MySQL_Explain详解
MYSQL_01Explain详解与索引实践 思维导图模板_ProcessOn思维导图、流程图
https://www.processon.com/view/629d5405e0b34d3bc3b28f04

DROP TABLE IF EXISTS `departments`;
CREATE TABLE `departments` (
`id` int(0) NOT NULL,
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of departments
-- ----------------------------
INSERT INTO `departments` VALUES (1, 'Human Resources');
INSERT INTO `departments` VALUES (2, 'Marketing');
INSERT INTO `departments` VALUES (3, 'Finance');
DROP TABLE IF EXISTS `departments_employees`;
CREATE TABLE `departments_employees` (
`id` int(0) NOT NULL,
`d_id` int(0) NOT NULL,
`e_id` int(0) NOT NULL,
`remark` varchar(255) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NULL DEFAULT NULL,
`num` int(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_d_e_id`(`d_id`, `e_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of departments_employees
-- ----------------------------
INSERT INTO `departments_employees` VALUES (1, 1, 1, NULL, NULL);
INSERT INTO `departments_employees` VALUES (2, 1, 2, NULL, NULL);
INSERT INTO `departments_employees` VALUES (3, 2, 1, NULL, NULL);
DROP TABLE IF EXISTS `employees`;
CREATE TABLE `employees` (
`id` int(0) NOT NULL,
`name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`salary` decimal(10, 2) NULL DEFAULT NULL,
`department_id` int(0) NULL DEFAULT NULL,
`nums` bigint(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `department_id`(`department_id`) USING BTREE,
INDEX `salary`(`salary`) USING BTREE,
INDEX `name_sal_did`(`name`, `salary`, `department_id`) USING BTREE,
INDEX `name_did`(`name`, `department_id`) USING BTREE,
CONSTRAINT `employees_ibfk_1` FOREIGN KEY (`department_id`) REFERENCES `departments` (`id`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of employees
-- ----------------------------
INSERT INTO `employees` VALUES (1, 'Alice', 70000.00, 1, NULL);
INSERT INTO `employees` VALUES (2, 'Bob', 80000.00, 1, NULL);
INSERT INTO `employees` VALUES (3, 'Charlie', 90000.00, 2, NULL);
INSERT INTO `employees` VALUES (4, 'Dave', 100000.00, 2, NULL);
INSERT INTO `employees` VALUES (5, 'Eve', 110000.00, 3, NULL);
INSERT INTO `employees` VALUES (6, 'Frank', 120000.00, 3, NULL);
Explain的各个列详解析
id:select查询的标识符,表示查询的顺序。
EXPLAIN SELECT * FROM EMPLOYEES E1 JOIN DEPARTMENTS E2 ON E1.DEPARTMENT_ID = E2.ID ;

select_type:用于标识查询中的SELECT语句的类型,
MySQL的查询优化器有一个特性叫做派生表合并(Derived Table Merge),这个特性在MySQL 5.7及以上版本默认是开启的。
开启这个特性后,MySQL查询优化器会尝试将派生表(即子查询生成的临时表)合并到主查询中,以便能够更高效地处理查询。
如果你想在EXPLAIN的输出中看到派生表,你可以通过设置会话变量optimizer_switch来关闭派生表合并特性,
SET SESSION optimizer_switch='derived_merge=off';
EXPLAIN SELECT NAME FROM EMPLOYEES WHERE SALARY > 80000;

EXPLAIN SELECT D.NAME FROM DEPARTMENTS D WHERE D.ID IN (SELECT DEPARTMENT_ID FROM EMPLOYEES WHERE SALARY > 80000);
按理来说,在这个查询中,外部的查询是PRIMARY。在这种情况下,MySQL 会执行一个称为 "子查询关联" 的优化。对于 IN 子查询,MySQL 会尝试重写它们为 INNER JOIN, 如果可以重写,MySQL 就会优化执行计划。所以才看到两个 SELECT 都被标记为 SIMPLE 的原因。MySQL 实际上将子查询转换成了一个简单的 JOIN 查询。 但是请注意,这并不是所有情况下都会发生。这取决于查询优化器如何判断可以获得最好的性能。 有时,为了禁止子查询优化,可以使用 STRAIGHT_JOIN 来强制 MySQL 按照你指定的 JOIN 顺序执行查询,在大多数情况下,MySQL的查询优化器可以找出最优的执行顺序。 所以,我们应该谨慎使用STRAIGHT_JOIN关键字,只有在确定默认的执行顺序不理想时,才应该考虑使用它。
EXPLAIN SELECT d.name FROM departments d WHERE d.id IN (SELECT department_id FROM employees WHERE salary > 80000);
在这个查询中,内部的查询就被标记为SUBQUERY。
EXPLAIN SELECT name FROM employees WHERE department_id = (SELECT id FROM departments WHERE name = 'Human Resources') UNION SELECT name FROM employees WHERE salary > 80000;

