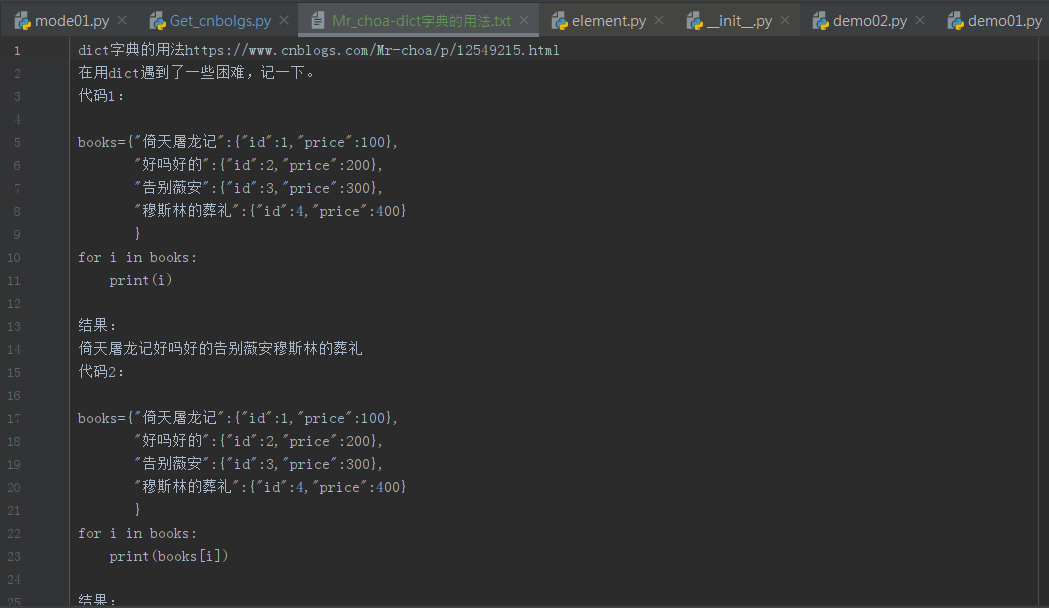
python:爬取博主的所有文章的链接、标题和内容
以爬取我自己的博客为例:https://www.cnblogs.com/Mr-choa/
1、获取所有的文章的链接:

博客文章总共占两页,比如打开第一页:https://www.cnblogs.com/Mr-choa/default.html?page=1的HTML源文件

每篇博客文章的链接都在a标签下,并且具有class属性为"postTitle2",其href属性就指向这篇博文的地址
<a class="postTitle2" href="https://www.cnblogs.com/Mr-choa/p/12615986.html">
简单爬取自己的一篇博客文章
</a>
这样我们可以通过正则表达式获取博文的地址,获取所有的文章的链接就要对博客的页数做一个遍历:
模块代码实现:
# 获取所有的链接
def get_Urls(url,pageNo):
"""
根据url,pageNo,能够返回该博主所有的文章url列表
:param url:
:param pageNo:
:return:
"""
# 创建一个list,用来装博客文章的地址
total_urls=[]
# 对页数做个遍历
for i in range(1,pageNo+1):
# 页数的地址
url_1=url+str(i)
# 获取这一页的全部源代码
html=get_html(url_1)
# 创建一个属性
title_pattern=r'<a.*class="postTitle2".*href="(.*)">'
# 通过正则表达式找到所有相关属性的数据,就是所有的博客文章的链接
urls=re.findall(title_pattern,html)
# 把链接放到list容器内
for url_ in urls:
total_urls.append(url_)
#print(total_urls.__len__())
# 返回所有博客文章的链接
return total_urls
2、获取全部源代码
代码实现:
# 获取网页源码
def get_html(url):
"""
返回对应url的网页源码,经过解码的内容
:param url:
:return:
"""
# 创建一个请求对象
req = urllib.request.Request(url)
# 发起请求,urlopen返回的是一个HTTPResponse对象
resp = urllib.request.urlopen(req)
# 获取HTTP源代码,编码格式为utf-8
html_page = resp.read().decode('utf-8')
# 返回网页源码
return html_page
或者用requests库实现:
def get_html(url):
# 创建一个响应对象
response=requests.get(url)
# 获取整个网页的HTML内容
html_page=response.text
# 返回网页的HTML内容
return html_page
3、获取博客文章的标题
代码实现:
# 获取博客文章的标题
def get_title(url):
'''
获取对应url下文章的标题
:param url:
:return:
'''
# 通过博文的地址获取到源代码
html_page = get_html(url)
# 创建str变量
title_pattern = r'(<a.*id="cb_post_title_url".*>)(.*)(</a>)'
# 匹配到相关的数据
title_match = re.search(title_pattern, html_page)
# 获取标题
title = title_match.group(2)
# 返回标题
return title
4、获取博客文章的所有文本
代码实现:
# 获取博客文章的文本
def get_Body(url):
"""
获取对应url的文章的正文内容
:param url:
:return:
"""
html_page = get_html(url)
soup = BeautifulSoup(html_page, 'html.parser')
div = soup.find(id="cnblogs_post_body")
return div.text
5、保存文章
代码实现:
# 保存文章
def save_file(url):
"""
根据url,将文章保存到本地
:param url:
:return:
"""
title=get_title(url)
body=get_Body(url)
filename="Mr_choa"+'-'+title+'.txt'
with open(filename, 'w', encoding='utf-8') as f:
f.write(title)
f.write(url)
f.write(body)
# 遍历所有的博客文章链接,保存博客的文章
def save_files(url,pageNo):
'''
根据url和pageNo,保存博主所有的文章
:param url:
:param pageNo:
:return:
'''
totol_urls=get_Urls(url,pageNo)
for url_ in totol_urls:
save_file(url_)
显示所有的代码:
import requests
import urllib.request
