单细胞分析实录(3): Cell Hashing数据拆分
在之前的文章里,我主要讲了如下两个内容:(1) 认识Cell Hashing;(2): 使用Cell Ranger得到表达矩阵。相信大家已经知道了cell hashing与普通10X转录组的差异,以及使用cellranger得到表达矩阵。
这一篇讲如何使用Seurat的HTODemux函数,CiteFuse的crossSampleDoublets函数两种方法拆分表达矩阵(混了不同来源的细胞),最后还会略微比较一下两种方法得到的结果的差异。
HTODemux
这种方法的原理我在第一篇笔记中已经讲过,感兴趣的小伙伴可以看之前的文章。主要R代码如下:
library(Seurat)
library(ggplot2)
library(tidyverse)
args <- commandArgs(TRUE)
加载R包,导入外部参数,args[1]表示样本名称,args[2]表示ensembl_ID和基因symbol对应关系的文本文件,前面得到的表达矩阵行名是ensembl_ID,为了在后续可视化的时候更省事,建议在这一步更换基因名称。
df <- read.table(paste(args[1],".mat.count.txt",sep = ""),header = T,row.names = 1) #df的行数包括基因和tag
colnames(df) <- str_replace(colnames(df),"\\.1","")
ensembl_symbol <- read.table(args[2],header = F,row.names = 1,stringsAsFactors = F)
df1 <- df[intersect(rownames(ensembl_symbol),rownames(df)),] #提取出基因表达矩阵
df2 <- df[setdiff(rownames(df),rownames(ensembl_symbol)),] #提取出tag表达矩阵
rownames(df1) <- ensembl_symbol[rownames(df1),] #更换基因表达矩阵的行名
接下来利用df2数据框的信息拆分,df2行为tag,列为cellular barcode
cellhash <- CreateSeuratObject(counts = df2,project = "cell_hashing", assay = "HTO")
cellhash <- NormalizeData(cellhash, assay = "HTO", normalization.method = "CLR")
cellhash <- HTODemux(cellhash, assay = "HTO", positive.quantile = 0.85)
