Elasticsearch之重要核心概念(cluster(集群)、shards(分配)、replicas(索引副本)、recovery(据恢复或叫数据重新分布)、gateway(es索引的持久化存储方式)、discovery.zen(es的自动发现节点机制机制)、Transport(内部节点或集群与客户端的交互方式)、settings(修改索引库默认配置)和mappings)
Elasticsearch之重要核心概念如下:
1、cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
主节点的职责是负责管理集群状态,包括管理分片的状态和副本的状态,以及节点的发现和删除。
注意:主节点不负责对数据的增删改查请求进行处理,只负责维护集群的相关状态信息。
集群配置(修改conf/elasticsearch.yml文件)
discovery.zen.ping.unicast.hosts: ["host1", "host2:9300"]
集群状态查看
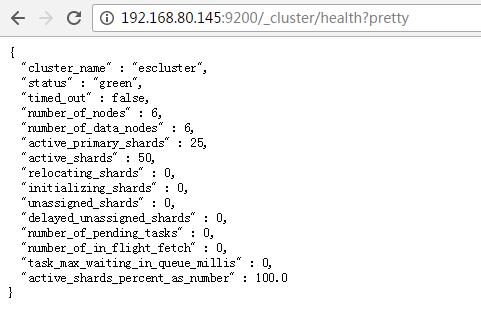
http://your ip:9200/_cluster/health?pretty
比如,我这里是
http://192.168.80.145:9200/_cluster/health?pretty
想学习,请移步
Elasticsearch-2.4.3的单节点安装(多种方式图文详解)
Elasticsearch-2.4.3的3节点安装(多种方式图文详解)
2、shards
代表索引分片,es可以把一个完整的索引分成多个分片,Elasticsearch Client发送搜索请求,某个索引库,一般默认是5个分片(shard)。这样的好处是可以把一个大的索引水平拆分成多个,分布到不同的节点上。构成分布式搜索,提高性能和吞吐量。
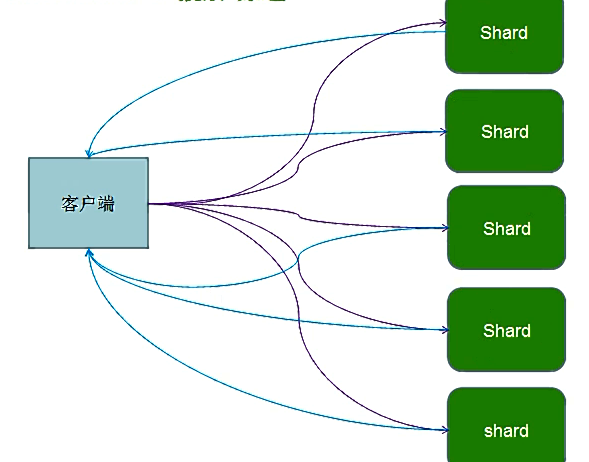
