小爬新浪新闻AFCCL
1.任务目标:
爬取新浪新闻AFCCL的文章:文章标题、时间、来源、内容、评论数等信息。
2.目标网页:
http://sports.sina.com.cn/z/AFCCL/
3.网页分析
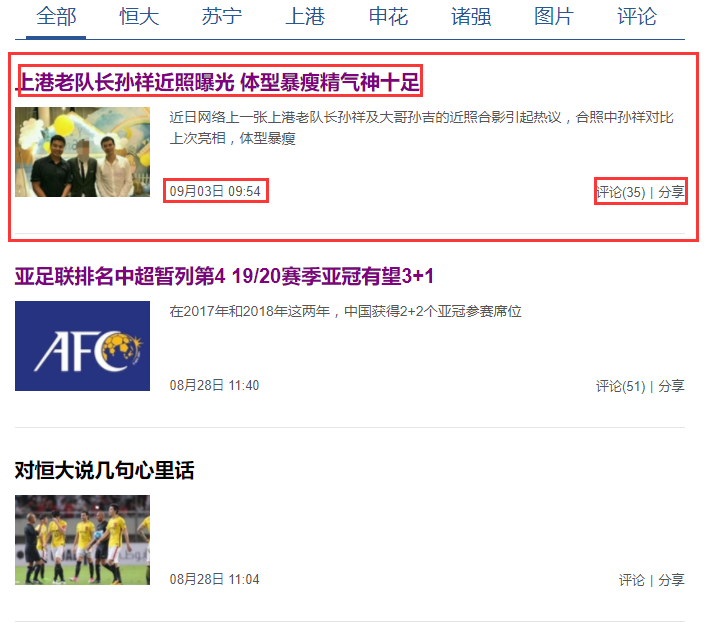

4.源代码:
#!/usr/bin/env/python
# coding:utf-8
import sys
import requests
from bs4 import BeautifulSoup
import json
import re
if __name__ == '__main__':
url = 'http://sports.sina.com.cn/z/AFCCL/'
res = requests.get(url)
html_doc = res.content soup = BeautifulSoup(html_doc, 'html.parser') a_list=[]
#爬取新闻时间,标题,链接
for news in soup.select('.news-item'):
if(len(news.select('h2'))>0):
h2=news.select('h2')[0].text
a=news.select('a')[0]['href']
time=news.select('.time')[0].text
# print(time,h2,a)
a_list.append(a)
#爬取内文资料
for i in range(len(a_list)):
url=a_list[i]
res = requests.get(url)
html_doc = res.content
soup = BeautifulSoup(html_doc, 'html.parser')
#获取文章标题、时间、来源、内容,评论数
title=soup.select('#j_title')
if title:
title = soup.select('#j_title')[0].text.strip()
time = soup.select('.article-a__time')[0].text.strip()
source = soup.select('.article-a__source')[0].text.strip()
content = soup.select('.article-a__content')[0].text.strip()
#动态生成获取评论的Ajax url eg:'http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=ty&newsid=comos-fykiuaz1429964&group=&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=20&jsvar=loader_1504416797470_64712661'
# print(url)
pattern_id=r'(fyk\w*).s?html'
# print(re.search(pattern_id,url).group(1))
id=re.search(pattern_id,url).group(1)
url='http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=ty&newsid=comos-'+id+'&group=&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=20'
comments = requests.get(url)
jd=json.loads(comments.text.strip('var data='))
commentCount = jd['result']['count']['total'] # 评论数
print(time,title,source,content)
print(commentCount)
5.运行结果:

6.小结:
对于一次请求获得的资源爬取是比较顺利的,对于异步请求的资源需要查看检查器,寻找资源所在请求,正对性的爬取。
eg:“评论及评论数”的爬取。
小爬新浪新闻AFCCL的更多相关文章
- selenium+BeautifulSoup+phantomjs爬取新浪新闻
一 下载phantomjs,把phantomjs.exe的文件路径加到环境变量中,也可以phantomjs.exe拷贝到一个已存在的环境变量路径中,比如我用的anaconda,我把phantomjs. ...
- python3爬虫-爬取新浪新闻首页所有新闻标题
准备工作:安装requests和BeautifulSoup4.打开cmd,输入如下命令 pip install requests pip install BeautifulSoup4 打开我们要爬取的 ...
- 门户级UGC系统的技术进化路线——新浪新闻评论系统的架构演进和经验总结(转)
add by zhj:先收藏了 摘要:评论系统是所有门户网站的核心标准服务组件之一.本文作者曾负责新浪网评论系统多年,这套系统不仅服务于门户新闻业务,还包括调查.投票等产品,经历了从单机到多机再到集群 ...
