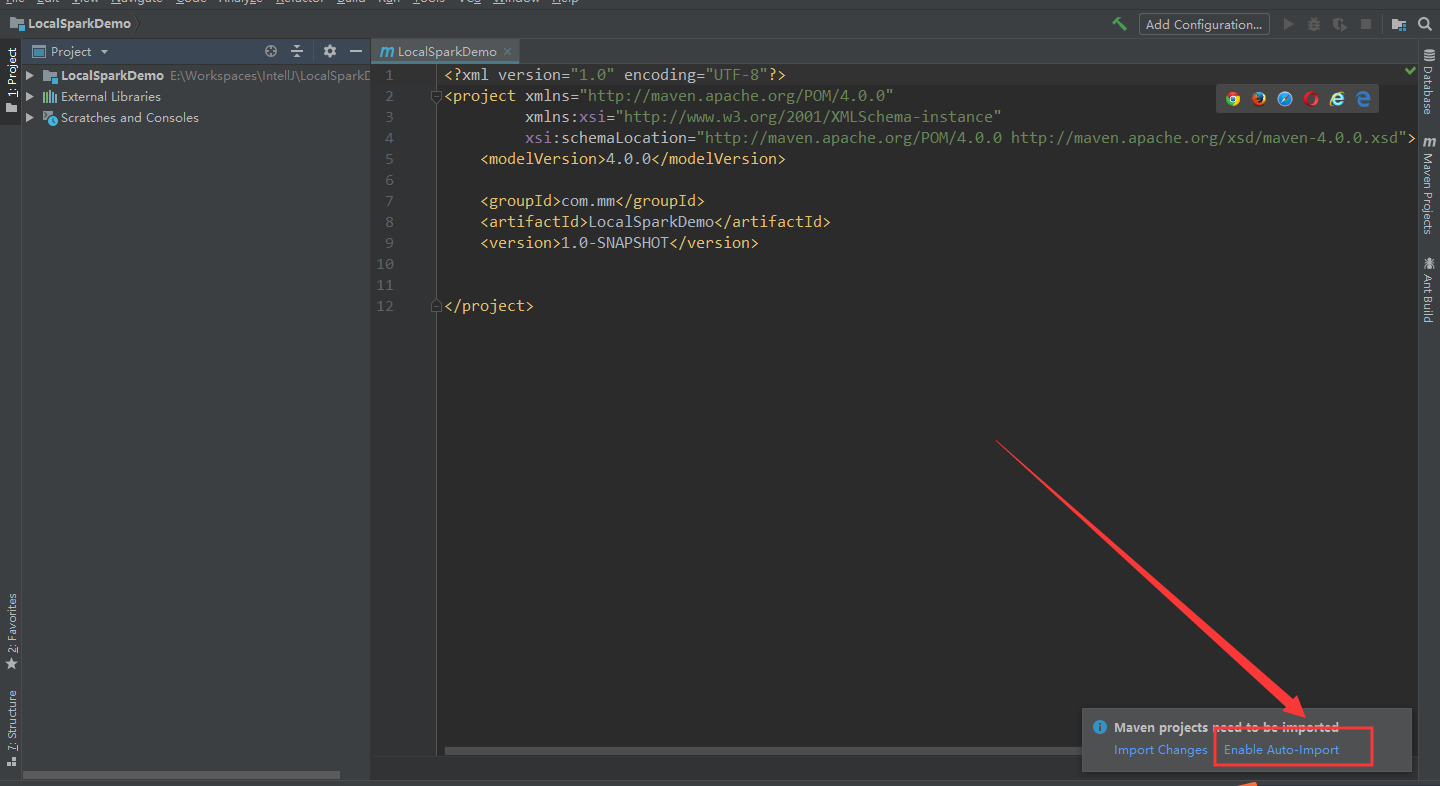
添加SDK依赖:


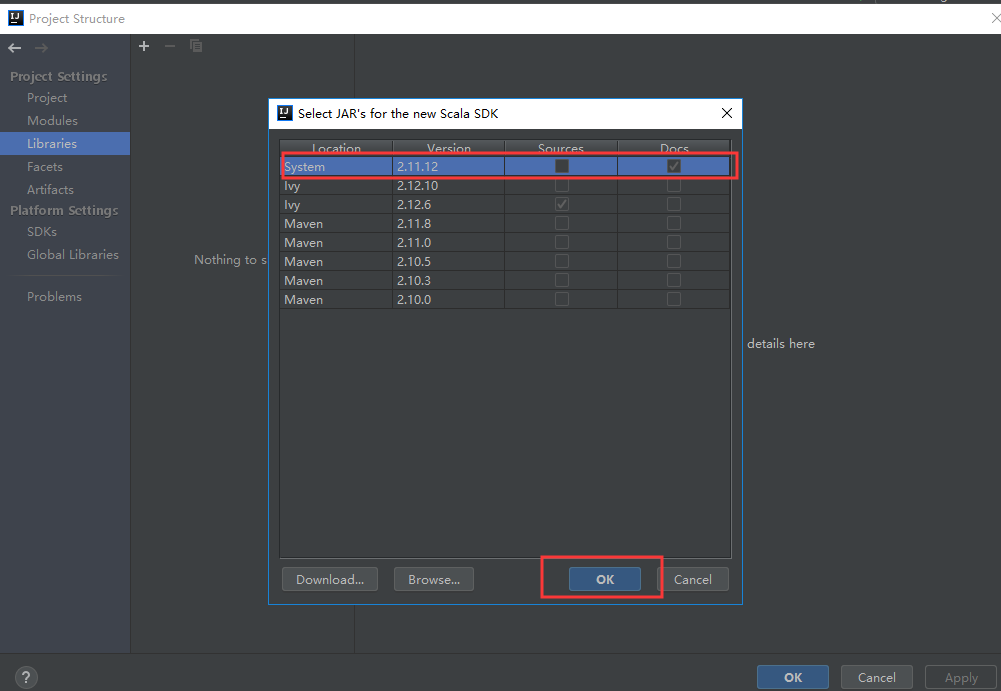
点击OK ok

可以看到scala包加载成功

再修改pox.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.</modelVersion>
<groupId>com.wangle</groupId>
<artifactId>LocalSpark</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<spark.version>2.1.</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
</plugins>
</build> </project>
新建“Demo1.scala”,测试
IDEA创建本地Spark程序,并本地运行的更多相关文章
- spark之scala程序开发(本地运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- scala IDE for Eclipse开发Spark程序
1.开发环境准备 scala IDE for Eclipse:版本(4.6.1) 官网下载:http://scala-ide.org/download/sdk.html 百度云盘下载:链接:http: ...
- 如何在本地使用scala或python运行Spark程序
如何在本地使用scala或python运行Spark程序 包含两个部分: 本地scala语言编写程序,并编译打包成jar,在本地运行. 本地使用python语言编写程序,直接调用spark的接口, ...
- Spark程序本地运行
Spark程序本地运行 本次安装是在JDK安装完成的基础上进行的! SPARK版本和hadoop版本必须对应!!! spark是基于hadoop运算的,两者有依赖关系,见下图: 前言: 1.环境 ...
- 在IntelliJ IDEA中创建和运行java/scala/spark程序
本文将分两部分来介绍如何在IntelliJ IDEA中运行Java/Scala/Spark程序: 基本概念介绍 在IntelliJ IDEA中创建和运行java/scala/spark程序 基本概念介 ...
- 本地Pycharm将spark程序发送到远端spark集群进行处理
前言 最近在搞hadoop+spark+python,所以就搭建了一个本地的hadoop环境,基础环境搭建地址hadoop2.7.7 分布式集群安装与配置,spark集群安装并集成到hadoop集群, ...
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
随机推荐
- Visual Studio源服务器缓存
您是否想过Visual Studio 2008/2010在哪里存储从源服务器下载的源文件?默认情况下,它们会放在Local Settings\Applications Data\SourceServe ...
- 复旦大学2018--2019学年第二学期(18级)高等代数II期末考试第六大题解答
六.(本题10分) 设 $A$ 为 $n$ 阶实对称阵, 证明: $A$ 有 $n$ 个不同的特征值当且仅当对 $A$ 的任一特征值 $\lambda_0$ 及对应的特征向量 $\alpha$, 矩 ...
- 应用JWT进行用户认证及Token的刷新
本文将通过实际的例子来演示如何在ASP.NET Core中应用JWT进行用户认证以及Token的刷新方案(ASP.NET Core 系列目录) 一.什么是JWT? JWT(json web token ...
- quantmod
-quantmod(数据和图形) -TTR(技术分析) -blooter(账户管理) -FinancialInstrument(金融产品) -quantstrast(策略模型) -Performanc ...
- scaffold
#!/usr/bin/env python # -*- coding: utf-8 -*- from __future__ import print_function import argparse ...
- select列表遍历和触发事件
1.以下两种都是jquery获取select列表被选中的value.var strText=$("#select_id").find("option:selected&q ...
- Windows下安装 Linux 下vim编辑器
Windows下安装vim编辑器 下载传送门 https://vim.en.softonic.com/download# 开始安装 这是下载后的可执行文件 双击(或单击)运行软件,选择同意继续进行安装 ...
- Lab_1:练习5——实现函数调用堆栈跟踪函数
题目:实现函数调用堆栈跟踪函数 我们需要在lab1中完成kdebug.c中函数print_stackframe的实现,可以通过函数print_stackframe来跟踪函数调用堆栈中记录的返回地址.如 ...
- [转帖]spring基本概念精炼
spring基本概念精炼 https://www.jianshu.com/p/3c30279d58cd jdk8.0 以及 spring5.0 之后已经使用java的注解方式 不需要使用xml配置文件 ...
- Mysql常见注意事项小记
1. 排序问题 正常如果按照某字段升序排列,空值会排到有值的前面;如果逆序排序空值排在最后. 有时候我们需要该字段为空的行数据要排到最后面去,这时只需要: order by second_parent ...