入门大数据---Hive计算引擎Tez简介和使用
一、前言
Hive默认计算引擎时MR,为了提高计算速度,我们可以改为Tez引擎。至于为什么提高了计算速度,可以参考下图:
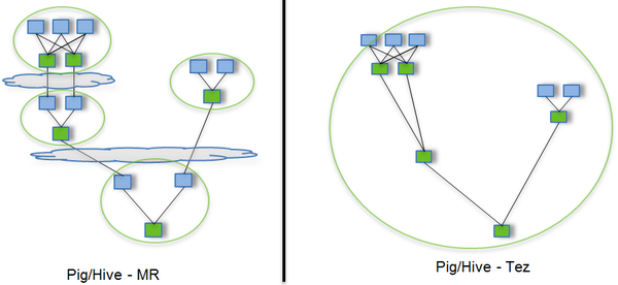
用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Reduce Task,云状表示写屏蔽,需要将中间结果持久化写到HDFS。
Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。
二、安装包准备
1)下载tez的依赖包:http://tez.apache.org
2)拷贝apache-tez-0.9.1-bin.tar.gz到hadoop102的/opt/module目录
[root@hadoop102 module]$ ls
apache-tez-0.9.1-bin.tar.gz
3)解压缩apache-tez-0.9.1-bin.tar.gz
[root@hadoop102 module]$ tar -zxvf apache-tez-0.9.1-bin.tar.gz
4)修改名称
[root@hadoop102 module]$ mv apache-tez-0.9.1-bin/ tez-0.9.1
三、在Hive中配置Tez
1)进入到Hive的配置目录:/opt/module/hive/conf
[root@hadoop102 conf]$ pwd
/opt/module/hive/conf
2)在hive-env.sh文件中添加tez环境变量配置和依赖包环境变量配置
[root@hadoop102 conf]$ vim hive-env.sh
添加如下配置
# Set HADOOP_HOME to point to a specific hadoop install directory
export HADOOP_HOME=/opt/module/hadoop-2.7.2
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/module/hive/conf
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
export TEZ_HOME=/opt/module/tez-0.9.1 #是你的tez的解压目录
export TEZ_JARS=""
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done
export HIVE_AUX_JARS_PATH=/opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20.jar$TEZ_JARS
3)在hive-site.xml文件中添加如下配置,更改hive计算引擎
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
四、配置Tez
1)在Hive的/opt/module/hive/conf下面创建一个tez-site.xml文件
[root@hadoop102 conf]$ pwd
/opt/module/hive/conf
[root@hadoop102 conf]$ vim tez-site.xml
添加如下内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name> <value>${fs.defaultFS}/tez/tez-0.9.1,${fs.defaultFS}/tez/tez-0.9.1/lib</value>
</property>
<property>
<name>tez.lib.uris.classpath</name> <value>${fs.defaultFS}/tez/tez-0.9.1,${fs.defaultFS}/tez/tez-0.9.1/lib</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.history.logging.service.class</name> <value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
</configuration>
五、上传Tez到集群
1)将/opt/module/tez-0.9.1上传到HDFS的/tez路径
[root@hadoop102 conf]$ hadoop fs -mkdir /tez
[root@hadoop102 conf]$ hadoop fs -put /opt/module/tez-0.9.1/ /tez
[root@hadoop102 conf]$ hadoop fs -ls /tez
/tez/tez-0.9.1
六、测试
1)启动Hive
[root@hadoop102 hive]$ bin/hive
2)创建LZO表
hive (default)> create table student(
id int,
name string);
3)向表中插入数据
hive (default)> insert into student values(1,"zhangsan");
4)如果没有报错就表示成功了
hive (default)> select * from student;
1 zhangsan
七、小结
1)运行Tez时检查到用过多内存而被NodeManager杀死进程问题:
Caused by: org.apache.tez.dag.api.SessionNotRunning: TezSession has already shutdown. Application application_1546781144082_0005 failed 2 times due to AM Container for appattempt_1546781144082_0005_000002 exited with exitCode: -103
For more detailed output, check application tracking page:http://hadoop103:8088/cluster/app/application_1546781144082_0005Then, click on links to logs of each attempt.
Diagnostics: Container [pid=11116,containerID=container_1546781144082_0005_02_000001] is running beyond virtual memory limits. Current usage: 216.3 MB of 1 GB physical memory used; 2.6 GB of 2.1 GB virtual memory used. Killing container.
这种问题是从机上运行的Container试图使用过多的内存,而被NodeManager kill掉了。
[摘录] The NodeManager is killing your container. It sounds like you are trying to use hadoop streaming which is running as a child process of the map-reduce task. The NodeManager monitors the entire process tree of the task and if it eats up more memory than the maximum set in mapreduce.map.memory.mb or mapreduce.reduce.memory.mb respectively, we would expect the Nodemanager to kill the task, otherwise your task is stealing memory belonging to other containers, which you don't want.
