机器学习-随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )
梯度下降(GD)是最小化风险函数、损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正。
下面的h(x)是要拟合的函数,J(theta)损失函数,theta是参数,要迭代求解的值,theta求解出来了那最终要拟合的函数h(theta)就出来了。其中m是训练集的记录条数,i是参数的个数。

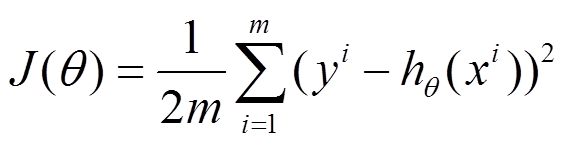
1、批量梯度下降的求解思路如下:
(1)将J(theta)对theta求偏导,得到每个theta对应的的梯度

(2)由于是要最小化风险函数,所以按每个参数theta的梯度负方向,来更新每个theta

(3)从上面公式可以注意到,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果m很大,那么可想而知这种方法的迭代速度!!所以,这就引入了另外一种方法,随机梯度下降。
2、随机梯度下降的求解思路如下:
(1)上面的风险函数可以写成如下这种形式,损失函数对应的是训练集中每个样本的粒度,而上面批量梯度下降对应的是所有的训练样本:

(2)每个样本的损失函数,对theta求偏导得到对应梯度,来更新theta

(3)随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将theta迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
3、对于上面的linear regression问题,与批量梯度下降对比,随机梯度下降求解的会是最优解吗?
(1)批量梯度下降---最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小。
(2)随机梯度下降---最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。
4、梯度下降用来求最优解,哪些问题可以求得全局最优?哪些问题可能局部最优解?
对于上面的linear regression问题,最优化问题对theta的分布是unimodal,即从图形上面看只有一个peak,所以梯度下降最终求得的是全局最优解。然而对于multimodal的问题,因为存在多个peak值,很有可能梯度下降的最终结果是局部最优。
5、随机梯度和批量梯度的实现差别
以前一篇博文中NMF实现为例,列出两者的实现差别(注:其实对应Python的代码要直观的多,以后要练习多写python!)
// 随机梯度下降,更新参数
public void updatePQ_stochastic(double alpha, double beta) {
for (int i = 0; i < M; i++) {
ArrayList<Feature> Ri = this.dataset.getDataAt(i).getAllFeature();
for (Feature Rij : Ri) {
// eij=Rij.weight-PQ for updating P and Q
double PQ = 0;
for (int k = 0; k < K; k++) {
PQ += P[i][k] * Q[k][Rij.dim];
}
double eij = Rij.weight - PQ; // update Pik and Qkj
for (int k = 0; k < K; k++) {
double oldPik = P[i][k];
P[i][k] += alpha
* (2 * eij * Q[k][Rij.dim] - beta * P[i][k]);
Q[k][Rij.dim] += alpha
* (2 * eij * oldPik - beta * Q[k][Rij.dim]);
}
}
}
} // 批量梯度下降,更新参数
public void updatePQ_batch(double alpha, double beta) { for (int i = 0; i < M; i++) {
ArrayList<Feature> Ri = this.dataset.getDataAt(i).getAllFeature(); for (Feature Rij : Ri) {
// Rij.error=Rij.weight-PQ for updating P and Q
double PQ = 0;
for (int k = 0; k < K; k++) {
PQ += P[i][k] * Q[k][Rij.dim];
}
Rij.error = Rij.weight - PQ;
}
} for (int i = 0; i < M; i++) {
ArrayList<Feature> Ri = this.dataset.getDataAt(i).getAllFeature();
for (Feature Rij : Ri) {
for (int k = 0; k < K; k++) {
// 对参数更新的累积项
double eq_sum = 0;
double ep_sum = 0; for (int ki = 0; ki < M; ki++) {// 固定k和j之后,对所有i项加和
ArrayList<Feature> tmp = this.dataset.getDataAt(i).getAllFeature();
for (Feature Rj : tmp) {
if (Rj.dim == Rij.dim)
ep_sum += P[ki][k] * Rj.error;
}
}
for (Feature Rj : Ri) {// 固定k和i之后,对多有j项加和
eq_sum += Rj.error * Q[k][Rj.dim];