最后一步就是拆分,第一篇笔记说过,positive.quantile参数表示在拟合负二项分布之后使用什么分位数来判断UMI是相对大还是相对小,默认值是0.99,实际处理时,发现这个值可能并不合理,比如最终拆分出来的有效细胞数、不同来源细胞数比例和预期差别很大,再比如从图形上看,明显不对(下文有图形说明)。
这一步之后,每一个CB都会带上一个标签,比如我的数据只有两个样本来源,标签会有这4种:Negative、tag6_tag7、tag6、tag7,前面两个表示空液滴、(跨样本的)doublet。
Idents(cellhash) <- "HTO_classification"
FeatureScatter(cellhash, feature1 = paste("hto_",rownames(cellhash)[1],sep=""),
feature2 = paste("hto_",rownames(cellhash)[2],sep = ""),slot = "counts")
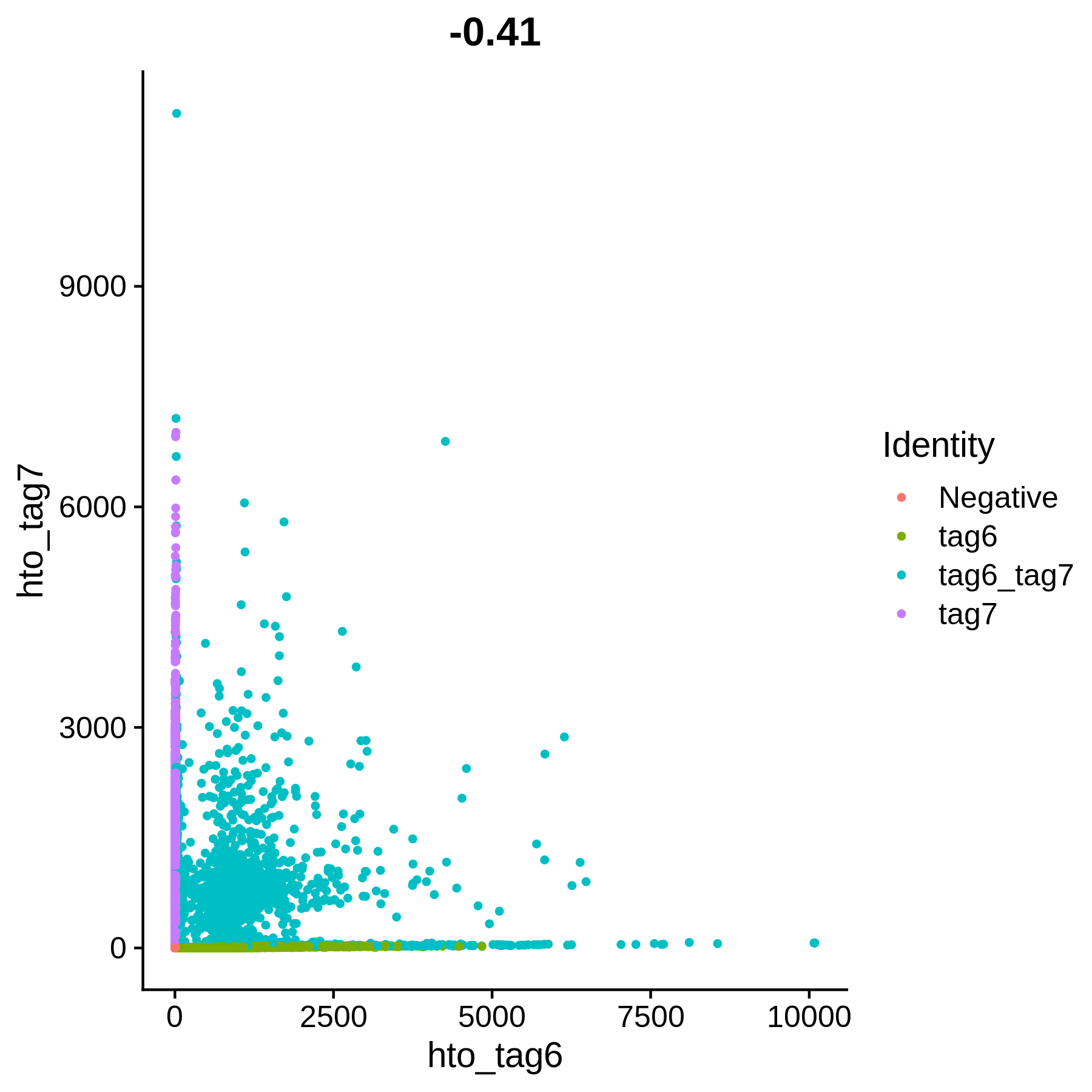
HTOHeatmap(cellhash, assay = "HTO")

上面两个图,可以用来检验拆分的质量,第一张每个点的横纵坐标表示每个CB两个tag的UMI,第二张图的每一列表示每个CB两个tag的标准化之后的表达量。
然后根据每个CB的标签提取出有效的singlet就可以了。
small_df1 <- df1[,colnames(cellhash)[cellhash$HTO_classification==rownames(cellhash)[1]]]
write.table(small_df1,paste(args[1],"_",rownames(cellhash)[1],".mat.count.txt",sep = ""),quote = F,row.names = T,col.names = T,sep="\t")
small_df2 <- df1[,colnames(cellhash)[cellhash$HTO_classification==rownames(cellhash)[2]]]
write.table(small_df2,paste(args[1],"_",rownames(cellhash)[2],".mat.count.txt",sep = ""),quote = F,row.names = T,col.names = T,sep="\t")
除了上面两种Seurat自带图形,下面两种图形也很有参考意义,代码就先不放了,如有需要可以在公众号后台小窗我。
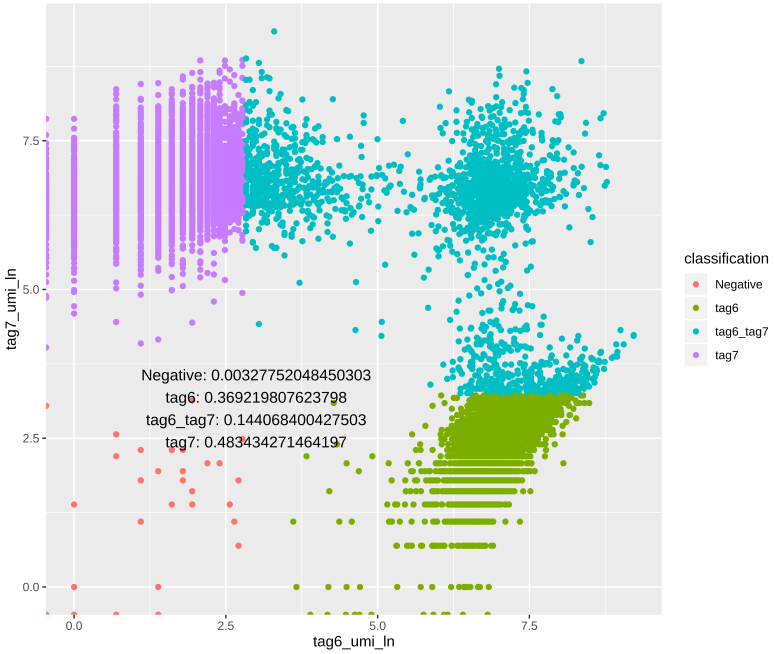

将UMI取对数之后做图,可以从另一个角度看结果,可以看到右上角被HTODemux认定为doublet的CB,像是包含了本应该是singlet的CB。我尝试过positive.quantile用默认值0.99,这种现象会更明显,所以我觉得在做这一步的时候,可以画画这个图,选择一个适中的positive.quantile值。
