python爬取酷狗音乐
我们随便访问一个歌曲可以看到url有个hash
https://www.kugou.com/song/#hash=AC9D859362CABB2092AEAA39A072606A&album_id=39211957
但是这个hash是可以得到的

import re
import requests
import json
headers = {
'cookie': 'kg_mid=7a7f50715e7cbc43187cb14650a074d7; ACK_SERVER_10015=%7B%22list%22%3A%5B%5B%22gzlogin-user.kugou.com%22%5D%5D%7D; ACK_SERVER_10016=%7B%22list%22%3A%5B%5B%22gzreg-user.kugou.com%22%5D%5D%7D; ACK_SERVER_10017=%7B%22list%22%3A%5B%5B%22gzverifycode.service.kugou.com%22%5D%5D%7D; kg_dfid=2lP8Vp1RHLHj0wmucn0XlXFL; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1600062203; kg_mid_temp=7a7f50715e7cbc43187cb14650a074d7; KuGooRandom=66401600062231494; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1600062409',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
hash_com = re.compile('"Hash":"(.*?)"',re.I|re.S)
html = requests.get('https://www.kugou.com/yy/html/rank.html',headers=headers)
hash_result = hash_com.findall(html.text)
print(hash_result)
然后我们刷新歌曲这里得网页可以看到都是在这里
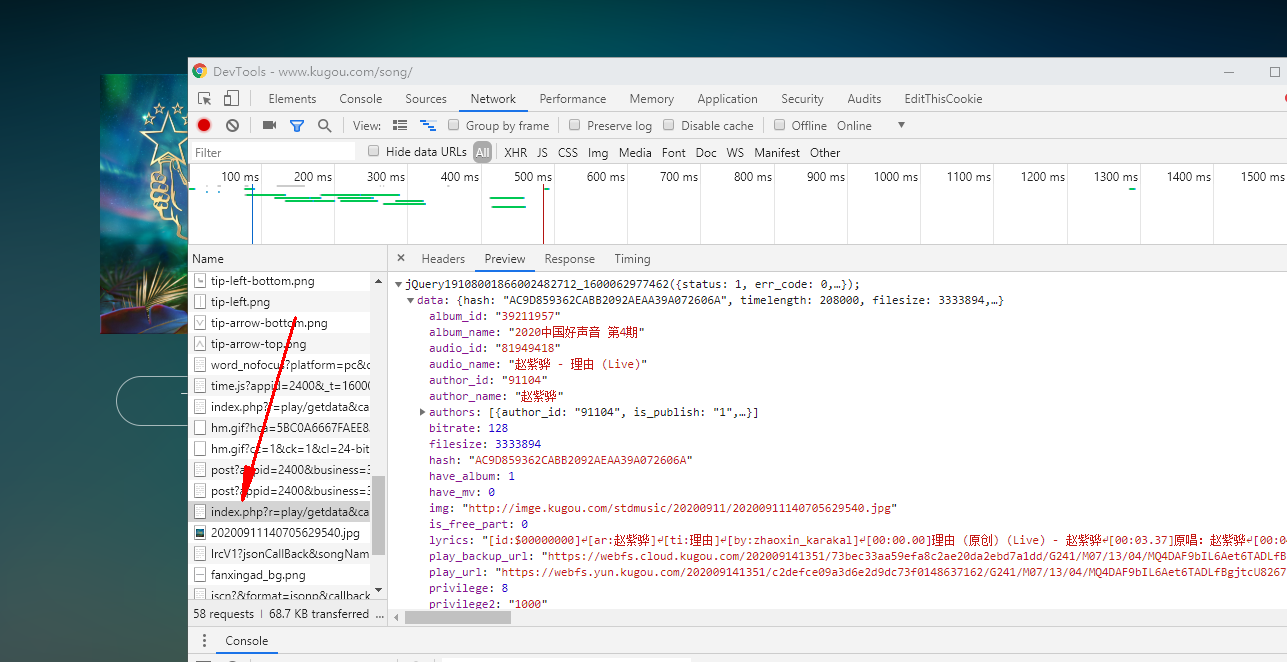
然后我敲门只留hash前面看看能不能访问
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19108001866002482712_1600062977462&hash=AC9D859362CABB2092AEAA39A072606A
访问是可以的
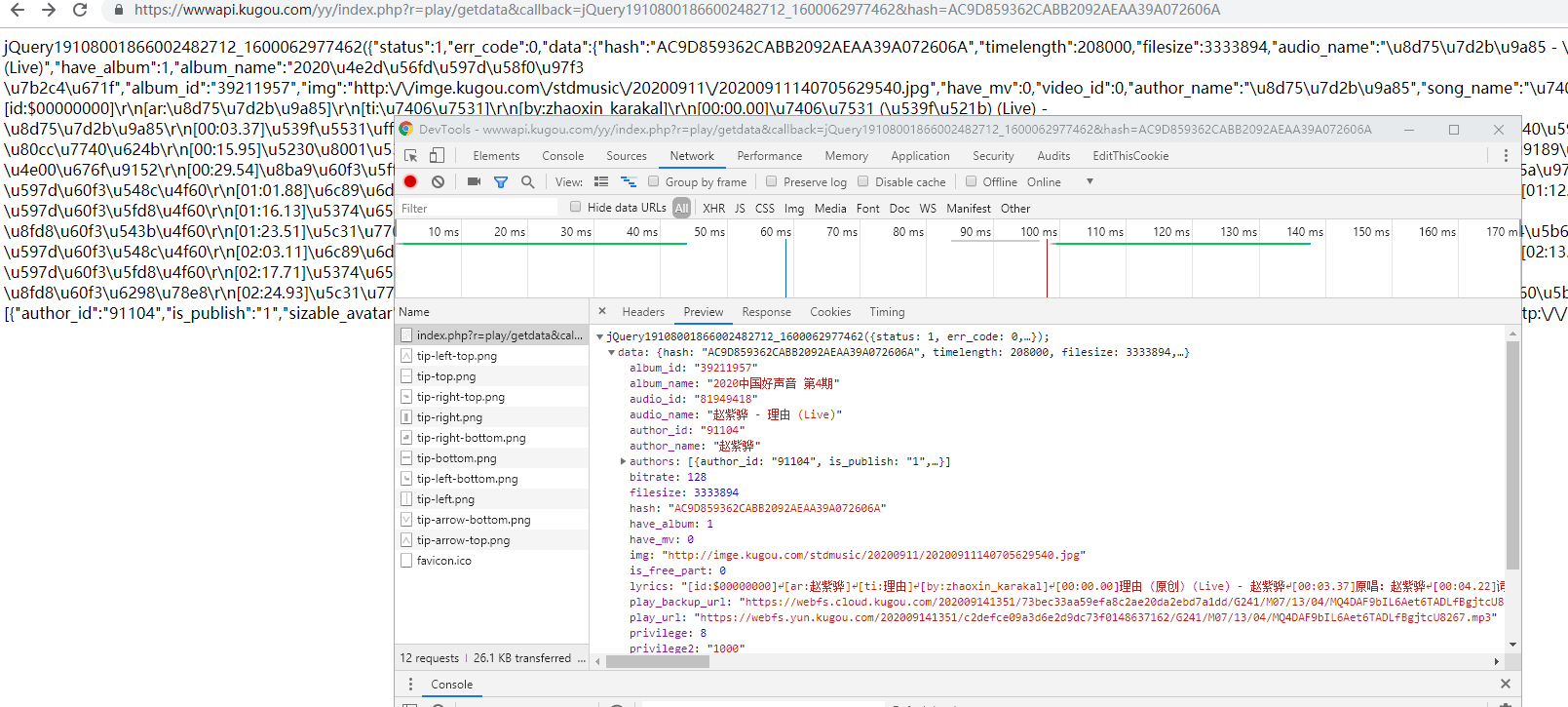
然后我们再拼接一下
import re
import requests
import json
headers = {
