Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识。
1.首先分析要爬取页面结构。可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面。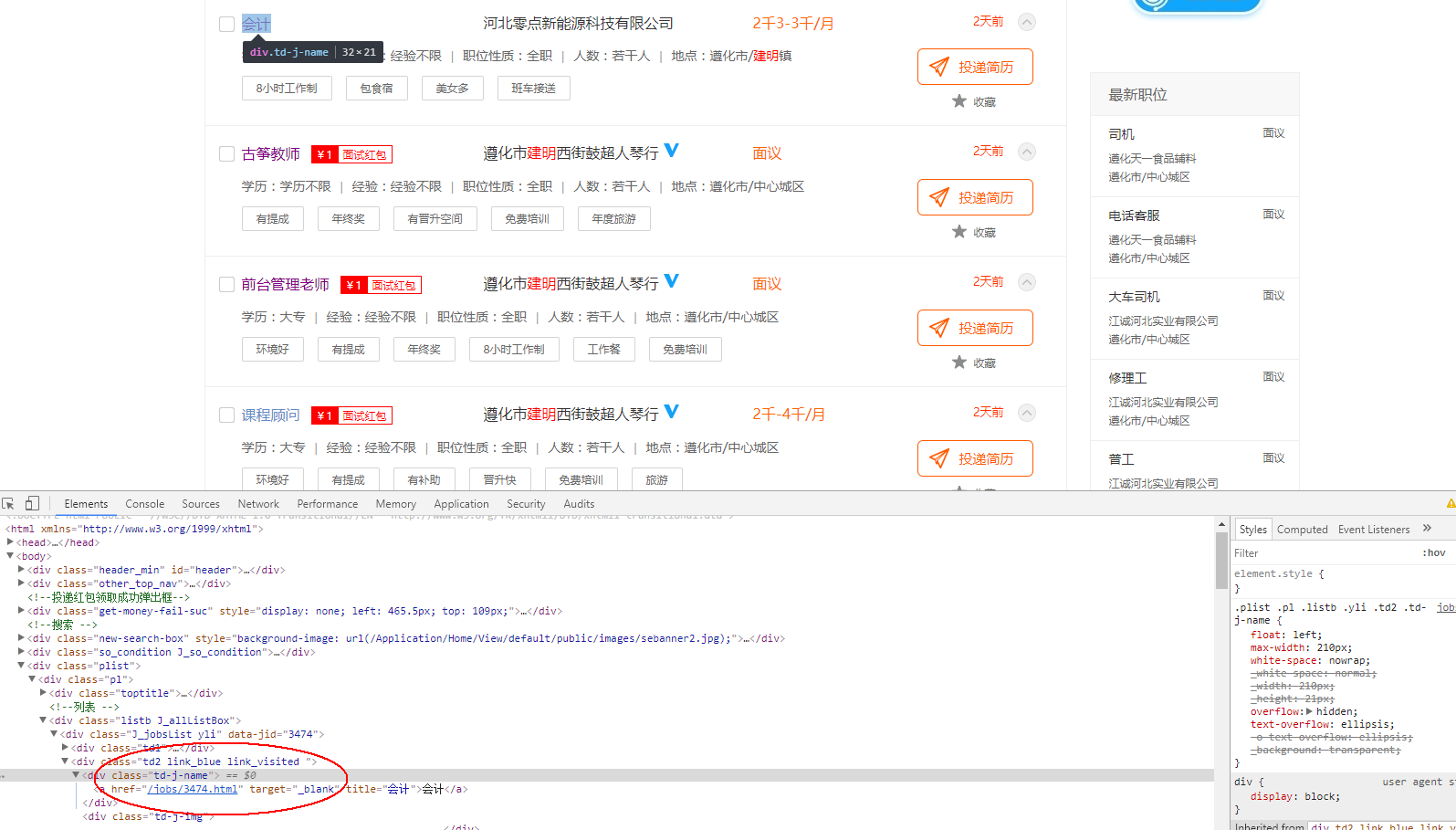
关键代码思路如下:
html = getHtml("http://www.zhrczp.com/jobs/jobs_list/key/%E5%BB%BA%E6%98%8E%E9%95%87/page/1.html")
soup = BeautifulSoup(html, 'lxml') #声明BeautifulSoup对象
hrefbox = soup.find_all("div","td-j-name",True);
links = [];
for href in range(0,len(hrefbox)):
links.append("http://www.zhrczp.com"+hrefbox[href].contents[0].get('href'));#拼接链接
现在已经得到一系列链接,下面分析需要爬取的链接页面的结构。
2.分析页面,页面所有感兴趣的内容均在 div标签里面,可以使用beautifulsoup提供的find_all函数来查找。
main = soup.find_all("div","main",True); 意思是查找div标签class为main的内容
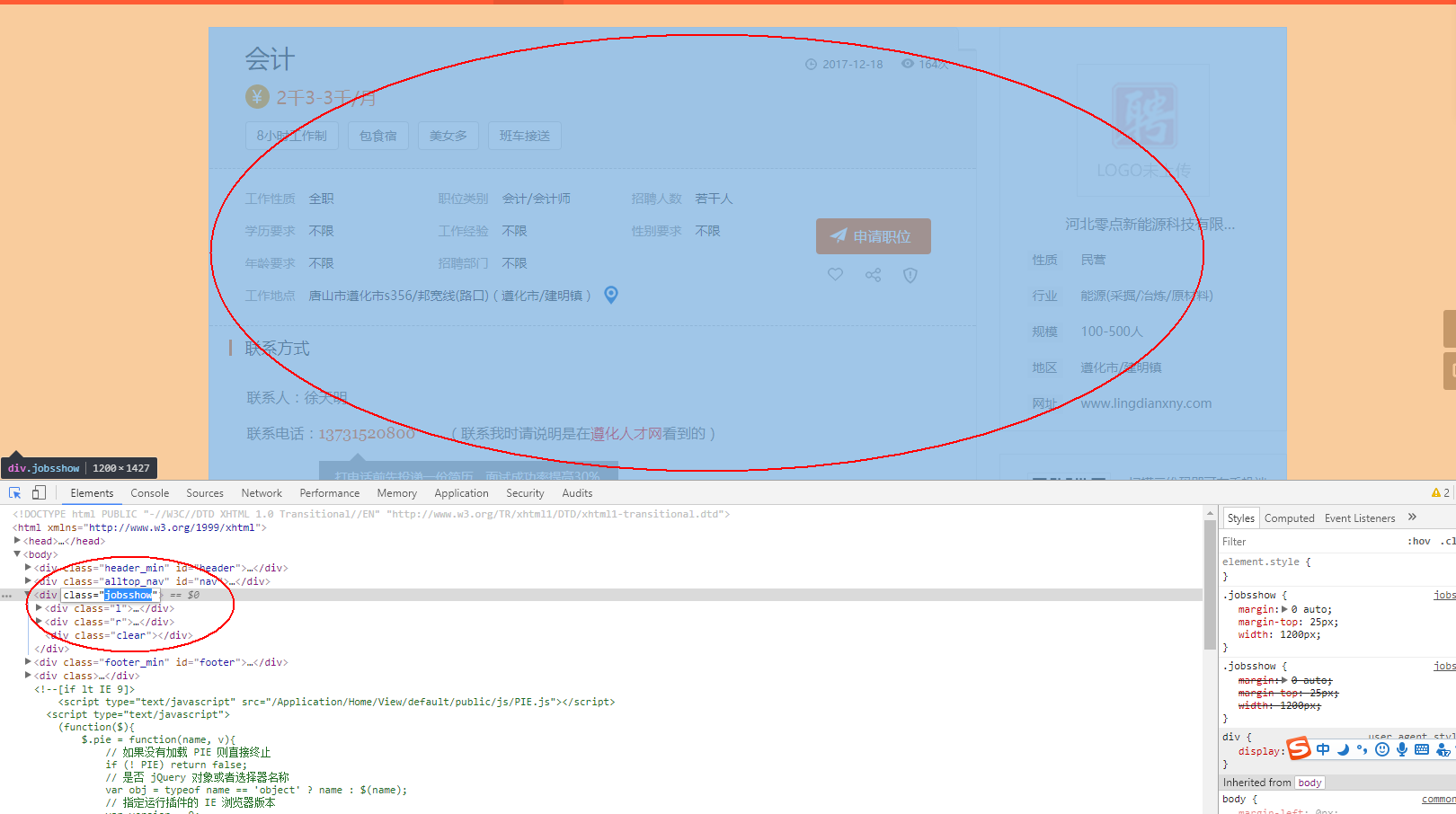
爬取并保存文件,效果如下:

详细代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*- import urllib
from bs4 import BeautifulSoup def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html html = getHtml("http://www.zhrczp.com/jobs/jobs_list/key/%E5%BB%BA%E6%98%8E%E9%95%87/page/1.html") soup = BeautifulSoup(html, 'lxml') #声明BeautifulSoup对象 hrefbox = soup.find_all("div","td-j-name",True); links = [];
for href in range(0,len(hrefbox)):
links.append("http://www.zhrczp.com"+hrefbox[href].contents[0].get('href'));#拼接链接 f=open('a.txt','w',encoding='utf-8')
for link in links:
print(link);
html = getHtml(link)
soup = BeautifulSoup(html, 'lxml') #声明BeautifulSoup对象 main = soup.find_all("div","main",True);
f.write("\n**********************************************************************\n\n")
