第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门

我的搜素简单实现原理
我们可以用js来实现,首先用js获取到输入的搜索词
设置一个数组里存放搜素词,
判断搜索词在数组里是否存在如果存在删除原来的词,重新将新词放在数组最前面
如果不存在直接将新词放在数组最前面即可,然后循环数组显示结果即可
热门搜索
实现原理,当用户搜索一个词时,可以保存到数据库,然后记录搜索次数,
利用redis缓存搜索次数最到的词,过一段时间更新一下缓存
备注:Django结合Scrapy的开源项目可以学习一下
django-dynamic-scraper
https://github.com/holgerd77/django-dynamic-scraper
补充
默认的elasticsearch(搜索引擎)只能搜索1万条数据,在大就会报错了
设置方法
步骤一:
打开项目的索引库地址,将该索引先关闭,否则设置操步骤二无法提交
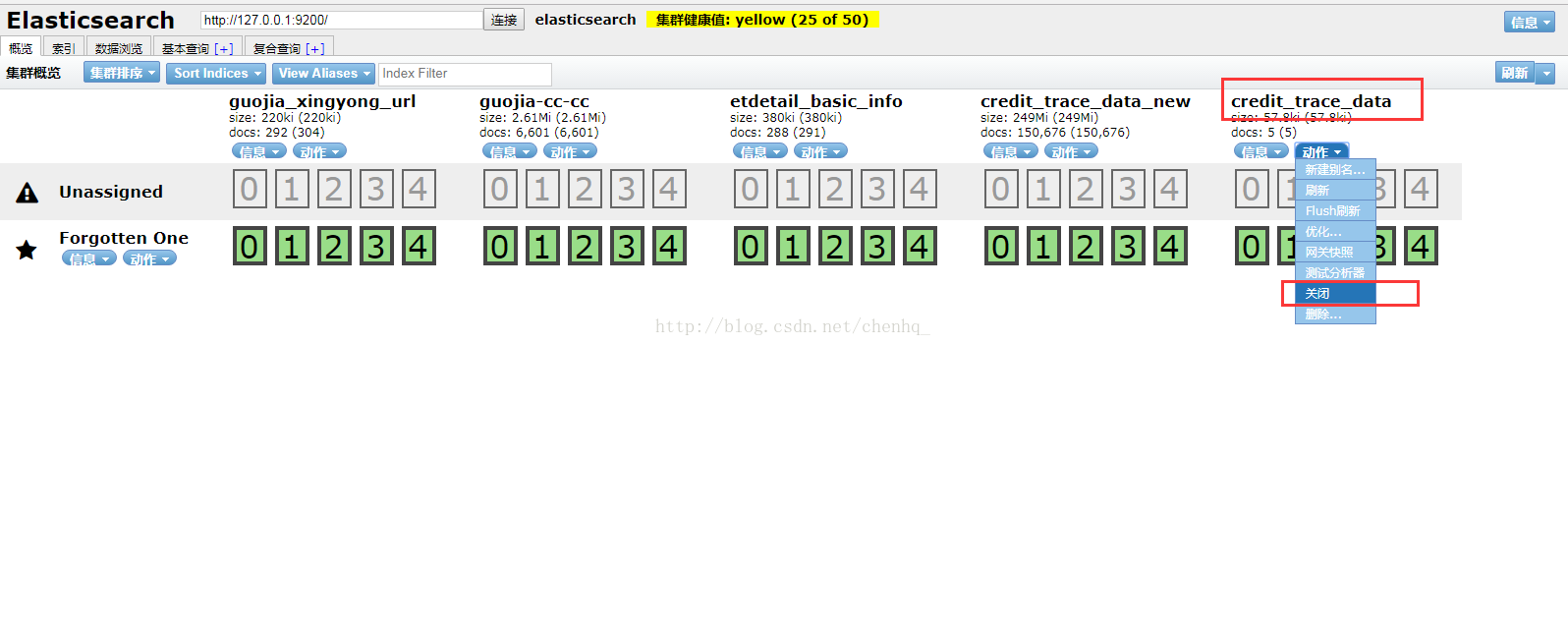
步骤二:
打开复合查询,填入如下信息,记得选择PUT方式提交,credit_trace_data改为本索引库中的索引,max_result_window设为20亿,此值是integer类型,不能无限大
http://127.0.0.1:9200/ PUT
credit_trace_data/_settings?preserve_existing=true
{
"max_result_window" : "2000000000"
}
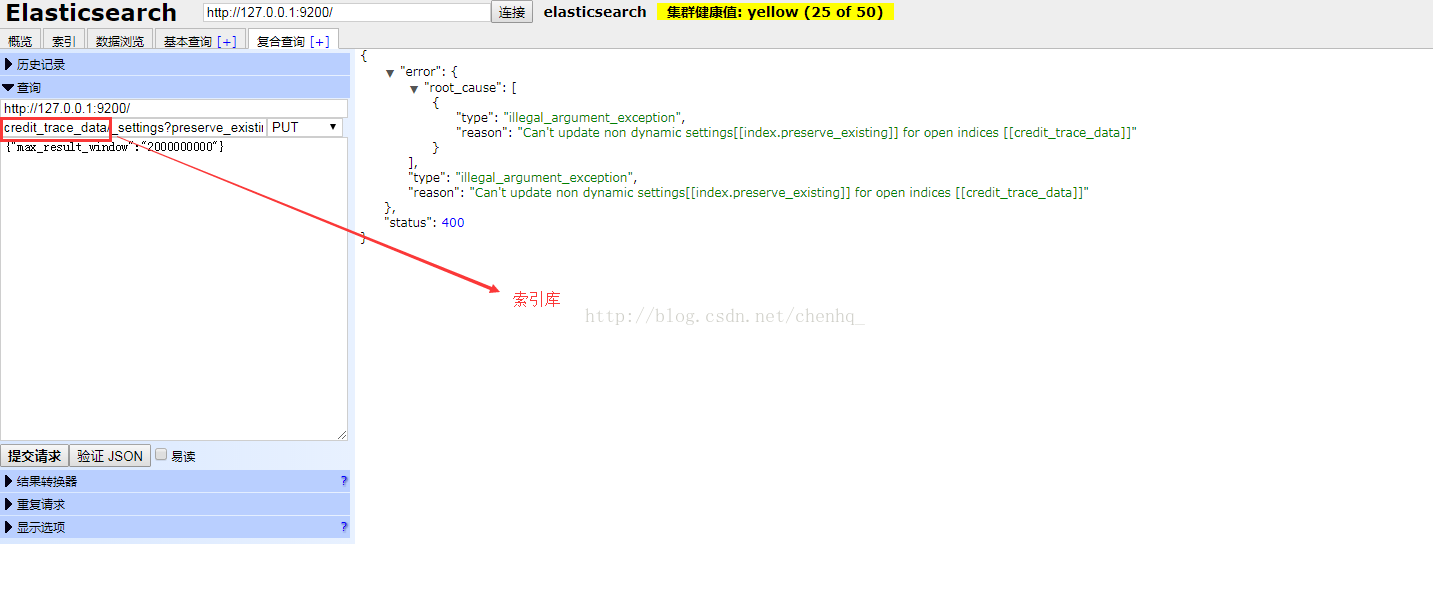
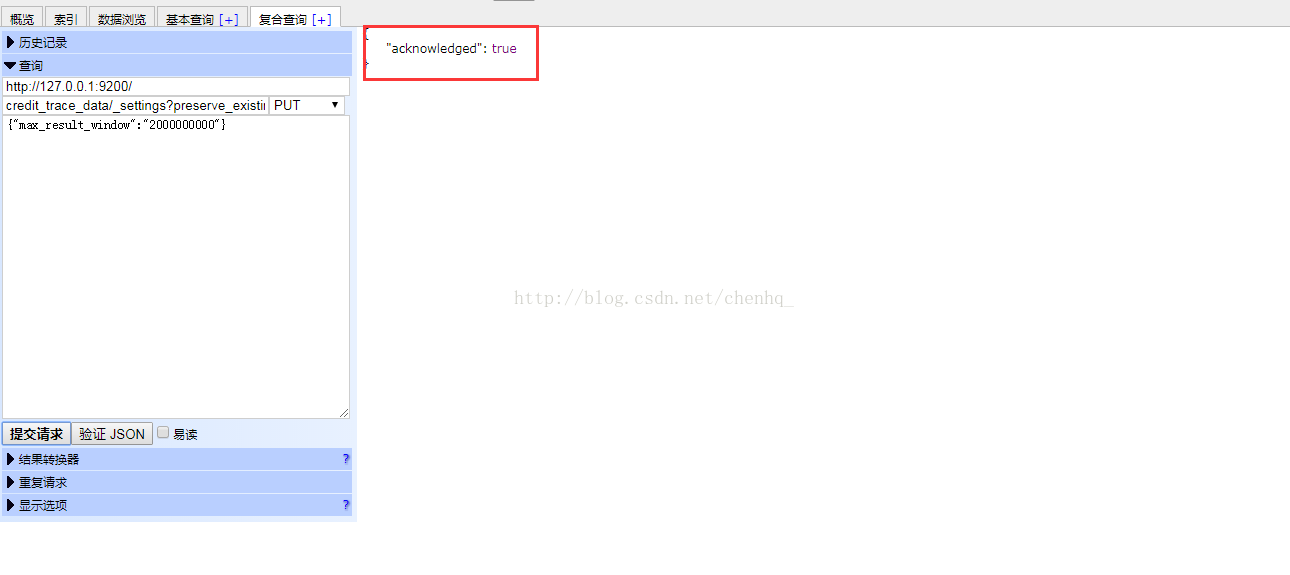
最后点击提交申请,如果配置正确右侧窗口会显示如下信息