'cookie': 'kg_mid=7a7f50715e7cbc43187cb14650a074d7; ACK_SERVER_10015=%7B%22list%22%3A%5B%5B%22gzlogin-user.kugou.com%22%5D%5D%7D; ACK_SERVER_10016=%7B%22list%22%3A%5B%5B%22gzreg-user.kugou.com%22%5D%5D%7D; ACK_SERVER_10017=%7B%22list%22%3A%5B%5B%22gzverifycode.service.kugou.com%22%5D%5D%7D; kg_dfid=2lP8Vp1RHLHj0wmucn0XlXFL; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1600062203; kg_mid_temp=7a7f50715e7cbc43187cb14650a074d7; KuGooRandom=66401600062231494; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1600062409',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
hash_com = re.compile('"Hash":"(.*?)"',re.I|re.S)
html = requests.get('https://www.kugou.com/yy/html/rank.html',headers=headers)
hash_result = hash_com.findall(html.text)
# print(hash_result)
base_url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19108001866002482712_1600062977462&hash='
for hash in hash_result:
url = base_url+hash
# print(url)
然后再获取url
jsondata = requests.get(url,headers=headers)
print(jsondata.text)
输出为

我们来.json()看看
print(jsondata.json())
但是返回错误了,所以不是一个合法json,来转换一下,通过find来找到合法的json头部和尾部
他的合法开头再这里

结尾就是 .mp3"}}
start = jsondata.text.find('{"status":1')
end = jsondata.text.find('.mp3"}}')+len('.mp3"}}')
print(jsondata.text[start:end])
这里加上len就是因为[]是左闭右合的,返回

全部代码
import re
import requests
import json
import os
headers = {
'cookie': 'kg_mid=7a7f50715e7cbc43187cb14650a074d7; ACK_SERVER_10015=%7B%22list%22%3A%5B%5B%22gzlogin-user.kugou.com%22%5D%5D%7D; ACK_SERVER_10016=%7B%22list%22%3A%5B%5B%22gzreg-user.kugou.com%22%5D%5D%7D; ACK_SERVER_10017=%7B%22list%22%3A%5B%5B%22gzverifycode.service.kugou.com%22%5D%5D%7D; kg_dfid=2lP8Vp1RHLHj