EXPLAIN SELECT * FROM (SELECT name FROM employees WHERE department_id = (SELECT id FROM departments WHERE name = 'Human Resources') UNION SELECT name FROM employees WHERE salary > 80000) AS unioned;

EXPLAIN SELECT * FROM (SELECT id FROM departments WHERE name = 'Human Resources') AS derived_table;
在这个查询中,子查询就会被标记为DERIVED。MySQL会首先执行这个子查询,然后将结果存储在一个临时表中,这个临时表就叫做"derived_table"。

table:输出结果集的表。
type:连接类型,常见的有:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL,类型从左至右,性能从高到低。




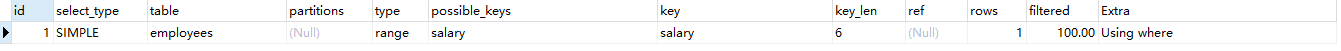


possible_keys:表示可能应用在这张表中的索引。如果为空,表示没有可能的索引。
key:实际使用的索引。如果为NULL,则没有使用索引。
key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好。
字符串类型(CHAR, VARCHAR):
数值类型:对于数值类型,
时间类型:
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数。
rows:根据表统计信息及索引选用情况,大致估算出找到所需的记录所需读取的行数。
filtered 列该列是一个百分比的值,rows * filtered/100 可以估算出将要和 explain 中前一个表进行连接的行数(前一个表指 explain 中的id值比当前表id值小的表)。
Extra:包含MySQL解决查询的详细信息,如:Using where(表示mysql服务器将在存储引擎检索行后再进行过滤),Using temporary(表示MySQL需要使用临时表来存储结果集),Using filesort(表示MySQL会对结果使用一个外部的索引排序,而不是按照表内的索引顺序来读取)等。