f.write("职位名称:"+main[0].contents[1].contents[5].contents[1].contents[0]+"\n");#职位名称
f.write("发布时间:"+main[0].contents[1].contents[3].contents[1].contents[0]+"\n");#发布时间
f.write("\n--------------------职位待遇--------------------\n");
f.write("工资:"+main[0].contents[1].contents[7].contents[0]+"\n");#wage
f.write("福利:");
for i in range(1,len(main[0].contents[1].contents[9].contents)-3):
f.write(main[0].contents[1].contents[9].contents[i].contents[0]+" "); f.write("\n\n--------------------联系方式--------------------\n")
f.write(main[0].contents[5].contents[3].contents[0].strip()+"\n");#联系人 去掉空格
f.write(main[0].contents[5].contents[7].contents[0]+main[0].contents[5].contents[7].contents[1].contents[0]+"\n");#联系电话 f.write("\n--------------------联系描述--------------------\n")
describe = main[0].contents[7].contents;
f.write(describe[1].contents[0]+describe[3].contents[0]+"\n");#职位描述 item = soup.find_all("div","item",True);
f.write("\n--------------------职位要求--------------------\n");
f.write(item[0].contents[3].contents[0].contents[0]+":"+item[0].contents[3].contents[1]+"\n");#工作性质
f.write(item[0].contents[5].contents[0].contents[0]+":"+item[0].contents[5].contents[1]+"\n");#职位类别
f.write(item[0].contents[7].contents[0].contents[0]+":"+item[0].contents[7].contents[1]+"\n");#招聘人数
f.write(item[0].contents[11].contents[0].contents[0]+":"+item[0].contents[11].contents[1]+"\n");#学历要求
f.write(item[0].contents[13].contents[0].contents[0]+":"+item[0].contents[13].contents[1]+"\n");#工作经验