比如,http://master:9200/zhouls/user/1。则将索引zhouls,分成多个分片。
分片的数量只能在创建索引库时指定,索引库创建后不能更改。
只能在创建索引库的时候指定
curl -XPUT 'localhost:9200/zhouls/' -d'{"settings":{"number_of_shards":3}}'
默认是一个索引库有5个分片
index.number_of_shards: 5
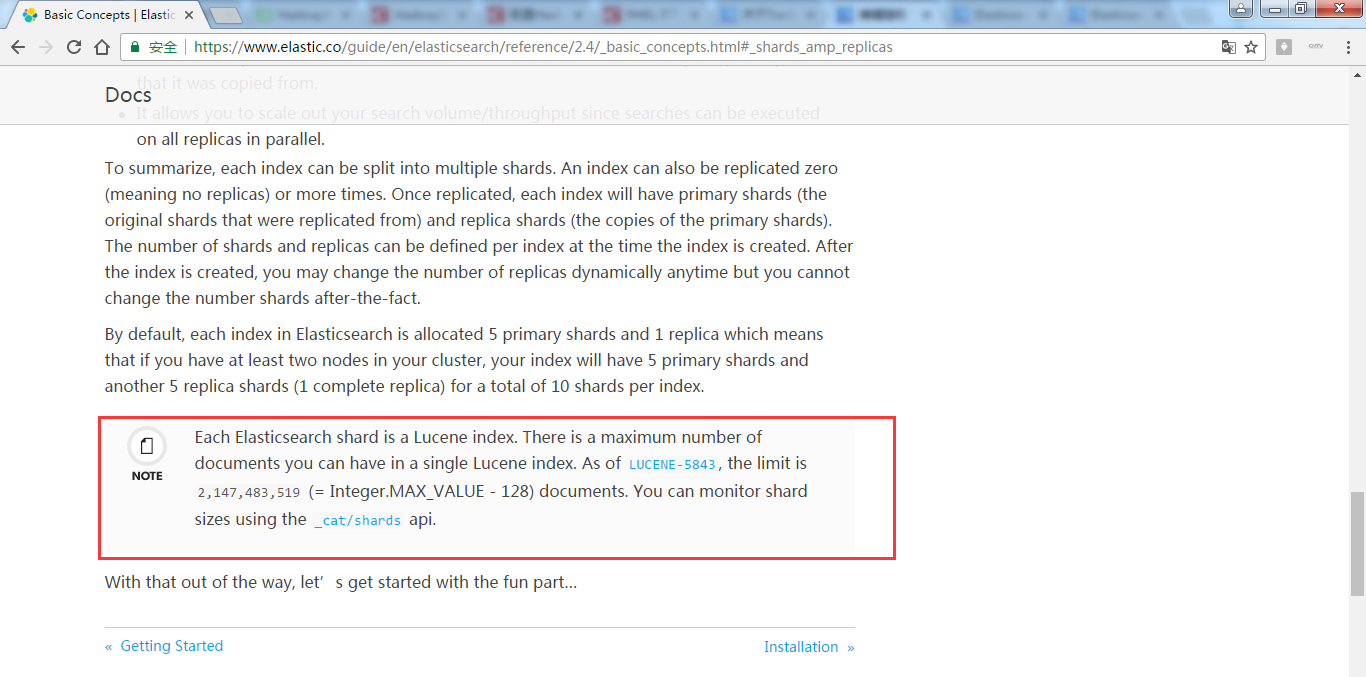
每个分片中最多存储2,147,483,519条数据
Integer.MAX_VALUE-128【详细解释见备注】
为了,更好的观看es核心概念之shards索引片的效果,我在3台机器组建的es集群里演示,并且,关闭192.168.80.11和192.168.80.12,只留下192.168.80.10这台来测试。
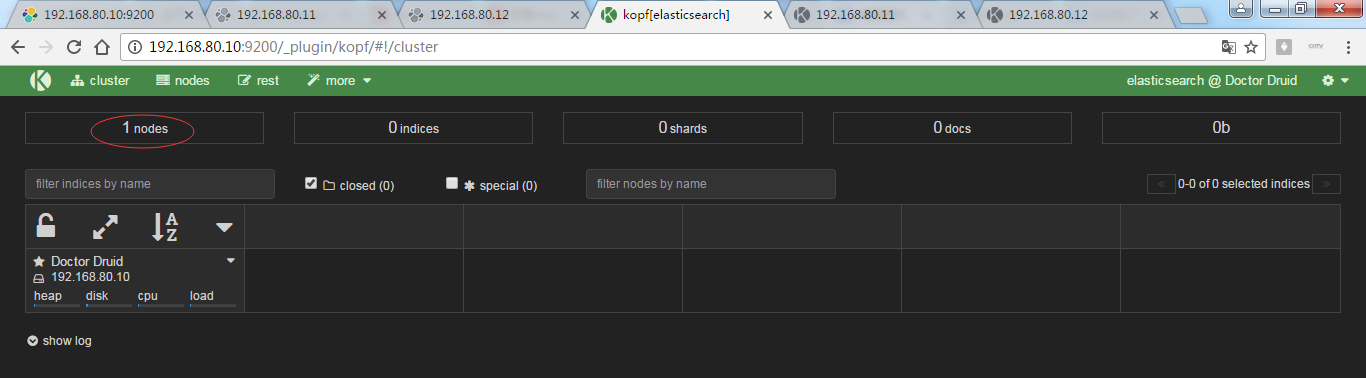

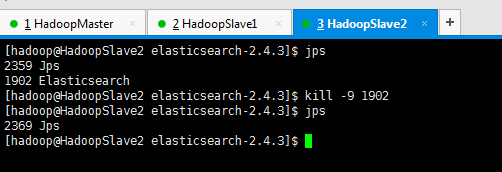
然后,执行
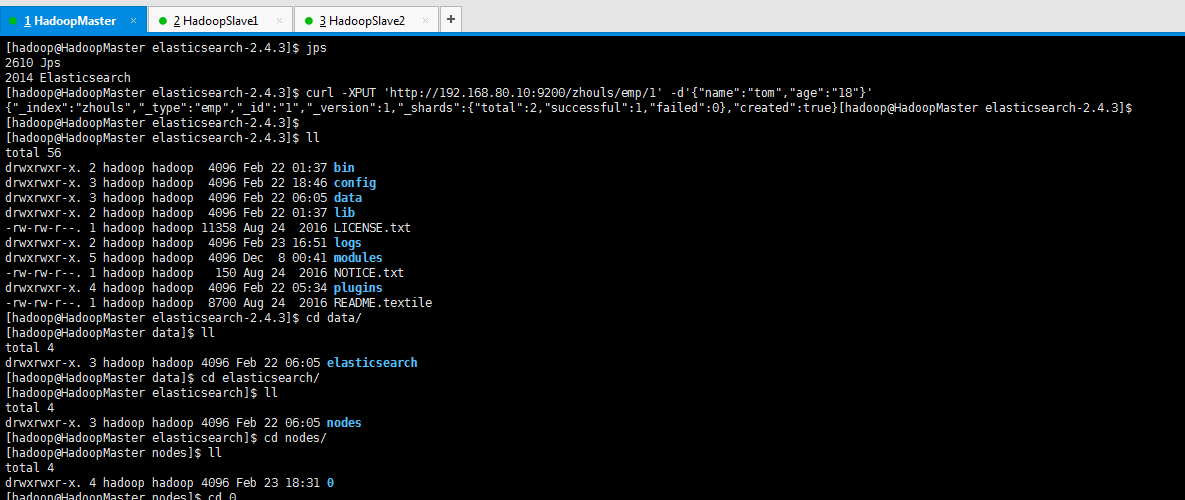
[hadoop@HadoopMaster elasticsearch-2.4.3]$ jps
2610 Jps
2014 Elasticsearch
[hadoop@HadoopMaster elasticsearch-2.4.3]$ curl -XPUT 'http://192.168.80.10:9200/zhouls/emp/1' -d'{"name":"tom","age":"18"}'
{"_index":"zhouls","_type":"emp","_id":"1","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"created":true}[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$