看到这里如果您觉得我的文章学的不错,请关注我的公众号,微信搜索 “二二零二”,更多内容正在创作者
MySQL_Explain详解的更多相关文章
- Linq之旅:Linq入门详解(Linq to Objects)
示例代码下载:Linq之旅:Linq入门详解(Linq to Objects) 本博文详细介绍 .NET 3.5 中引入的重要功能:Language Integrated Query(LINQ,语言集 ...
- 架构设计:远程调用服务架构设计及zookeeper技术详解(下篇)
一.下篇开头的废话 终于开写下篇了,这也是我写远程调用框架的第三篇文章,前两篇都被博客园作为[编辑推荐]的文章,很兴奋哦,嘿嘿~~~~,本人是个很臭美的人,一定得要截图为证: 今天是2014年的第一天 ...
- EntityFramework Core 1.1 Add、Attach、Update、Remove方法如何高效使用详解
前言 我比较喜欢安静,大概和我喜欢研究和琢磨技术原因相关吧,刚好到了元旦节,这几天可以好好学习下EF Core,同时在项目当中用到EF Core,借此机会给予比较深入的理解,这里我们只讲解和EF 6. ...
- Java 字符串格式化详解
Java 字符串格式化详解 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 文中如有纰漏,欢迎大家留言指出. 在 Java 的 String 类中,可以使用 format() 方法 ...
- Android Notification 详解(一)——基本操作
Android Notification 详解(一)--基本操作 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/Notification 文中如有纰 ...
- Android Notification 详解——基本操作
Android Notification 详解 版权声明:本文为博主原创文章,未经博主允许不得转载. 前几天项目中有用到 Android 通知相关的内容,索性把 Android Notificatio ...
- Git初探--笔记整理和Git命令详解
几个重要的概念 首先先明确几个概念: WorkPlace : 工作区 Index: 暂存区 Repository: 本地仓库/版本库 Remote: 远程仓库 当在Remote(如Github)上面c ...
- Drawable实战解析:Android XML shape 标签使用详解(apk瘦身,减少内存好帮手)
Android XML shape 标签使用详解 一个android开发者肯定懂得使用 xml 定义一个 Drawable,比如定义一个 rect 或者 circle 作为一个 View 的背景. ...
- Node.js npm 详解
一.npm简介 安装npm请阅读我之前的文章Hello Node中npm安装那一部分,不过只介绍了linux平台,如果是其它平台,有前辈写了更加详细的介绍. npm的全称:Node Package M ...
- .NET应用和AEAI CAS集成详解
1 概述 数通畅联某综合SOA集成项目的统一身份认证工作,需要第三方系统配合进行单点登录的配置改造,在项目中有需要进行单点登录配置的.NET应用系统,本文专门记录.NET应用和AEAI CAS的集成过 ...
随机推荐
- shell执行一个程序过程
1:shell调用执行程序或脚本 2:unix内核启动一个新的进程,在该进程中执行所指定的程序. 3:如果是编译型程序,内核成执行,如果无法执行指定的程序,返回"not executable ...
- 2023-05-06:X轴上有一些机器人和工厂。给你一个整数数组robot,其中robot[i]是第i个机器人的位置 再给你一个二维整数数组factory,其中 factory[j] = [posit
2023-05-06:X轴上有一些机器人和工厂.给你一个整数数组robot,其中robot[i]是第i个机器人的位置 再给你一个二维整数数组factory,其中 factory[j] = [posit ...
- 我自己写了一个波场(Tron)本地网页版钱包
最近由于项目需要,需要给每个用户分配一个充币地址,考虑到钱包安全性和方便管理,于是自己动手写了一个本地网页版的钱包,附上源代码跟大家交流下. Github 源代码地址 钱包和项目是分离的,项目通过鉴权 ...
- Web进阶LNMP网站部署
Web进阶LNMP网站部署 目录 Web进阶LNMP网站部署 LNMP架构工作流程 部署LNMP架构 1.安装nginx 2.安装php 3.安装数据库 将Nginx和PHP建立连接 1.修改ngin ...
- Prompt learning 教学[进阶篇]:简介Prompt框架并给出自然语言处理技术:Few-Shot Prompting、Self-Consistency等;项目实战搭建知识库内容机器人
Prompt learning 教学[进阶篇]:简介Prompt框架并给出自然语言处理技术:Few-Shot Prompting.Self-Consistency等:项目实战搭建知识库内容机器人 1. ...
- 2022-12-09:上升的温度。以下的数据输出2和4,2015-01-02 的温度比前一天高(10 -> 25),2015-01-04 的温度比前一天高(20 -> 30),sql语句如何写? DR
2022-12-09:上升的温度.以下的数据输出2和4,2015-01-02 的温度比前一天高(10 -> 25),2015-01-04 的温度比前一天高(20 -> 30),sql语句如 ...
- 2022-01-02:给定两个数组A和B,长度都是N, A[i]不可以在A中和其他数交换,只可以选择和B[i]交换(0<=i<n), 你的目的是让A有序,返回你能不能做到。
2022-01-02:给定两个数组A和B,长度都是N, A[i]不可以在A中和其他数交换,只可以选择和B[i]交换(0<=i<n), 你的目的是让A有序,返回你能不能做到. 答案2022- ...
- 03、SECS-I 协议介绍
03.SECS-I 协议介绍 上一篇我们学习了 SECS-II 协议,对 SECS-II 协议有了初略的了解,现在我们再来一起学习 SECS-I 协议. 文章的内容基本上来自参考资料和自己看的文档,若 ...
- IntelliJ IDEA 的初次使用--/护头
IntelliJ IDEA 的使用 使用前先完成以下两点 环境配置 Win10环境配置(二) --Java篇 软件安装 IntelliJ IDEA 的安装 在完成软件安装,打开软件的瞬间,我是懵逼的. ...
- 识别一切模型RAM(Recognize Anything Model)及其前身 Tag2Text 论文解读
总览 大家好,我是卷了又没卷,薛定谔的卷的AI算法工程师「陈城南」~ 担任某大厂的算法工程师,带来最新的前沿AI知识和工具,欢迎大家交流~ 继MetaAI 的 SAM后,OPPO 研究院发布识别一切模 ...