1.scrapy框架
Scrapy 是一个基于 Twisted 的异步处理框架。异步就是说调用在发出之后,这个调用就直接返回,不管有没有结果。(非阻塞关注的是程序在等待调用结果(消息、返回值)时的状态,指在不能立刻得到结果之前,不会阻塞当前线程。)
1.scrapy架构
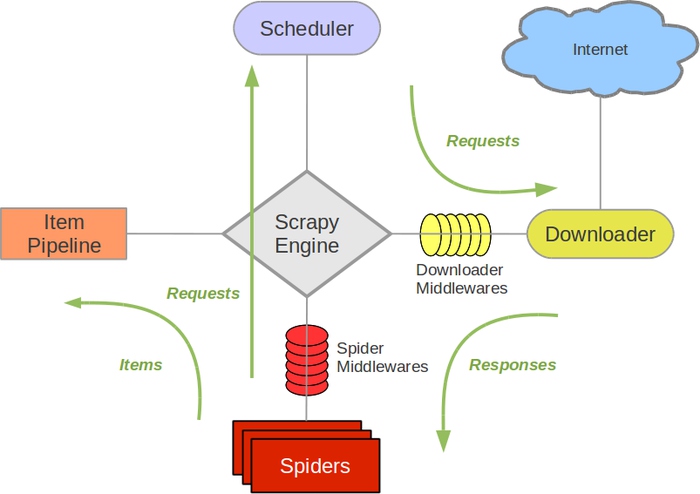
Engine,引擎,用来处理整个系统的数据流处理,触发事务,是整个框架的核心。引擎相当于总指挥,负责数据和信号在不同模块之间的传递。
Scheduler, 调度器,用来接受引擎发过来的请求并加入队列中,并在引擎再次请求的时候提供给引擎。调度器本质是个队列,存放引擎发过来的requestq请求。
Downloader,下载器,用于下载网页内容(request请求来源于引擎),并返回给引擎。
Item,项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该对象。
Spiders,蜘蛛,其内定义了爬取的逻辑和网页的解析规则,处理引擎发来的response,提取数据和url,并返回给引擎。
Item Pipeline,项目管道,负责处理引擎传来的数据,它的主要任务是清洗、验证和存储数据。
Downloader Middlewares,下载器中间件,位于引擎和下载器之间的钩子框架,主要是处理引擎与下载器之间的请求及响应。可以自定义下载扩展,比如设置代理。
Spider Middlewares, 蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛输入的响应和输出的结果及新的请求。可以自定义request请求和过滤response。
2.工作流程
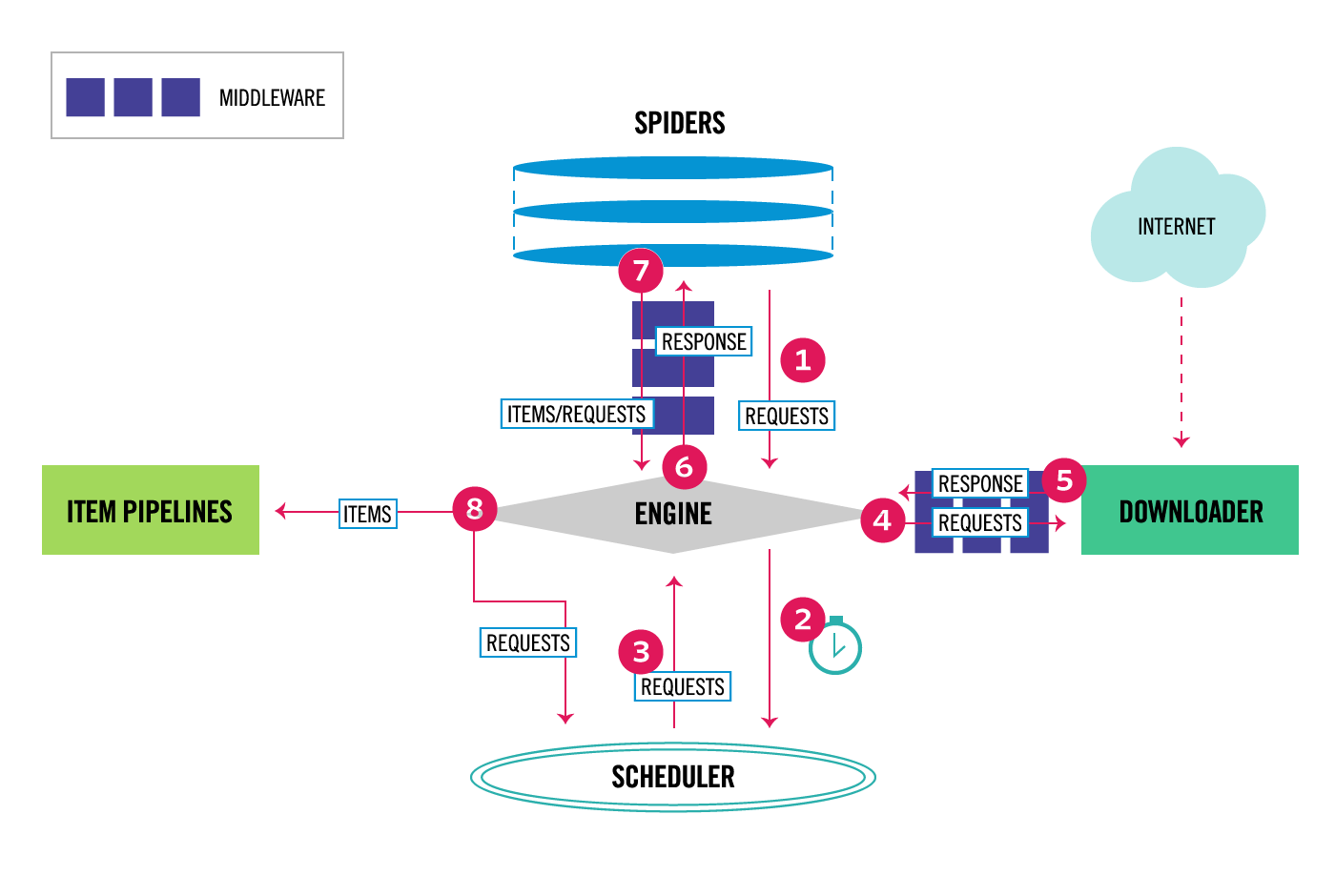
Engine 首先打开一个网站,找到处理该网站的 Spider 并向该 Spider 请求初始URL。
Spider将需要发送请求的url经ScrapyEngine(引擎)交给Scheduler(调度器)。
Scheduler(排序,入队)处理后,返回下一个要爬取的 URL 给 Engine,Engine 将 URL 通过 Downloader Middlewares 转发给 Downloader 下载。
一旦页面下载完毕, Downloader 生成一个该页面的 Response,并将其通过 Downloader Middlewares 发送给 Engine。
Engine 从下载器中接收到 Response 并通过 Spider Middlewares 发送给 Spider 处理。
Spider 处理 Response 并返回爬取到的 Item 及新的 Request 给 Engine。
Engine 将 Spider 返回的 Item 给 Item Pipeline,将新的 Request 给 Scheduler。
重复以上步骤,直到 Scheduler 中没有更多的 Request,Engine 关闭该网站,爬取结束
1.scrapy框架的更多相关文章
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Scrapy框架使用—quotesbot 项目(学习记录一)
一.Scrapy框架的安装及相关理论知识的学习可以参考:http://www.yiibai.com/scrapy/scrapy_environment.html 二.重点记录我学习使用scrapy框架 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- 一个scrapy框架的爬虫(爬取京东图书)
我们的这个爬虫设计来爬取京东图书(jd.com). scrapy框架相信大家比较了解了.里面有很多复杂的机制,超出本文的范围. 1.爬虫spider tips: 1.xpath的语法比较坑,但是你可以 ...