crossSampleDoublets
CiteFuse包在做这一步的时候,是从取对数之后的UMI矩阵开始的,分别从两个维度拟合正态分布,因此最终得到的结果在散点图上,比上一种方法更说得过去。示意图如下:

具体使用的R代码如下:
library(tidyverse)
library(ggplot2)
library(SingleCellExperiment)
library(CiteFuse)
args <- commandArgs(TRUE)
allexp <- read.table(paste(args[1],".mat.count.txt",sep = ""),header = T,row.names = 1)
colnames(allexp) <- str_replace(colnames(allexp),"\\.1","")
allexp_sce <- preprocessing(exprsMat = as.matrix(allexp)) #生成特定的对象
is.HTO <- grepl("^tag[123678]", rownames(allexp_sce)) #根据自己的tag命名修改正则表达式
allexp_sce <- splitAltExps(allexp_sce, ifelse(is.HTO, "HTO", "gene")) #给每一行加一个标签,HTO或者gene
allexp_sce=normaliseExprs(allexp_sce, altExp_name = "HTO", exprs_value = "counts",transform = c("log")) #仅针对HTO行,取对数
allexp_sce=crossSampleDoublets(allexp_sce,altExp_name = "HTO",totalExp_threshold = 10)
最后一行就是拆分关键步骤,会给每个CB一个标签,totalExp_threshold表示只会保留表达数大于10的CB。
ensembl_symbol <- read.table("/ref/10x/Ensembl_symbol_new.txt",header = F,row.names = 1,stri
ngsAsFactors = F)
df1 <- allexp[intersect(rownames(ensembl_symbol),rownames(allexp)),]
df2 <- allexp[setdiff(rownames(allexp),rownames(ensembl_symbol)),]
rownames(df1) <- ensembl_symbol[rownames(df1),]
tmp1=as.data.frame(t(df2))
tmp2=as.data.frame(allexp_sce$doubletClassify_between_label)
colnames(tmp2)="anno"