如果要查询max_result_window时只需要将PUT改为get即可
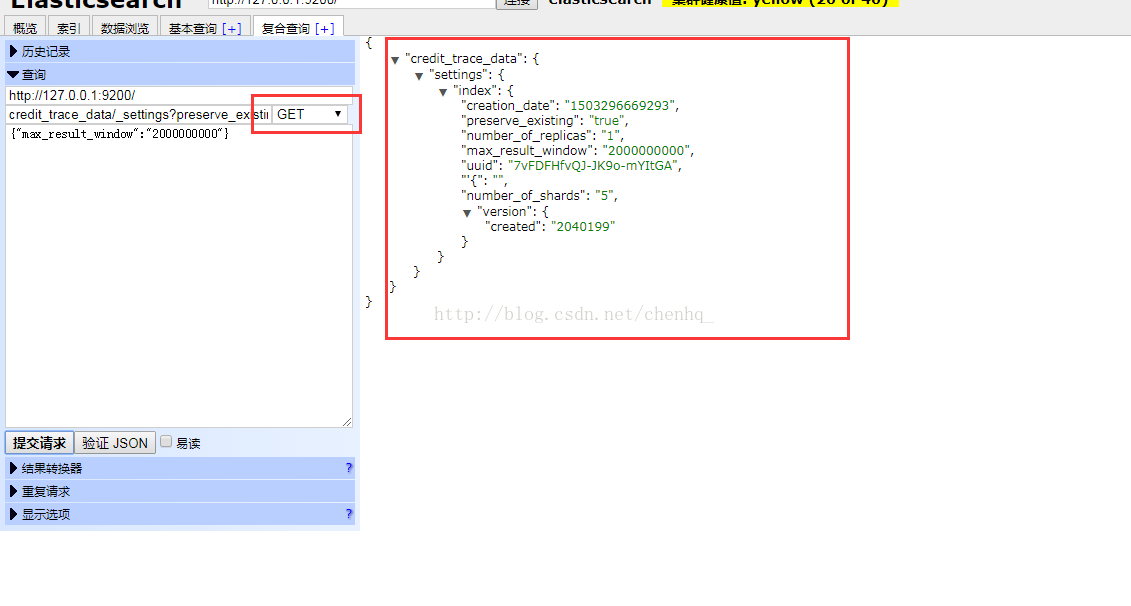
最后记得开启索引!
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索的更多相关文章
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引
第三百六十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引 倒排索引 倒排索引源于实际应用中需要根据属性的值来查找记录.这种索引表中的每一项都包 ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
随机推荐
- HTML5学习笔记(七):CSS盒子模型
在CSS中,盒子模型有W3C标准盒子模型和IE盒子模型两种,这里所谈的是基于W3C标准的盒子模型. 所有HTML元素都可以看作盒子,即所有HTML标签都支持盒子模型的属性,在CSS中,"bo ...
- Windows: 打开关闭网络连接的方法
在Cmd中键入 netsh interface set interface name="本地连接" admin=disablednetsh interface set interf ...
- FFmpeg(6)-通过av_find_best_stream()来获取音视流的索引
也可以通过av_find_best_stream()函数来获取流的索引: 例: audioStream = av_find_best_stream(ic, AVMEDIA_TYPE_AUDIO, -, ...
- CNN及其可解释性
https://stats385.github.io/readings https://arxiv.org/pdf/1311.2901.pdf A Mathematical Theory of Dee ...
- (原创)composite模式和bridge模式是天生的好朋友
composite模式的意图是:将对象组合成树形结构以表示“部分-整体”的层次结构.composite使得用户对单个对象和组合对象的使用具有一致性.它的类图如下: composite模式的实现分为透明 ...
- iOS 10.3.3 更新背后的故事
iOS 10.3.3 更新背后的故事 TLDR:赶紧升级! 苹果最近提示大家将系统升级到 iOS 10.3.3,并且描述这个更新的内容是:修复和改进安全性. iOS 10.3.3 includes b ...
- iOS开发-图片浏览器(优化)
// // ViewController.m // 19-图片浏览器 // // Created by hongqiangli on 2017/7/31. // Copyright © 201 ...
- delphi 学习笔记的例子
由于360改变了共享策略,导致之前的共享连接不能使用 重新共享了下. http://yunpan.cn/cgS2DBRT572jy (提取码:1eda)
- ostream_iterator的可能实现
当我们要输出一个容器的内容时,可以使用std::copy函数,如下: vector <string> myvector; std::copy(myvector.begin(), myvec ...
- LeetCode: Convert Sorted Array to Binary Search Tree 解题报告
Convert Sorted Array to Binary Search Tree Given an array where elements are sorted in ascending ord ...