f.write(item[0].contents[15].contents[0].contents[0]+":"+item[0].contents[15].contents[1]+"\n");#性别要求
f.write(item[0].contents[19].contents[0].contents[0]+":"+item[0].contents[19].contents[1]+"\n");#年龄要求
f.write(item[0].contents[21].contents[0].contents[0]+":"+item[0].contents[21].contents[1]+"\n");#招聘部门
f.write(item[0].contents[25].contents[0].contents[0]+":"+item[0].contents[25].contents[1]+"\n");#招聘部门 company = soup.find_all("div","cominfo link_gray6",True);
f.write("\n--------------------公司信息--------------------\n");
f.write(company[0].contents[3].contents[1].contents[0]+"\n");#公司名称
f.write(company[0].contents[5].contents[0].contents[0]+":"+company[0].contents[5].contents[1]+"\n");#公司性质
f.write(company[0].contents[7].contents[0].contents[0]+":"+company[0].contents[7].contents[1]+"\n");#公司行业
f.write(company[0].contents[9].contents[0].contents[0]+":"+company[0].contents[9].contents[1]+"\n");#公司规模
f.write(company[0].contents[11].contents[0].contents[0]+":"+company[0].contents[11].contents[1]+"\n");#公司地区 f.write("\n**********************************************************************\n")
f.close();
参考:
http://www.cnblogs.com/Albert-Lee/p/6232745.html
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
Python爬虫学习之使用beautifulsoup爬取招聘网站信息的更多相关文章
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- Python爬虫学习(6): 爬取MM图片
为了有趣我们今天就主要去爬取以下MM的图片,并将其按名保存在本地.要爬取的网站为: 大秀台模特网 1. 分析网站 进入官网后我们发现有很多分类: 而我们要爬取的模特中的女模内容,点进入之后其网址为:h ...
