Java爬虫框架WebMagic入门——爬取列表类网站文章
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下。
WebMagic框架简介
WebMagic框架包含四个组件,PageProcessor、Scheduler、Downloader和Pipeline。
这四大组件对应爬虫生命周期中的处理、管理、下载和持久化等功能。
这四个组件都是Spider中的属性,爬虫框架通过Spider启动和管理。
WebMagic总体架构图如下:
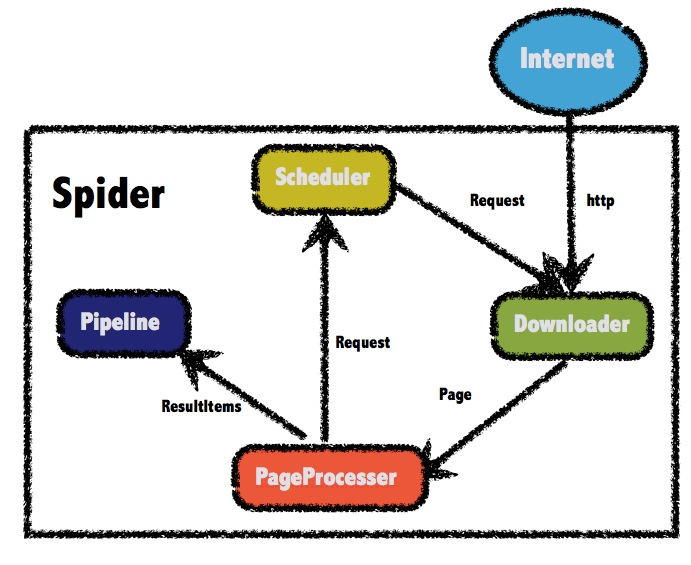
四大组件
PageProcessor 负责解析页面,抽取有用信息,以及发现新的链接。需要自己定义。
Scheduler 负责管理待抓取的URL,以及一些去重的工作。一般无需自己定制Scheduler。
Pipeline 负责抽取结果的处理,包括计算、持久化到文件、数据库等。
Downloader 负责从互联网上下载页面,以便后续处理。一般无需自己实现。
用于数据流转的对象
Request 是对URL地址的一层封装,一个Request对应一个URL地址。
Page 代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
ResultItems 相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。
环境配置
使用Maven来添加依赖的jar包。
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
或者直接摸我下载。
添加完jar包就完成了所有准备工作,是不是很简单。
下面来测试一下。
package edu.heu.spider; import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor; /**
* @ClassName: MyCnblogsSpider
* @author LJH
* @date 2017年11月26日 下午4:41:40
*/
public class MyCnblogsSpider implements PageProcessor { private Site site = Site.me().setRetryTimes(3).setSleepTime(100); public Site getSite() {
return site;
} public void process(Page page) {
if (!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()) {
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"mainContent\"]/div/div/div[@class=\"postTitle\"]/a/@href").all());
} else {
page.putField(page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/text()").toString(),
page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/@href").toString());
}
}
public static void main(String[] args) {
Spider.create(new MyCnblogsSpider()).addUrl("http://www.cnblogs.com/justcooooode/")
.addPipeline(new ConsolePipeline()).run();
}
}
输出结果:
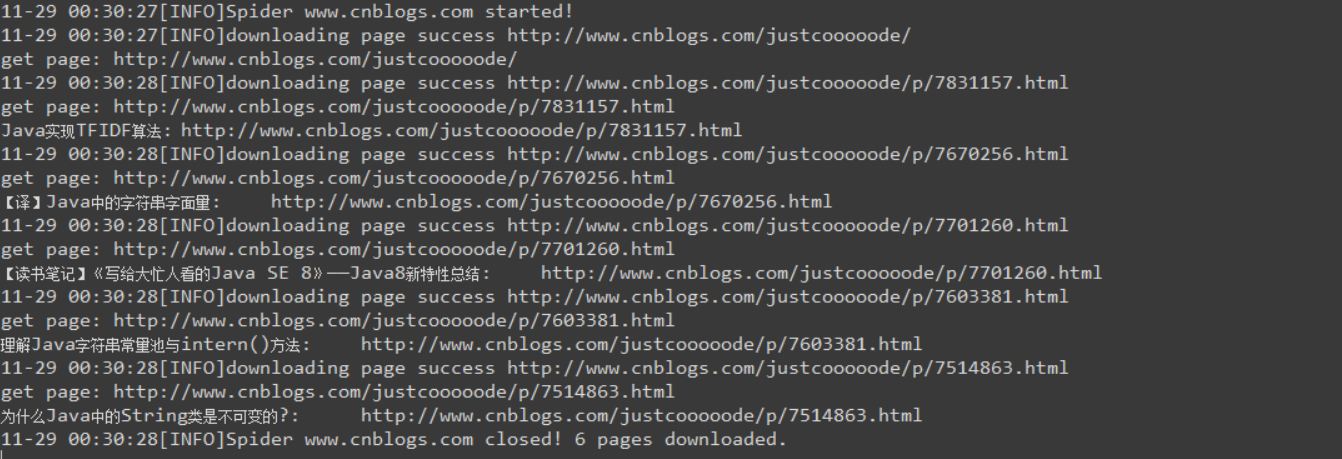
如果你和我一样之前没有用过log4j,可能会出现下面的警告:

这是因为少了配置文件,在resource目录下新建log4j.properties文件,将下面配置信息粘贴进去即可。
目录可以定义成你自己的文件夹。
# 全局日志级别设定 ,file
log4j.rootLogger=INFO, stdout, file # 自定义包路径LOG级别
log4j.logger.org.quartz=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%m%n # Output to the File
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=D:\\MyEclipse2017Workspaces\\webmagic\\webmagic.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%n%-d{MM-dd HH:mm:ss}-%C.%M()%n[%p]%m%n
现在试一下,没有警告了吧
Java爬虫框架WebMagic入门——爬取列表类网站文章的更多相关文章
- Java爬虫框架WebMagic——入门(爬取列表类网站文章)
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下. WebMagic框架简介 WebMagic框架包含四个组件,PageProcessor.Sch ...