解决方法:
方案一:或者是关掉虚拟内存检查。我们选这个,修改yarn-site.xml
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
方案二:mapred-site.xml中设置Map和Reduce任务的内存配置如下:(value中实际配置的内存需要根据自己机器内存大小及应用情况进行修改)
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
入门大数据---Hive计算引擎Tez简介和使用的更多相关文章
- 一文让你彻底了解大数据实时计算引擎 Flink
前言 在上一篇文章 你公司到底需不需要引入实时计算引擎? 中我讲解了日常中常见的实时需求,然后分析了这些需求的实现方式,接着对比了实时计算和离线计算.随着这些年大数据的飞速发展,也出现了不少计算的框架 ...
- 《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门.概念.原理.实战.性能调优.系统案例的讲解. 专栏介绍 扫码下面专栏二维码可以订阅该专栏 首发地址:http://www.54tianzhisheng. ...
- 入门大数据---Hive是什么?
这篇文章主要介绍Hive的概念. 简介: Hive中文名叫数据仓库管理系统,之前我们操作MapReduce必须通过编写代码或者通过特殊命令来实现,有了Hive我们通过常用的SQL语句就能操作MapRe ...
- 入门大数据---Hive分区表和分桶表
一.分区表 1.1 概念 Hive 中的表对应为 HDFS 上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大. 分区为 HDFS 上表目录的子目录,数据按照分区存储在子 ...
- 入门大数据---Hive数据查询详解
一.数据准备 为了演示查询操作,这里需要预先创建三张表,并加载测试数据. 数据文件 emp.txt 和 dept.txt 可以从本仓库的resources 目录下载. 1.1 员工表 -- 建表语句 ...
- 入门大数据---Hive的搭建
本博客主要介绍Hive和MySql的搭建: 学习视频一天就讲完了,我看完了自己搭建MySql遇到了一堆坑,然后花了快两天才解决完,终于把MySql搭建好了.然后又去搭建Hive,又遇到了很多坑,就这 ...
- 入门大数据---Hive视图和索引
一.视图 1.1 简介 Hive 中的视图和 RDBMS 中视图的概念一致,都是一组数据的逻辑表示,本质上就是一条 SELECT 语句的结果集.视图是纯粹的逻辑对象,没有关联的存储 (Hive 3.0 ...
- 入门大数据---Hive常用DDL操作
一.Database 1.1 查看数据列表 show databases; 1.2 使用数据库 USE database_name; 1.3 新建数据库 语法: CREATE (DATABASE|SC ...
- 入门大数据---Hive常用DML操作
Hive 常用DML操作 一.加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename ...
随机推荐
- vue父路由高亮不显示
vue父路由高亮不显示 首页和考试中心作为父路由,点击时发现不高亮,是因为路由配置有问题 因为首页和考试中心已经重定向到homepage和tpersonal-data这两个路由,当点击首页和考试中心的 ...
- 阿里面试官最喜欢问的21个HashMap面试题
1.HashMap 的数据结构? A:哈希表结构(链表散列:数组+链表)实现,结合数组和链表的优点.当链表长度超过 8 时,链表转换为红黑树. transient Node<K,V>\[\ ...
- 解决github打不开问题
2020.06.22 使用以下方式: 在https://github.com.ipaddress.com/找到: 在https://fastly.net.ipaddress.com/github.gl ...
- 第七模块 :微服务监控告警Prometheus架构和实践
119.监控模式分类~1.mp4 logging:日志监控,Logging 的特点是,它描述一些离散的(不连续的)事件. 例如:应用通过一个滚动的文件输出 Debug 或 Error 信息,并通过日志 ...
- activiti学习笔记一
activiti学习笔记 在讲activiti之前我们必须先了解一下什么是工作流,什么是工作流引擎. 在我们的日常工作中,我们会碰到很多流程化的东西,什么是流程化呢,其实通俗来讲就是有一系列固定的步骤 ...
- Day12-微信小程序实战-交友小程序-搭建服务器与上传文件到后端
要搞一个小型的cms内容发布系统 因为小程序上线之后,直接对数据库进行操作的话,慧出问题的,所以一般都会做一个管理系统,让工作人员通过这个管理系统来对这个数据库进行增删改查 微信小程序其实给我们提供了 ...
- linux下将多个ts文件合并为一个MP4文件
1. 安装ffmpeg工具 sudo apt install ffmpeg 2. 确保所有ts文件无损坏后,确保当前目录(即存放ts文件的目录)无txt文件及mp4文件,在存放ts文件的目录下建立te ...
- mysql 主键自增设置,插入数据就不必再设置了。
(完)
- VScode和IntelliJ IDEA设置自动换行
VScode自动换行 点击左上角的File-->Auto Save即可实现多文件的自动换行; IDEA自动换行 点击左侧空白处,选择Soft-Wrap就是当前文件自动换行,选择Configure ...
- 移动端1px像素解决方式,从1px像素问题剖析像素及viewport
在移动端web开发过程中,如果你对边框设置border:1px,会发现,边框在某些手机机型上面显示的1px比实际感觉会变粗,这也就是1像素问题.如下图是对桌面浏览器和移动端border设置1px的比较 ...