tmp2$anno=as.character(tmp2$anno)
crossSampleDoublets返回的标签不容易识别,比如1、2,还需要重新更换名称,如下
for (i in seq(1,length(rownames(tmp2)),1)) {
for (j in seq(1,length(colnames(tmp2)),1)) {
if (tmp2[i,j] == "1") {
tmp2[i,j] = colnames(tmp1)[1]
}
if (tmp2[i,j] == "2") {
tmp2[i,j] = colnames(tmp1)[2]
}
if (tmp2[i,j] == "doublet/multiplet") {
tmp2[i,j] = "doublet"
}
}
}
df_point=cbind(tmp1,tmp2)
colnames(df_point)=c("taga","tagb","anno")
这一步之后就能根据tag标签画散点图,以及提取想要的矩阵了。
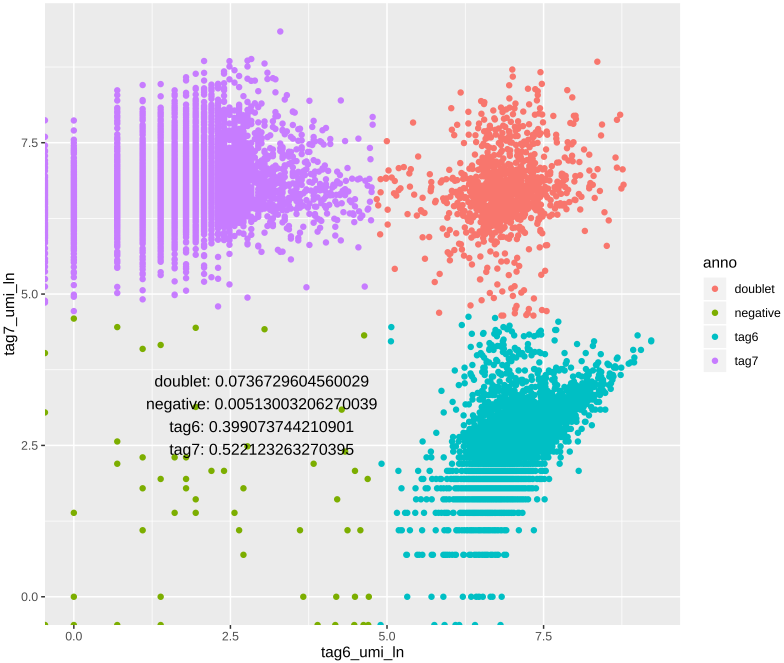
实际处理中,上面两种方法我都用了,最后选了二者交集的CB来提取矩阵(相对保险的做法)。这一步在cell hashing数据的处理中可以说是相当重要了,如果拆分质量不过关,错误地将不同来源的细胞划分到一个矩阵中,对后续分析结果影响很大。
上述代码只呈现了拆分的关键步骤,详细的画图代码没有放上来,如果需要可以在微信后台私信我。
因水平有限,有错误的地方,欢迎批评指正!

单细胞分析实录(3): Cell Hashing数据拆分的更多相关文章
- 单细胞分析实录(1): 认识Cell Hashing
这是一个新系列 差不多是一年以前,我定导后没多久,接手了读研后的第一个课题.合作方是医院,和我对接的是一名博一的医学生,最开始两边的老师很排斥常规的单细胞文章思路,即各大类细胞分群.注释.描述,所以起 ...
- 单细胞分析实录(2): 使用Cell Ranger得到表达矩阵
Cell Ranger是一个"傻瓜"软件,你只需提供原始的fastq文件,它就会返回feature-barcode表达矩阵.为啥不说是gene-cell,举个例子,cell has ...
- 【代码更新】单细胞分析实录(21): 非负矩阵分解(NMF)的R代码实现,只需两步,啥图都有
1. 起因 之前的代码(单细胞分析实录(17): 非负矩阵分解(NMF)代码演示)没有涉及到python语法,只有4个python命令行,就跟Linux下面的ls grep一样的.然鹅,有几个小伙伴不 ...
- 【代码更新】单细胞分析实录(20): 将多个样本的CNV定位到染色体臂,并画热图
之前写过三篇和CNV相关的帖子,如果你做肿瘤单细胞转录组,大概率看过: 单细胞分析实录(11): inferCNV的基本用法 单细胞分析实录(12): 如何推断肿瘤细胞 单细胞分析实录(13): in ...