import re
from bs4 import BeautifulSoup
#该作者的博文一共有多少页
pageNo=2
#后面需要添加页码
url='https://www.cnblogs.com/Mr-choa/default.html?page='
# 获取网页源码
def get_html(url):
"""
返回对应url的网页源码,经过解码的内容
:param url:
:return:
"""
# 创建一个请求对象
req = urllib.request.Request(url)
# 发起请求,urlopen返回的是一个HTTPResponse对象
resp = urllib.request.urlopen(req)
# 获取HTTP源代码,编码格式为utf-8
html_page = resp.read().decode('utf-8')
# 返回网页源码
return html_page '''# 获取网页源代码
def get_html(url):
# 创建一个响应对象
response=requests.get(url)
# 获取整个网页的HTML内容
html_page=response.text
# 返回网页的HTML内容
return html_page
''' # 获取博客文章的标题
def get_title(url):
'''
获取对应url下文章的标题
:param url:
:return:
'''
# 通过博文的地址获取到源代码
html_page = get_html(url)
# 创建str变量
title_pattern = r'(<a.*id="cb_post_title_url".*>)(.*)(</a>)'
# 匹配到相关的数据
title_match = re.search(title_pattern, html_page)
# 获取标题
title = title_match.group(2)
# 返回标题
return title
# 获取博客文章的文本
def get_Body(url):
"""
获取对应url的文章的正文内容
:param url:
:return:
"""
# 通过博客文章的链接,获取博客文章的源代码
html_page = get_html(url)
# 创建对象,基于bs4库HTML的格式输出
soup = BeautifulSoup(html_page, 'html.parser')
# 定义一个soup进行find()方法处理的标签
div = soup.find(id="cnblogs_post_body")
# 返回博客文章内容
return div.text
# 保存文章
def save_file(url):
"""
根据url,将文章保存到本地
:param url:
:return:
"""
title=get_title(url)
body=get_Body(url)
filename="Mr_choa"+'-'+title+'.txt'
with open(filename, 'w', encoding='utf-8') as f:
f.write(title)
f.write(url)
f.write(body)
# 遍历所有的博客文章链接,保存博客的文章
def save_files(url,pageNo):
'''
根据url和pageNo,保存博主所有的文章
:param url:
:param pageNo:
:return:
'''
totol_urls=get_Urls(url,pageNo)
for url_ in totol_urls:
save_file(url_)
# 获取所有的链接
def get_Urls(url,pageNo):
"""
根据url,pageNo,能够返回该博主所有的文章url列表
:param url:
:param pageNo:
:return:
"""
# 创建一个list,用来装博客文章的地址
total_urls=[]
# 对页数做个遍历
for i in range(1,pageNo+1):
# 页数的地址
url_1=url+str(i)
# 获取这一页的全部源代码
html=get_html(url_1)
# 创建一个属性
title_pattern=r'<a.*class="postTitle2".*href="(.*)">'
# 通过正则表达式找到所有相关属性的数据,就是所有的博客文章的链接
urls=re.findall(title_pattern,html)
# 把链接放到list容器内
for url_ in urls:
total_urls.append(url_)
#print(total_urls.__len__())
# 返回所有博客文章的链接
return total_urls
save_files(url,pageNo)
效果:

打开.txt:
参考博客:https://www.cnblogs.com/xingzhui/p/7845675.html
python:爬取博主的所有文章的链接、标题和内容的更多相关文章
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- 爬取博主的所有文章并保存为PDF文件
继续改进上一个项目,上次我们爬取了所有文章,但是保存为TXT文件,查看不方便,而且还无法保存文章中的代码和图片. 所以这次保存为PDF文件,方便查看. 需要的工具: 1.wkhtmltopdf安装包, ...