- 爬虫学习(二)--爬取360应用市场app信息
欢迎加入python学习交流群 667279387 爬虫学习 爬虫学习(一)-爬取电影天堂下载链接 爬虫学习(二)–爬取360应用市场app信息 代码环境:windows10, python 3.5 ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标 之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户.详细介绍了第一次探索python爬虫的坑. 准 ...
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- Python 爬虫实例(4)—— 爬取网易新闻
自己闲来无聊,就爬取了网易信息,重点是分析网页,使用抓包工具详细的分析网页的每个链接,数据存储在sqllite中,这里只是简单的解析了新闻页面的文字信息,并未对图片信息进行解析 仅供参考,不足之处请指 ...
- [原创]python+beautifulsoup爬取整个网站的仓库列表与仓库详情
from bs4 import BeautifulSoup import requests import os def getdepotdetailcontent(title,url):#爬取每个仓库 ...
随机推荐
- 初入红尘——在安联IT实习的一点感受(未完......)
文章很短,只有800字. 从踏进安联的大门开始,我便入了红尘. 安联的迎客之道 “花径不曾缘客扫,蓬门今始为君开.”我的第一个贵人就是前台的美君姐.由于路况不熟,所以我没把握好时间,到的时候比约定的面 ...
- 使用Identity Server 4建立Authorization Server (3)
预备知识: http://www.cnblogs.com/cgzl/p/7746496.html 第一部分: http://www.cnblogs.com/cgzl/p/7780559.html 第二 ...
- 对象作为 handleEvent
elem.addEventListener("click", obj, false); //用对象作为处理函数 var obj = { handleEvent: ...
- Hiberante知识点梳理
Hibernate简介 Hibernat是一个ORM(关系映射)框架,对JDBC访问数据库的操作进行了简化,并且将数据库表中的字段和关系映射为对象,简化了对数据库的操作. 使用方法 读取并解析配置文件 ...
- ReentrantLock可重入锁的使用场景
摘要 从使用场景的角度出发来介绍对ReentrantLock的使用,相对来说容易理解一些. 场景1:如果发现该操作已经在执行中则不再执行(有状态执行) a.用在定时任务时,如果任务执行时间可能超过下次 ...
- ES6中class关键字
1 .介绍 //定义类 class Point { constructor(x, y) { this.x = x; this.y = y; } toString() { return '(' + th ...
- spring4新特性-泛型依赖注入
1 文件结构 2 具体类 2.1两个抽象类,在Service里面写公共的方法,在各自的具体实现类里面写各自的方法 package repo;import model.User;/** * Crea ...
- 隐藏17年的Office远程代码执行漏洞(CVE-2017-11882)
Preface 这几天关于Office的一个远程代码执行漏洞很流行,昨天也有朋友发了相关信息,于是想复现一下看看,复现过程也比较简单,主要是简单记录下. 利用脚本Github传送地址 ,后面的参考链接 ...
- C#中RichEdit控件,保存文本和图片到mysql数据库
分别通过内存流和RTF文件保存 方法1: //建立内存流 MemoryStream ms = new MemoryStream(); //ms.Position = 0; //把当前的richtext ...
- Javascript中prototype属性
prototype作为JS相对比较难理解的一个知识点,在这里发表下自己的理解. 本文将包含以下几部分内容: 1.js prototype的简单介绍, 2.js构造函数的介绍, 3.prototype的 ...