- 单细胞分析实录(4): doublet检测
最近Cell Systems杂志发表了一篇针对现有几种检测单细胞测序doublet的工具的评估文章,系统比较了常见的例如Scrublet.DoubletFinder等工具在检测准确性.计算效率等方面的 ...
- 单细胞分析实录(5): Seurat标准流程
前面我们已经学习了单细胞转录组分析的:使用Cell Ranger得到表达矩阵和doublet检测,今天我们开始Seurat标准流程的学习.这一部分的内容,网上有很多帖子,基本上都是把Seurat官网P ...
- 单细胞分析实录(17): 非负矩阵分解(NMF)代码演示
本次演示使用的数据来自2017年发表于Cell的头颈鳞癌单细胞文章:Single-Cell Transcriptomic Analysis of Primary and Metastatic Tumo ...
- 单细胞分析实录(8): 展示marker基因的4种图形(一)
今天的内容讲讲单细胞文章中经常出现的展示细胞marker的图:tsne/umap图.热图.堆叠小提琴图.气泡图,每个图我都会用两种方法绘制. 使用的数据来自文献:Single-cell transcr ...
- 单细胞分析实录(18): 基于CellPhoneDB的细胞通讯分析及可视化 (上篇)
细胞通讯分析可以给我们一些细胞类群之间相互调控/交流的信息,这种细胞之间的调控主要是通过受配体结合,传递信号来实现的.不同的分化.疾病过程,可能存在特异的细胞通讯关系,因此阐明这些通讯关系至关重要. ...
随机推荐
- synchronized的底层原理?
最近更新的XX必备系列适合直接背答案,不深究,不喜勿喷. 你能说简单说一下synchronize吗? 可别真简单一句话就说完了呀~ 参考回答: synchronize是java中的关键字,可以用来修饰 ...
- 第8.31节 Python中使用__delattr__清除属性数据
一. 引言 在前面几节我们介绍了__ getattribute__方法和__setattr__方法,分别实现了实例属性的查询和修改(含定义即新增),作为Python中数据操作必不可少的三剑客get.s ...
- 第十二章、Designer中的menu菜单、toolBar工具栏和Action动作
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.引言 Qt Designer中的部件栏并没有菜单.toolBar以及Action相关的部件,仅在 ...
- PyQt(Python+Qt)学习随笔:Qt Designer中主窗口对象的iconSize属性
主窗口对象的iconSize属性保存的是主窗口中工具栏的图标尺寸,在没有设置时缺省是GUI图形界面样式中定义的工具栏的缺省大小. 注意:这个大小是工具栏图标的最小尺寸. 可以使用iconSize()返 ...
- 移动端H5测试调试利器 chrome://inspect/#devices
使用 chrome://inspect/#devices,可以使安卓手机里的WebView也能和chrome一样审查元素,调试和测试移动端H5页面. 我使用的是三星S6 (该功能支持安卓系统4.4及以 ...
- Python实现自动整理文件
前言 工作上的文档和资料好几个月没整理了,因为平常太忙都是随手往桌面丢.整个桌面杂乱无章全是文档和资料.几乎快占满整个屏幕了,所有我必须要整理一下了.但是手动整理太费时间了,于是我想到了python. ...
- 第 6 篇 Scrum 冲刺博客
每天举行会议 会议照片: 昨天已完成的工作与今天计划完成的工作及工作中遇到的困难: 成员姓名 昨天完成工作 今天计划完成的工作 工作中遇到的困难 蔡双浩 实现关注,被关注功能 补充注释,初步查找bug ...
- 题解 CF1446D2 【Frequency Problem (Hard Version)】
给出一个跑得快一点的做法,洛谷最优解 (时间是第二名的 \(\frac{1}{2}\)), CF 第一页 D1 首先找到整个序列的众数 \(G\), 很容易证明答案序列中的两个众数中其中一个是 \(G ...
- sqli-labs 54-65(CHALLANGES)
challenges less-54 less-55 less-56 less-57 less-58 less-59 less-60 less-61 less-62 less-63 less-64 l ...
- 浅谈JAVA代码优化
JAVA代码的优化分为两个方面: 一.减小代码的体积.二.提高代码的执行效率. ============================================================ ...