- 爬虫框架Scrapy入门——爬取acg12某页面
1.安装1.1自行安装python3环境1.2ide使用pycharm1.3安装scrapy框架2.入门案例2.1新建项目工程2.2配置settings文件2.3新建爬虫app新建app将start_ ...
- JAVA 爬虫框架webmagic 初步使用Demo
一想到做爬虫大家第一个想到的语言一定是python,毕竟python比方便,而且最近也非常的火爆,但是python有一个全局锁的概念新能有瓶颈,所以用java还是比较牛逼的, webmagic 官网 ...
- pyspider爬虫框架webui简介-爬取阿里招聘信息
命令行输入pyspider开启pyspider 浏览器打开http://localhost:5000/ group表示组名,几个项目可以同一个组名,方便管理,当组名修改为delete时,项目会在一天后 ...
- java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标 使用webmagic爬取动作电影列表信息 爬取电影<海王>详细信息[电影名称.电影迅雷下载地址列表] 2. 爬取最新动作片列表 获取电影列表页面数据来源地址 访问http:// ...
- java爬虫框架webmagic学习(一)
1. 爬虫的分类:分布式和单机 分布式主要就是apache的nutch框架,java实现,依赖hadoop运行,学习难度高,一般只用来做搜索引擎开发. java单机的框架有:webmagic和webc ...
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
- Java爬虫——B站弹幕爬取
如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号,cid=14295428 弹幕存放位置为 h ...
- 爬虫框架之Scrapy——爬取某招聘信息网站
案例1:爬取内容存储为一个文件 1.建立项目 C:\pythonStudy\ScrapyProject>scrapy startproject tenCent New Scrapy projec ...
随机推荐
- C#基础数据类型与字节数组(内存中的数据格式)相互转换(BitConverter 类)
在某种通讯协议中(如 Modbus),可能需要把一些基本的数据类型内存中的表示形式转换成以字节数组的形式,方便传送.C/C++中可以利用指针等操作完成,但C#中没有指针,咋办呢?可以用BitCon ...
- 【习题 3-8 UVA - 202】Repeating Decimals
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 余数出现循环节. 就代表出现了循环小数. [代码] #include <bits/stdc++.h> using nam ...
- Iceberg使用
Iceberg是Mac下比較好用的pkg生成工具. 在files中选择你想要存放(自己文件的目录),生成pkg后目录就会存储在设置的那个目录下. 点击scripts选择pkg安装各个阶段所要运行脚本路 ...
- 用FATFS在SD卡里写一串数字
用FATFS写SD卡,如写入数组 s[] ={1,2,3,4,5,6} 想要在txt中显示“123456” 就要把 s[0]=1+'0' 或 s[0]=1+48 或 s[0]=1+0x30 ...
- vc弹出USB的方法. 附试验通过的代码!
vc弹出USB的方法. 附试验通过的代码! http://blog.sina.com.cn/s/blog_4fcd1ea30100qrzn.html (2011-04-15 10:09:48) boo ...
- swift学习第十二天:类的属性定义
类的属性介绍 Swift中类的属性有多种 存储属性:存储实例的常量和变量 计算属性:通过某种方式计算出来的属性 类属性:与整个类自身相关的属性 存储属性 存储属性是最简单的属性,它作为类实例的一部分, ...
- 魔兽争霸war3心得体会(三):UD内战
最近,经常匹配到UD内战.有输有赢,有的时候,自己双矿经济,人口优势巨大,却很遗憾地输掉比赛. 本文,简要分析下 对战过程. 前期狗流开局, 5只狗,一只出去骚扰,攻击商店,防止对方科技蜘蛛骚扰我.二 ...
- jquery-ajax、struts2、json数据问题
jquery代码: $.ajax({ url:url, type:'post', data:{"key1": "value1", "key2" ...
- iOS开发:父子控制器简介:
#import "ViewController.h" #import "ScoietyViewController.h" #import "HotVi ...
- ajax实现注册用户名时动态显示用户名是否已经被注册(1、ajax可以实现我们常见的注册用户名动态判断)(2、jquery里面的ajax也是类似我们这样封装了的函数)
ajax实现注册用户名时动态显示用户名是否已经被注册(1.ajax可以实现我们常见的注册用户名动态判断)(2.jquery里面的ajax也是类似我们这样封装了的函数) 一.总结 1.ajax可以实现我 ...