lightgbm原理以及Python代码
原论文:
http://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
lightgbm原理:
gbdt困点:
gbdt是受欢迎的机器学习算法,当特征维度很高或数据量很大时,有效性和可拓展性没法满足。lightgbm提出GOSS(Gradient-based One-Side Sampling)和EFB(Exclusive Feature Bundling)进行改进。lightgbm与传统的gbdt在达到相同的精确度时,快20倍。
Gradient-based One-Side Sampling (Goss):在GBDT中,数据集没有权重,注意到让不同梯度的数据集在计算信息增益时产生不同的作用。根据信息增益的定义,对于有更大梯度(即训练不足的数据集)将产生更多信息增益。于是,当降低数据集的数据量时,通过保持大梯度的数据集,随机丢掉小梯度的数据集,保持信息增益的准确性。
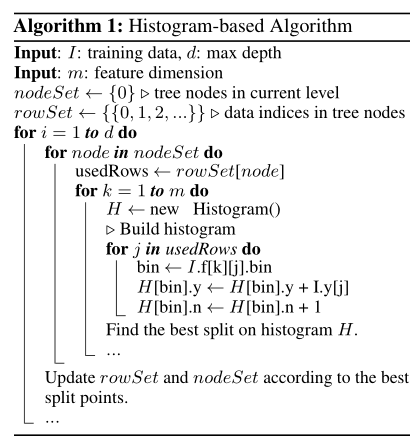

GOSS保持所有具有大梯度的数据集,在小梯度数据集上随机采样。为了抵消对数据分布的影响,GOSS小梯度的样本数据在计算信息增益时引入系数(1-a)/b。具体来说,
- GOSS首先按照数据集的梯度绝对值进行排序,选取最大的a*100%数据集保留;
- 然后从剩余数据集中随机选取b*100%;
- 最后,GOSS对于小梯度乘以常数(1-a)/b放大了样本数据。这样做,我们能不改变原始数据的分布,集中注意力在训练不足的数据上。
收敛分析表明,GOSS算法不会太多降低训练复杂度,并且超越随机选样本。
Exclusive Feature Bundling(EFB). 高维数据通常非常稀疏。特征空间的稀疏性为我们提供了一个设计一种几乎无损的方法来减少特征数量的可能性。具体地说,在一个稀疏的特征空间,许多特征是互斥的,即,它们从不同时取非零值。我们可以安全地将互斥特征捆绑到一个单一的特征中(称之为互斥特征束)。通过精心设计的特征扫描算法,我们可以构建与个体特征类似的基于特征束的特征直方图。这样,直方图构建的复杂性从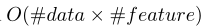 到
到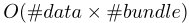 ,其中
,其中 。这样我们可以在不影响准确性情况下大大加快对GBDT的训练。
。这样我们可以在不影响准确性情况下大大加快对GBDT的训练。
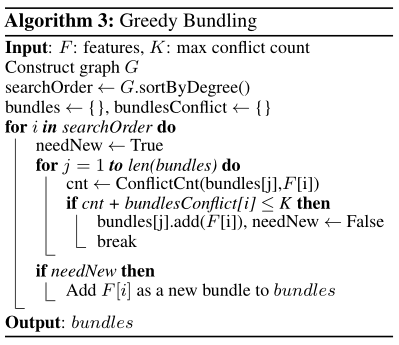

我们的问题对应于图着色问题,反之亦然,因此可以使用贪婪算法来解决。
EFB算法可以将许多互斥性特征捆绑到更少的密集特征上,这可以有效避免了零特征值的不必要计算。事实上,我们也可以通过忽略零特征值,使用表格记录特征非零值的直方图算法。通过扫描表中的数据,直方图构建成本将从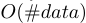 变为
变为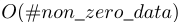 。然而,该方法在树生长过程中需要额外的内存和计算成本来维护这些特征表。我们可以以LightGBM为基本函数按此进行优化。注:这种优化不与EFB冲突,因为我们在捆束稀疏时,依然可以使用它。
。然而,该方法在树生长过程中需要额外的内存和计算成本来维护这些特征表。我们可以以LightGBM为基本函数按此进行优化。注:这种优化不与EFB冲突,因为我们在捆束稀疏时,依然可以使用它。
EFB合并了许多稀疏特征(包括编码特性和隐式互斥性特征),成为少得多的特征。在捆绑过程中包含了基本稀疏特征优化。然而,EFB在树学习过程中为每个特征维护非零数据表,没有额外的成本。更重要的是,因为许多先前孤立的特征被捆绑在一起,它可以增加空间局部性和显著改进缓存命中率。因此,整体效率的提高是引人注目的。以上分析表明,EFB是一种非常有效的在直方图中利用稀疏属性的算法,可以为GBDT训练过程带来显著的加速。
python代码:
import lightgbm
clf=lightgbm
train_matrix = clf.Dataset(tr_x, label=tr_y)
test_matrix = clf.Dataset(te_x, label=te_y)
#z = clf.Dataset(test_x, label=te_y)
#z=test_x
params = {
# 'boosting_type': 'gbdt',
# 'learning_rate': 0.01,
# 'objective': 'binary',
# 'metric': 'auc',
# 'min_child_weight': 1.5,
# 'num_leaves': 2 ** 5,
# 'lambda_l2': 10,
# 'subsample': 0.9,
# 'colsample_bytree': 0.7,
# 'colsample_bylevel': 0.7,
# 'learning_rate': 0.01,
# 'seed': 2017,
# 'nthread': 12,
# 'silent': True,
'task': 'train',
'learning_rate': 0.005,
# 'max_depth': 8,
# 'num_leaves':2**6-1,
'boosting_type': 'gbdt',
'objective': 'binary',
# 'is_unbalance':True,
'feature_fraction': 0.8,
'metric':'auc',
'bagging_fraction': 0.86,
# 'lambda_l1': 0.0001,
'lambda_l2': 49,
'bagging_freq':3,
# 'min_data_in_leaf':5,
'verbose': 1,
'random_state': 2267,
}
num_round = 10000
early_stopping_rounds = 300
if test_matrix:
model = clf.train(params, train_matrix,num_round,valid_sets=test_matrix,
early_stopping_rounds=early_stopping_rounds,verbose_eval=300
)
pre= model.predict(te_x,num_iteration=model.best_iteration).reshape((te_x.shape[0],1))
train[test_index]=pre
test_pre[i, :]= model.predict(test_x, num_iteration=model.best_iteration).reshape((test_x.shape[0],1))
cv_scores.append(roc_auc_score(te_y, pre))
lightgbm原理以及Python代码的更多相关文章
- catboost原理以及Python代码
原论文: http://learningsys.org/nips17/assets/papers/paper_11.pdf catboost原理: One-hot编码可以在预处理阶段或在训练期间 ...