0wmucn0XlXFL; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1600062203; kg_mid_temp=7a7f50715e7cbc43187cb14650a074d7; KuGooRandom=66401600062231494; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1600062409',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
hash_com = re.compile('"Hash":"(.*?)"',re.I|re.S)
html = requests.get('https://www.kugou.com/yy/html/rank.html',headers=headers)
hash_result = hash_com.findall(html.text)
# print(hash_result)
base_url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19108001866002482712_1600062977462&hash='
for hash in hash_result:
url = base_url+hash
# print(url)
jsondata = requests.get(url,headers=headers)
start = jsondata.text.find('{"status":1')
end = jsondata.text.find('.mp3"}}')+len('.mp3"}}')
# print(jsondata.text[start:end])
songurl = json.loads(jsondata.text[start:end])['data']['play_url']
title = json.loads(jsondata.text[start:end])['data']['audio_name']
if not os.path.exists('酷狗'):
os.mkdir('酷狗')
with open('酷狗/{}.mp3'.format(title),'wb')as f:
f.write(requests.get(songurl).content)

python爬取酷狗音乐的更多相关文章
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- Python爬取酷狗飙升榜前十首(100)首,写入CSV文件
酷狗飙升榜,写入CSV文件 爬取酷狗音乐飙升榜的前十首歌名.歌手.时间,是一个很好的爬取网页内容的例子,对爬虫不熟悉的读者可以根据这个例子熟悉爬虫是如何爬取网页内容的. 需要用到的库:requests ...
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- 使用scrapy 爬取酷狗音乐歌手及歌曲名并存入mongodb中
备注还没来得及写,共爬取八千多的歌手,每名歌手平均三十首歌曲算,大概二十多万首歌曲 run.py #!/usr/bin/env python # -*- coding: utf-8 -*- __aut ...