- Python_网络爬虫(新浪新闻抓取)
爬取前的准备: BeautifulSoup的导入:pip install BeautifulSoup4 requests的导入:pip install requests 下载jupyter noteb ...
- Lance老师UI系列教程第八课->新浪新闻SlidingMenu界面的实现
UI系列教程第八课:Lance老师UI系列教程第八课->新浪新闻SlidingMenu界面的实现 今天蓝老师要讲的是关于新浪新闻侧滑界面的实现.先看看原图: 如图所示,这种侧滑效果以另一种方式替 ...
- Python爬虫:新浪新闻详情页的数据抓取(函数版)
上一篇文章<Python爬虫:抓取新浪新闻数据>详细解说了如何抓取新浪新闻详情页的相关数据,但代码的构建不利于后续扩展,每次抓取新的详情页时都需要重新写一遍,因此,我们需要将其整理成函数, ...
- Android仿新浪新闻SlidingMenu界面的实现 .
先看看原图: 如图所示,这种侧滑效果以另一种方式替代了原先tab导航的那种用户体验方式 给人耳目一新的感觉,现已被广大知名应用所效仿,如新浪新闻,网易新闻,人人网等 那么这种效果该如何实现呢?那就需要 ...
- 今天写了一个简单的新浪新闻RSS操作类库
今天,有位群友问我如何获新浪新闻列表相关问题,我想,用正则表达式网页中取显然既复杂又不一定准确,现在许多大型网站都有RSS集合,所以我就跟他说用RSS应该好办一些. 一年前我写过一个RSS阅读器,不过 ...
- 采集新浪新闻php插件
今天没事,就分享一个采集新浪新闻PHP插件接口,可用于火车头采集,比较简单,大家可以研究! 新浪新闻实时动态列表为:https://news.sina.com.cn/roll/?qq-pf-to=pc ...
随机推荐
- 【canvas学习笔记一】基本认识
<canvas>标签定义了一块画布,画布可以在网页中绘制2D和3D图象,现在先学习如何绘制2D图象,绘制3D图象属于WebGL的内容(也就是网页版的OpenGL,3D图形接口). 属性 & ...
- tensorflow bias_add应用
import tensorflow as tf a=tf.constant([[1,1],[2,2],[3,3]],dtype=tf.float32) b=tf.constant([1,-1],dty ...
- Python开发【笔记】:单线程下执行多个定时任务
单线程多定时任务 前言:公司业务需求,实例当中大量需要启动定时器的操作:大家都知道python中的定时器用的是threading.Timer,每当启动一个定时器时,程序内部起了一个线程,定时器触发执行 ...
- 小白也能看懂的插件化DroidPlugin原理(三)-- 如何拦截startActivity方法
前言:在前两篇文章中分别介绍了动态代理.反射机制和Hook机制,如果对这些还不太了解的童鞋建议先去参考一下前两篇文章.经过了前面两篇文章的铺垫,终于可以玩点真刀实弹的了,本篇将会通过 Hook 掉 s ...
- 蓝桥杯比赛javaB组练习《四平方和》
四平方和 四平方和定理,又称为拉格朗日定理:每个正整数都可以表示为至多4个正整数的平方和.如果把0包括进去,就正好可以表示为4个数的平方和. 比如:5 = 0^2 + 0^2 + 1^2 + 2^27 ...
- 3.commonjs模块
1.首先建一个math.js exports.add = function(a, b){ return a + b; } exports.sub = function(a, b){ return a ...
- Javascript闭包与作用域this
闭包与this的一般用法 关于js函数与闭包的文章想必大家都是在熟悉不过的了,作为js核心亦即最强大的功能之一,每次回过头翻出来看一看,都会有不一样的收获与理解,经典的含义无非如此而已. 1.闭包 1 ...
- struts2增删改查---layer---iframe层---通配符---国际化
在前一篇文章的基础上,修改一部分即可(在此只是简单介绍) struts.xml页面 在原来的基础之上 action的name="*_*" class="包名.{1}&q ...
- 将app接口服务器改为dotnet core承载
昨天我的一个 app 的接口服务器挂掉了,国外的小鸡意外的翻车,连同程序和数据一起,猝不及防.我的服务端程序是 asp.net mvc ,小鸡是 256 M 的内存跑不了 windows 系统,装的 ...
- [js高手之路] vue系列教程 - 实现留言板todolist(3)
通过前面两篇文章的的学习,我们掌握了vue的基本用法. 本文,就利用这些基础知识来实现一个留言板, 老外把他称之为todolist. 第一步.使用bootstrap做好布局 <!DOCTYPE ...