- 爬取博主所有文章并保存到本地(.txt版)--python3.6
闲话: 一位前辈告诉我大学期间要好好维护自己的博客,在博客园发布很好,但是自己最好也保留一个备份. 正好最近在学习python,刚刚从py2转到py3,还有点不是很习惯,正想着多练习,于是萌生了这个想 ...
- python: 爬取[博海拾贝]图片脚本
练手代码,聊作备忘: # encoding: utf-8 # from __future__ import unicode_literals import urllib import urllib2 ...
- python抓取伯乐在线的全部文章,对标题分词后存入mongodb中
依赖包: 1.pymongo 2.jieba # -*- coding: utf-8 -*- """ @author: jiangfuqiang "" ...
- python爬取凤凰网站的新闻,及其链接地址,来源,时间和内容,用selenium自动化和requests处理数据
有写规则需要自己定义判断. import requests from selenium import webdriver import time def grasp(urlT): driver = w ...
- python 爬取文章
这里我们利用强大的python爬虫来爬取一篇文章.仅仅做一个示范,更高级的用法还要大家自己实践. 好了,这里就不啰嗦了,找到一篇文章的url地址:http://www.duanwenxue.com/a ...
- 使用Python爬取微信公众号文章并保存为PDF文件(解决图片不显示的问题)
前言 第一次写博客,主要内容是爬取微信公众号的文章,将文章以PDF格式保存在本地. 爬取微信公众号文章(使用wechatsogou) 1.安装 pip install wechatsogou --up ...
- 爬虫---lxml爬取博客文章
上一篇大概写了下lxml的用法,今天我们通过案例来实践,爬取我的博客博客并保存在本地 爬取博客园博客 爬取思路: 1.首先找到需要爬取的博客园地址 2.解析博客园地址 # coding:utf-8 i ...
随机推荐
- Rust入坑指南:智能指针
在了解了Rust中的所有权.所有权借用.生命周期这些概念后,相信各位坑友对Rust已经有了比较深刻的认识了,今天又是一个连环坑,我们一起来把智能指针刨出来,一探究竟. 智能指针是Rust中一种特殊的数 ...
- git版本回退问题记录
因为之前有个前端改了文件目录进行合并时候丢失掉些许代码,然后我在以前分支进行了代码层级的整理,项目如果想要启动还需还原回以前的版本,我进行了三次文件夹层级提交,所以我需要进行三次的版本回退. git命 ...
- Vue的模板内换行问题
在用vue的模板{{}}进行渲染文本时候,字符串换行不起作用,后使用ES6的模板字符串进行换行仍然不起作用,解决方法: <div>{{str}}</div> 可换为用v-htm ...
- openwrt MT7620A MT7610E 5G 驱动添加移值
使用 github 上别人提供好的源码.整合到最新的 openwrt 18 中,目前 kernel 的版本为 4.1 . 编辑中....
- openwrt 上的 upnp wifi 音频推送 gmediarender
首先是必须启用的模块 Libraries ---> <*> libupnp Sound ---> <*> alsa-utils<*> madplay-a ...
- 「从零单排HBase 06」你必须知道的HBase最佳实践
前面,我们已经打下了很多关于HBase的理论基础,今天,我们主要聊聊在实际开发使用HBase中,需要关注的一些最佳实践经验. 1.Schema设计七大原则 1)每个region的大小应该控制在10G到 ...
- [日志分析]Graylog2采集Nginx日志 被动方式
graylog可以通过两种方式采集nginx日志,一种是通过Graylog Collector Sidecar进行采集(主动方式),另外是通过修改nginx配置文件的方式进行收集(被动方式). 这次说 ...
- (转)协议森林12 天下为公 (TCP堵塞控制)
协议森林12 天下为公 (TCP堵塞控制) 作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 在TCP协议中,我们使用连接记录TCP ...
- 聊聊order by的工作机制
总结写在前面: 1. 介绍了orderBy的两种算法流程:全字段排序 和 rowid排序. 2. rowid排序 相比 全字段排序,参与排序字段较少,耗内存较少,多一步回表,如果内存够的情况下MySQ ...
- NIO中的ZeroCopy
前文提到网络IO可以使用多路复用技术,而文件IO无法使用多路复用,但是文件IO可以通过减少底层数据拷贝的次数来提升性能,而这个减少底层数据拷贝次数的技术,就叫做ZeroCopy. 操作系统层面的Zer ...