- 【Python】【爬虫】爬取酷狗音乐网络红歌榜
原理:我的上篇博客 import requests import time from bs4 import BeautifulSoup def get_html(url): ''' 获得 HTML ' ...
- 【Python】【爬虫】爬取酷狗TOP500
好啦好啦,那我们来拉开我们的爬虫之旅吧~~~ 这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的. 环境配置 在此之前需要下载一个谷 ...
- htmlunit+fastjson抓取酷狗音乐 qq音乐链接及下载
上次学了jsoup之后,发现一些动态生成的网页内容是无法抓取的,于是又学习了htmlunit,下面是抓取酷狗音乐与qq音乐链接的例子: 酷狗音乐: import java.io.BufferedInp ...
- 使用Xpath爬取酷狗TOP500的歌曲信息
使用xpath爬取酷狗TOP500的歌曲信息, 将排名.歌手名.歌曲名.歌曲时长,提取的结果以文件形式保存下来.参考网址:http://www.kugou.com/yy/rank/home/1-888 ...
随机推荐
- 分块练习C. interval
分块练习C. interval 题目描述 \(N\)个数\(a_i\),\(m\)个操作 \(1\). 从第一个数开始,每隔\(k_i\)个的位置上的数增加\(x_i\) \(2\). 查询\(l\) ...
- 第三篇Scrum冲刺博客--Interesting-Corps
第三篇Scrum冲刺博客 站立式会议 1.会议照片 2.队友完成情况 团队成员 昨日完成 今日计划 鲍鱼铭 主页页面跳转社区功能及社区设计及布局实现 搜索页面跳转.设计及布局实现 叶学涛 编写个人页面 ...
- [转]camera的构成
camera的构成 拍摄景物通过镜头,将生成的光学图像投射到传感器上,然后光学图像被转换成电信号,电信号再经过模数转换变为数字信号,数字信号经过DSP加工处理,再被送到电脑中进行处理,最终转换成手机屏 ...
- php实现视频拍照上传头像功能实例代码
如果要在php中实现视频拍照我们需要借助于flash插件了,由flash拍出的确照片我们再通过php的$GLOBALS ['HTTP_RAW_POST_DATA']接受数据,然后保存成图片就可以了,下 ...
- Java数据结构——双端队列
双端队列(Deque)双端队列是指允许两端都可以进行入队和出队操作的队列,其元素的逻辑结构仍是线性结构.将队列的两端分别称为前端和后端,两端都可以入队和出队.Deque继承自Queue接口,Deque ...
- 90%的开发都没搞懂的CI和CD!
据IDC统计,2017年,DevOps的全球软件市场已达到约39亿美元的水平,预计到2022年市场将达到80亿美元左右! 在敏捷软件开发环境中,工作模型和操作需要对公司不断变化的需求具有超级灵活的能力 ...
- FinalShell远程连接工具推荐
今天给大家推荐一个类似Xshell的工具FinalShell,这个工具也使用了很长时间了, Windows和Mac版本都有,方便连接虚拟机 可以很方便的上传文件,有兴趣可以试试这款软件. 地址:htt ...
- 分享一个FileUtil工具类,基本满足web开发中的文件上传,单个文件下载,多个文件下载的需求
获取该FileUtil工具类具体演示,公众号内回复fileutil20200501即可. package com.example.demo.util; import javax.servlet.htt ...
- SEO需要分析哪些网站数据
http://www.wocaoseo.com/thread-227-1-1.html 一.网站的基本数据 1.网站流量详情(ip.pv.需要看pv与ip的比) 2.网站的跳出率(可以看出一个网站的用 ...
- GA教程:使用自定义变量来扩展高级细分
http://www.wocaoseo.com/thread-64-1-1.html 您可以使用自定义变量来扩展高级细分的范围. 高级细分依据的标准是用户的会话(访问)数据.如果某个访问者在指定日期范 ...