- MD5( 信息摘要算法)的概念原理及python代码的实现
简述: message-digest algorithm 5(信息-摘要算法).经常说的“MD5加密”,就是它→信息-摘要算法. md5,其实就是一种算法.可以将一个字符串,或文件,或压缩包,执行md ...
- KNN算法原理(python代码实现)
kNN(k-nearest neighbor algorithm)算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性 ...
- 【集成学习】:Stacking原理以及Python代码实现
Stacking集成学习在各类机器学习竞赛当中得到了广泛的应用,尤其是在结构化的机器学习竞赛当中表现非常好.今天我们就来介绍下stacking这个在机器学习模型融合当中的大杀器的原理.并在博文的后面附 ...
- 逻辑回归原理(python代码实现)
Logistic Regression Classifier逻辑回归主要思想就是用最大似然概率方法构建出方程,为最大化方程,利用牛顿梯度上升求解方程参数. 优点:计算代价不高,易于理解和实现. 缺点: ...
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
- paip.输入法编程--英文ati化By音标原理与中文atiEn处理流程 python 代码为例
paip.输入法编程--英文ati化By音标原理与中文atiEn处理流程 python 代码为例 #---目标 1. en vs enPHati 2.en vs enPhAtiSmp 3.cn vs ...
- 决策树ID3原理及R语言python代码实现(西瓜书)
决策树ID3原理及R语言python代码实现(西瓜书) 摘要: 决策树是机器学习中一种非常常见的分类与回归方法,可以认为是if-else结构的规则.分类决策树是由节点和有向边组成的树形结构,节点表示特 ...
- 模拟退火算法SA原理及python、java、php、c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径
模拟退火算法SA原理及python.java.php.c++语言代码实现TSP旅行商问题,智能优化算法,随机寻优算法,全局最短路径 模拟退火算法(Simulated Annealing,SA)最早的思 ...
随机推荐
- Python2.7-io
io 模块,用于处理流数据,在 python2 下,是内置 file 对象的另一种选择,在 python3 下,此模块是默认的文件和流数据的接口. 1.模块继承关系 IOBase--RawIOBase ...
- jq插件封装格式
(function($) { // closure $.fn.hilight = function( options ) { //将方法定义在$的fn上 var defaults = { textCo ...
- $\rm{NOIp}$板子整理
怎么说呢,整理这个的目的就是为了有个简约的\(list\),方便以后查阅,复习起来不至于太吃力. 并且--好像重温一遍所有,会更有一些新的认识.这也算是对我所学的一点整理了吧. 一.并查集的两种方式 ...
- sparse linear regression with beta process priors
虽然翻译水平有限,但是看原文虽然看得懂,但是在词汇的问题上,会导致看了后面忘了前面,所以先蹩脚的翻译成中文,然后在仔细思考论文的思想(当然不能翻译成中文就不看英文原本了,得两者一起看,这样不会丢失前面 ...
- 微信小程序开发 [01] 小程序基本结构和官方IDE简介
1.小程序账户注册 实际上在进行开发时没有注册小程序账户也是可以的,官方提供的IDE提供实时编译模拟预览,和当前你有没有绑定小程序账户没有关系. 当然,最终你要正式上线你的小程序的话,肯定还是需要账户 ...
- 批量下载,多文件压缩打包zip下载
0.写在前面的话 图片批量下载,要求下载时集成为一个压缩包进行下载.从昨天下午折腾到现在,踩坑踩得莫名其妙,还是来唠唠,给自己留个印象的同时,也希望给需要用到这个方法的人带来一些帮助. 1.先叨叨IO ...
- Android开发——高斯模糊效果的简单实现
0. 前言 在Android开发中,经常在音乐软件中看到高斯模糊效果. 在找遍了所有高斯模糊的算法代码后,发现stackblur的Java实现是最快的.效果如下所示. 1. 高斯模糊效果实现 Bit ...
- 【Qt】QOpenGLWidget展示蒙版效果
关键代码是派生QOpenGLWidget,覆写paintEvent函数 QPainter p; p.begin(this); p.drawImage(QPoint(, ), m_Img); QLine ...
- Kubernetes学习之路(二十二)之Pod资源调度
目录 Pod资源调度 1.常用的预选策略 2.优选函数 3.节点亲和调度 3.1.节点硬亲和性 3.2.节点软亲和性 4.Pod资源亲和调度 4.1.Pod硬亲和度 4.2.Pod软亲和度 4.3.P ...
- 4.Xilinx RapidIO核详解
转自https://www.cnblogs.com/liujinggang/p/10072115.html 一.RapidIO核概述 RapidIO核的设计标准来源于RapidIO Interconn ...