Flume是什么

分布式流式实时收集日志文件系统,便于实时在线的流式计算,常配合 Storm 和 spark streming 使用。
Flume is a distributed分布式的, reliable可靠的, and available可用的 service for efficiently高效 collecting收集, aggregating聚合, and moving移动 large amounts of log data.
It has a simple简单 and flexible灵活 architecture结构 based on streaming流式 data flows. It is robust健壮 and fault tolerant容错 with tunable可调 reliability mechanisms机制 and many failover and recovery mechanisms. It uses a simple extensible可拓展 data model that allows for online analytic application.
架构图如下
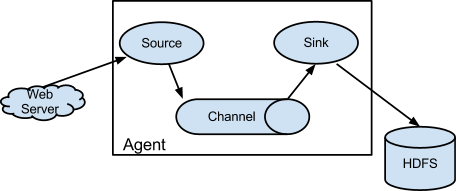

| 角色 | 作用 |
|---|---|
| Agent | Flume的客户端 |
| Event | Flume 数据传输的基本单元,由 [Header] 和 数据的 byte Array 构成,载有数据对Flume不透明;Header 是容纳了KEY_VALUE对的无序集合(Key是唯一的);Header 可以在上下文路由中使用拓展 |
| Source | 用于收集数据,产生数据源的地方,并主动推送数据到 Channel 中 |
| Channel | 数据管道,用于连接 sources 和 sinks ,可以连接多个Source(所谓的分布式),在管道前后增加过滤器可以清洗数据 |
| Sink | 主动到 Channel 拉取数据,向目标源写数据,目标源可以使HDFS、HBase 也可以是下一个Source |
Flume 配置
编辑配置文件的 $JAVA_PATH 就可以使用了
Flume是什么的更多相关文章
- Flume1 初识Flume和虚拟机搭建Flume环境
前言: 工作中需要同步日志到hdfs,以前是找运维用rsync做同步,现在一般是用flume同步数据到hdfs.以前为了工作简单看个flume的一些东西,今天下午有时间自己利用虚拟机搭建了 ...
- Flume(4)实用环境搭建:source(spooldir)+channel(file)+sink(hdfs)方式
一.概述: 在实际的生产环境中,一般都会遇到将web服务器比如tomcat.Apache等中产生的日志倒入到HDFS中供分析使用的需求.这里的配置方式就是实现上述需求. 二.配置文件: #agent1 ...
- Flume(3)source组件之NetcatSource使用介绍
一.概述: 本节首先提供一个基于netcat的source+channel(memory)+sink(logger)的数据传输过程.然后剖析一下NetcatSource中的代码执行逻辑. 二.flum ...
- Flume(2)组件概述与列表
上一节搭建了flume的简单运行环境,并提供了一个基于netcat的演示.这一节继续对flume的整个流程进行进一步的说明. 一.flume的基本架构图: 下面这个图基本说明了flume的作用,以及f ...
- Flume(1)使用入门
一.概述: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统. 当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X ...
- 大数据平台架构(flume+kafka+hbase+ELK+storm+redis+mysql)
上次实现了flume+kafka+hbase+ELK:http://www.cnblogs.com/super-d2/p/5486739.html 这次我们可以加上storm: storm-0.9.5 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- flume使用示例
flume的特点: flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受 ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
- Flume NG Getting Started(Flume NG 新手入门指南)
Flume NG Getting Started(Flume NG 新手入门指南)翻译 新手入门 Flume NG是什么? 有什么改变? 获得Flume NG 从源码构建 配置 flume-ng全局选 ...
随机推荐
- 常见O/R框架介绍
1.hibernate(JPA的一个实现,同时也有自己的特色)2.toplink3.jdo4.ibatis 4.JPA a)意愿统一天下
- 开发中常用的sql语句二
sql 数字全角半角转换 create FUNCTION dbo.ConvertWordAngle ( ), --要转换的字符串 @flag bit --转换标志,0转换成半角,1转换成全角 )) A ...
- [SVN]TortoiseSVN工具培训3─使用基本流程和图标说明
1.SVN的使用基本流程 注意:对于文件编辑方面,上图的编辑副本操作前建议进行Get lock操作,以防出现后续的冲突等异常报错. 2.SVN的基本图标说明
- Azure 进阶攻略 | 上云后的系统,「门禁」制度又该如何实现?
各位办公室白领们,不妨回想一下自己每天去公司上班时的一些细节. 为避免「闲杂人等」进入工作场所,我们需要证明自己是这家公司的员工才能进入,对吧!所有员工,无论所属部门或职位,都必须先证明自己身份,例如 ...
- Open Data for Deep Learning
Open Data for Deep Learning Here you’ll find an organized list of interesting, high-quality datasets ...
- 返回json格式 不忽略null字段
返回json格式 不忽略null字段 发布于 353天前 作者 king666 271 次浏览 复制 上一个帖子 下一个帖子 标签: json 如题,一个实体的某个字段如果为null,在 ...
- selenium 打开浏览器报错java.lang.NoSuchMethodError: org.openqa.selenium.chrome.ChromeOptions.addArguments([Ljava/lang/String;)
java.lang.NoSuchMethodError: org.openqa.selenium.chrome.ChromeOptions.addArguments([Ljava/lang/Strin ...
- 基于ASP.NET WPF技术及MVP模式实战太平人寿客户管理项目开发(Repository模式)
亲爱的网友,我这里有套课程想和大家分享,假设对这个课程有兴趣的.能够加我的QQ2059055336和我联系. 课程背景 本课程是教授使用WPF.ADO.NET.MVVM技术来实现太平人寿保险有限公司 ...
- 转:postMan 使用教程
转:https://www.cnblogs.com/alanjl/p/5490922.html 自从开始做API开发之后,我就在寻找合适的API测试工具.一开始不是很想用Chrome扩展,用的 Wiz ...
- javascript中parseInt(),08,09,返回0
javascript中在使用parseInt(08).parseInt(09),进行整数转换的时候,返回值是0 工具/原料 浏览器 文本编辑器 方法/步骤 javascript中在使用pa ...