- 安装scrapy框架的常见问题及其解决方法
下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助. 常见问题一:pip版本需要升级 如果你的pip版本比较老,可能在安装的过程 ...
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
- 利用scrapy框架进行爬虫
今天一个网友问爬虫知识,自己把许多小细节都忘了,很惭愧,所以这里写一下大概的步骤,主要是自己巩固一下知识,顺便复习一下.(scrapy框架有一个好处,就是可以爬取https的内容) [爬取的是杨子晚报 ...
随机推荐
- 正则表达式(grep,awk,sed)和通配符
1. 正则表达式 1. 什么是正则表达式? 正则表达式就是为了处理大量的字符串而定义的一套规则和方法. 通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤,替换或输出需要的字符串. Linux正则 ...
- vuex vue-devtools 安装
vue-devtools是一款基于chrome游览器的插件,用于调试vue应用,这可以极大地提高我们的调试效率.接下来我们就介绍一下vue-devtools的安装 chrome商店直接安装 谷歌访问助 ...
- 《PostgreSQL服务器编程》一一1.3 超越简单函数
本节书摘来自华章计算机<PostgreSQL服务器编程>一书中的第1章,第1.3节,作者:(美)Hannu Krosing, Jim Mlodgenski, Kirk Roybal 著,更 ...
- 我想solo自己一个人!
区域赛之后你就该走了,现在你告诉我,没精力不打了,我真谢谢你! 今年就TM的没有一点舒心的地方! 父母分居, 队友出走, 队伍解散, 白天家里两个外甥很吵, 鼻窦炎复发, 喜欢的妹子也追不到, 整夜失 ...
- 2019 ICPC 南京网络赛 F Greedy Sequence
You're given a permutation aa of length nn (1 \le n \le 10^51≤n≤105). For each i \in [1,n]i∈[1,n], c ...
- 跟哥一起学python(2)- 运行第一个python程序&环境搭建
本节的任务,是完成我们的第一个python程序,并搭建好学习python的环境. 建议通过视频来学习本节内容: 查看本节视频 再次看看上一节提到的那张图,看看作为高级编程语言,我们如何编程. 首先, ...
- CtsSecurityTestCases#ListeningPortsTest定位tcp端口与pid
CtsSecurityTestCases#ListeningPortsTest定位tcp端口与pid [问题描述] cts失败项 armeabi-v7a CtsSecurityTestCases an ...
- LateX的简单字体设置(颜色,居中,大小等)
\(\color{red}{Ⅰ.文本单行居中}\) $$\text{我是蒟蒻}$$ \[\text{我是蒟蒻} \] \(\color{Black}{Ⅱ.设置字体颜色}\) $$\color{Purp ...
- Java流式思想和方法引用
目录 Java流式思想和方法引用 1. Stream流 1.1 概述 传统集合的多步遍历代码 Stream的更优写法 1.2 流式思想的概述 1.3 获取流 1.4 常用方法 ①逐一处理:forEac ...
- STM32 串口USART DMA方式发送接收数据
硬件:stm32f103cbt6 软件:STM32F10x_StdPeriph_Lib_V3.5.0 文章目录 头文件 USART3_DR的地址 DMA的通道 DMA的中断 USART接收回调函数 头 ...