[hadoop@HadoopMaster elasticsearch-2.4.3]$ ll
total 56
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 22 01:37 bin
drwxrwxr-x. 3 hadoop hadoop 4096 Feb 22 18:46 config
drwxrwxr-x. 3 hadoop hadoop 4096 Feb 22 06:05 data
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 22 01:37 lib
-rw-rw-r--. 1 hadoop hadoop 11358 Aug 24 2016 LICENSE.txt
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 23 16:51 logs
drwxrwxr-x. 5 hadoop hadoop 4096 Dec 8 00:41 modules
-rw-rw-r--. 1 hadoop hadoop 150 Aug 24 2016 NOTICE.txt
drwxrwxr-x. 4 hadoop hadoop 4096 Feb 22 05:34 plugins
-rw-rw-r--. 1 hadoop hadoop 8700 Aug 24 2016 README.textile
[hadoop@HadoopMaster elasticsearch-2.4.3]$ cd data/
[hadoop@HadoopMaster data]$ ll
total 4
drwxrwxr-x. 3 hadoop hadoop 4096 Feb 22 06:05 elasticsearch
[hadoop@HadoopMaster data]$ cd elasticsearch/
[hadoop@HadoopMaster elasticsearch]$ ll
total 4
drwxrwxr-x. 3 hadoop hadoop 4096 Feb 22 06:05 nodes
[hadoop@HadoopMaster elasticsearch]$ cd nodes/
[hadoop@HadoopMaster nodes]$ ll
total 4
drwxrwxr-x. 4 hadoop hadoop 4096 Feb 23 18:31 0
[hadoop@HadoopMaster nodes]$ cd 0
[hadoop@HadoopMaster 0]$ ll
total 8
drwxrwxr-x. 3 hadoop hadoop 4096 Feb 23 18:31 indices
-rw-rw-r--. 1 hadoop hadoop 0 Feb 22 06:05 node.lock
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 23 16:49 _state
[hadoop@HadoopMaster 0]$ cd indices/
[hadoop@HadoopMaster indices]$ ll
total 4
drwxrwxr-x. 8 hadoop hadoop 4096 Feb 23 18:31 zhouls
[hadoop@HadoopMaster indices]$ cd zhouls/
[hadoop@HadoopMaster zhouls]$ ll
total 24
drwxrwxr-x. 5 hadoop hadoop 4096 Feb 23 18:31
drwxrwxr-x. 5 hadoop hadoop 4096 Feb 23 18:31
drwxrwxr-x. 5 hadoop hadoop 4096 Feb 23 18:31
drwxrwxr-x. 5 hadoop hadoop 4096 Feb 23 18:31