} // 对参数更新
P[i][k] += alpha * (2 * eq_sum - beta * P[i][k]);
Q[k][Rij.dim] += alpha * (2 * ep_sum - beta * Q[k][Rij.dim]);
}
}
}
}
机器学习-随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的更多相关文章
- batch gradient descent(批量梯度下降) 和 stochastic gradient descent(随机梯度下降)
批量梯度下降是一种对参数的update进行累积,然后批量更新的一种方式.用于在已知整个训练集时的一种训练方式,但对于大规模数据并不合适. 随机梯度下降是一种对参数随着样本训练,一个一个的及时updat ...
- 1. 批量梯度下降法BGD 2. 随机梯度下降法SGD 3. 小批量梯度下降法MBGD
排版也是醉了见原文:http://www.cnblogs.com/maybe2030/p/5089753.html 在应用机器学习算法时,我们通常采用梯度下降法来对采用的算法进行训练.其实,常用的梯度 ...
- 机器学习-随机梯度下降(Stochastic gradient descent)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比[转]
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 【转】 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 随机梯度下降 Stochastic gradient descent
梯度下降法先随机给出参数的一组值,然后更新参数,使每次更新后的结构都能够让损失函数变小,最终达到最小即可. 在梯度下降法中,目标函数其实可以看做是参数的函数,因为给出了样本输入和输出值后,目标函数就只 ...
- 几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
https://blog.csdn.net/u012328159/article/details/80252012 我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种 ...
- python机器学习——随机梯度下降
上一篇我们实现了使用梯度下降法的自适应线性神经元,这个方法会使用所有的训练样本来对权重向量进行更新,也可以称之为批量梯度下降(batch gradient descent).假设现在我们数据集中拥有大 ...
- 批量梯度下降(Batch gradient descent) C++
At each step the weight vector is moved in the direction of the greatest rate of decrease of the err ...
随机推荐
- qt之旅-1纯手写Qt界面
通过手写qt代码来认识qt程序的构成,以及特性.设计一个查找对话框.以下是设计过程 1 新建一个empty qt project 2 配置pro文件 HEADERS += \ Find.h QT += ...
- 目前使用过的各大厂商rtsp取流的url
目前使用过的各大厂商取流规则是在实际的工作中遇到的相关视频接入问题,通过rtsp协议接入视频数据的一些记录,其中的图片可能来源于网络,内容部分来源于网络,本人仅仅是对相关内容作了汇总. 海康RTSP取 ...
- 【IOS】启动画面
总述: 两种方式,一种是使用系统自带的.按规则定义启动图片名称就可以,显示为1秒,要想延长时间,用[nsthread sleepForTimeInterval:5.0] ,还有一种就是自己定义ui ...
- Arch Linux 下Android 源代码的下载以及编译
之前把公司的开发环境由Ubuntu Kylin 换成了Arch Linux.而Arch 下由于种种问题公司的代码一直编只是去.搞定了之后也一直忘了写下来,希望能给相同在Arch 下做Android 开 ...
- ExtJs布局中,控件如何水平居中?
如此即可,有图有代码有j8: var formGridHead = Ext.create('Ext.form.Panel', { id: 'MyGridHead', region: 'north', ...
- struts2的(S2-045,CVE-2017-5638)漏洞测试笔记
网站用的是struts2 的2.5.0版本 测试时参考的网站是http://www.myhack58.com/Article/html/3/62/2017/84026.htm 主要步骤就是用Burp ...
- Windows的MAX_PATH
MAX_PATH的解释: 文件名最长256(ANSI),加上盘符(X:\)3字节,259字节,再加上结束符1字节,共260http://msdn.microsoft.com/en-us/library ...
- RFC 在OA中创建PR
创建PR:BAPI_REQUISITION_CREATE BAPI_PR_CREATE "Create Enjoy Purchase Requisistion ...
- mongodb02
memcached redis : kv数据库(key/value) mongodb 文档数据库,存储的是文档(Bson->json对象二进制化后叫bson,js的二进制对象,引擎是用js实现的 ...
- POJ - 1459 Power Network(最大流)(模板)
1.看了好久,囧. n个节点,np个源点,nc个汇点,m条边(对应代码中即节点u 到节点v 的最大流量为z) 求所有汇点的最大流. 2.多个源点,多个汇点的最大流. 建立一个超级源点.一个超级汇点,然 ...