drwxrwxr-x. 5 hadoop hadoop 4096 Feb 23 18:31
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 23 18:31 _state
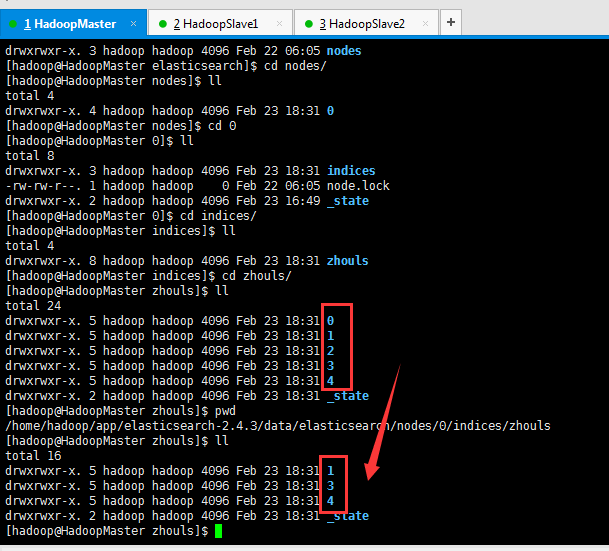
[hadoop@HadoopMaster zhouls]$ pwd
/home/hadoop/app/elasticsearch-2.4.3/data/elasticsearch/nodes/0/indices/zhouls
[hadoop@HadoopMaster zhouls]$
蓝色,这个目录下,有0、1、2、3和4目录,这几个就是es的核心概念之shards索引片。
现在,我将在192.168.80.10起来的基础上,去对192.168.80.11和192.168.80.12启动,来注意看shards索引片,是如何变化的?
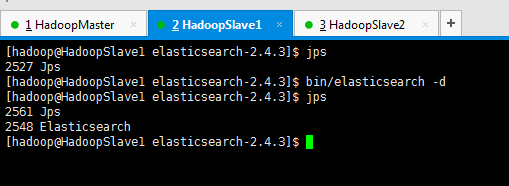
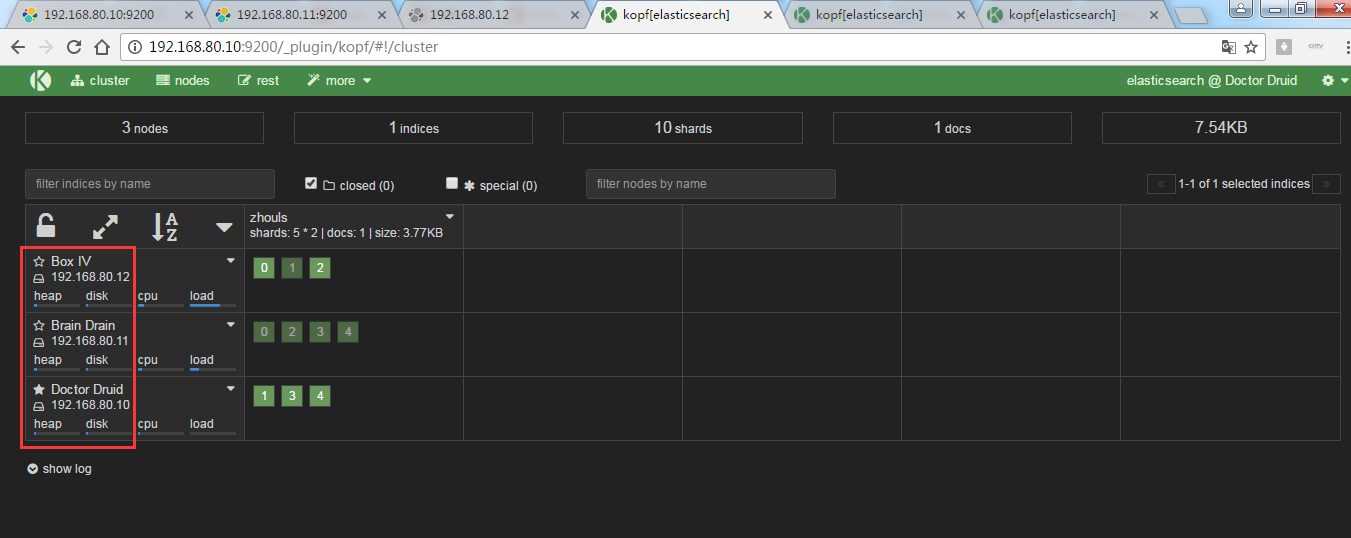
这就是变化!
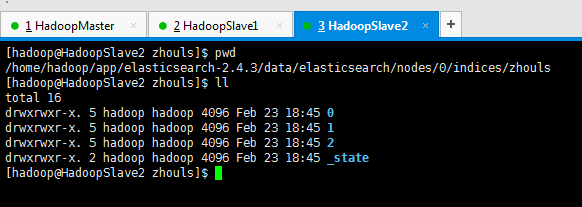
即,192.168.80.10是1,3,4
192.168.80.11是0,2,3,4
192.168.80.12是0,1,2
es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引水平拆分成多个,分布到不同的节点上。构成分布式搜索,提高性能和吞吐量。
问:es的分片数,可以配置吗?
答:可以修改,在创建索引库的时候,修改分片数,默认是5。当创建完索引库之后,不能再修改分片数了。只能在创建索引库的时候进行修改!!!
比如, curl -XPUT 'http://192.168.80.10:9200/zhouls/' -d'{"settings":{"number_of_shards":3}}'
新建索引库zhouls时,对索引库的默认5个修改为3个。
更多,详细,见es的官网
3、replicas
代表索引副本,es可以给索引分片设置副本。
副本的作用:
一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。
二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
【副本的数量可以随时修改】
可以在创建索引库的时候指定
curl -XPUT 'localhost:9200/zhouls/' -d'{"settings":{"number_of_replicas":2}}'
或 curl -XPUT 'master:9200/zhouls/' -d'{"settings":{"number_of_replicas":2}}'
默认是一个分片有1个副本。 数据量大了的话,分片多了也不太好。
index.number_of_replicas: 1
注意:主分片和副本不会存在一个节点中。
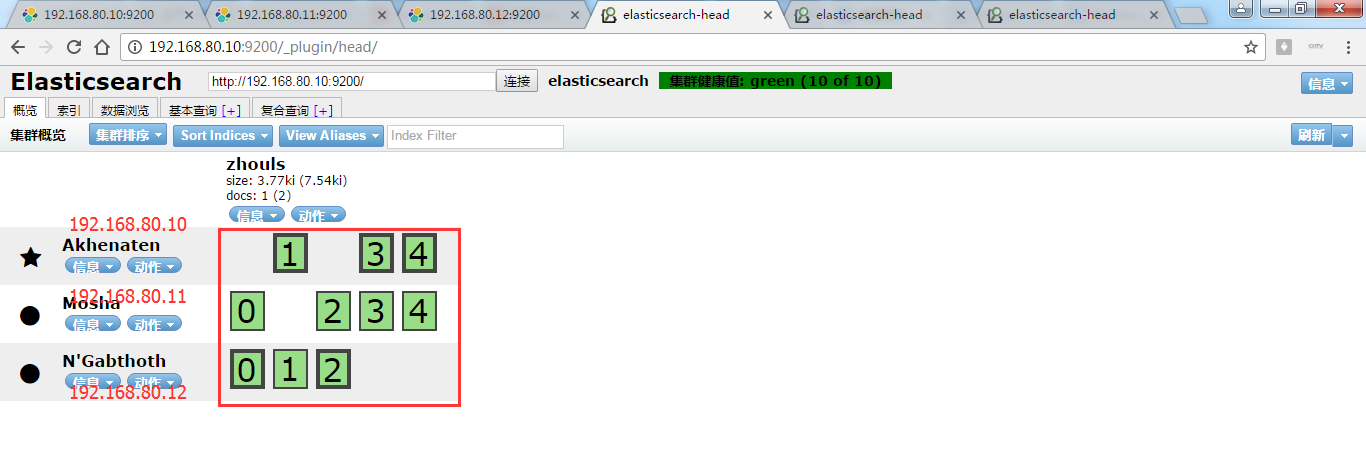
同样,做测试,为了,更好的观看es核心概念之replicas副本的效果,我在3台机器组建的es集群里演示,并且,关闭192.168.80.11和192.168.80.12,只留下192.168.80.10这台来测试。
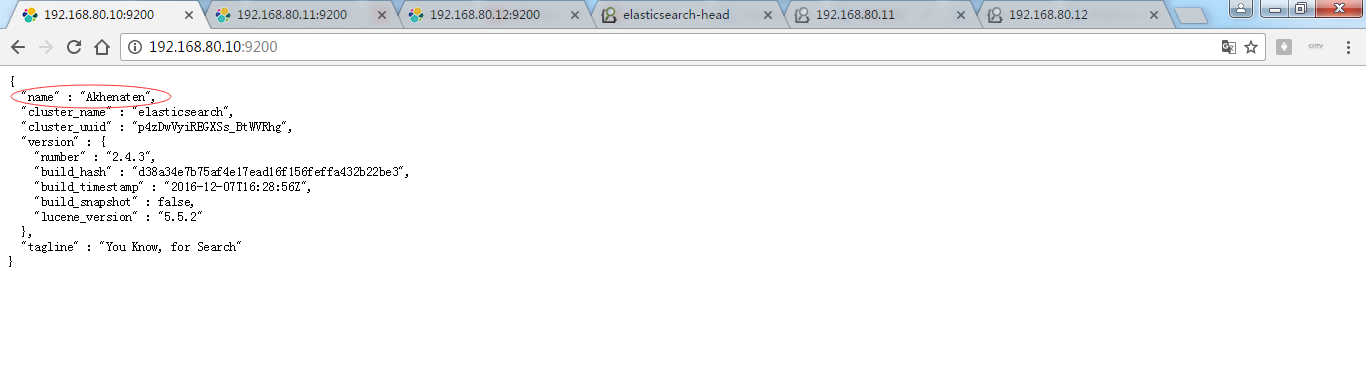
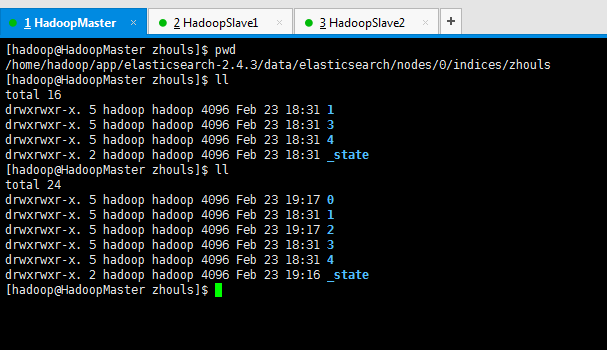

可以看到,只开启192.168.80.10这台机器的话,则默认的5个分片都到192.168.80.10这台了。
注意:默认是一个分片有1个副本!
为什么,是黄色? 按理说,现在这个集群里,是要有10个分片的,但是呢,现在,你只有5个分片。所以,是黄色警告。显示集群监控值:yellows ( 5 of 10)
单节点的话,这几个分片,压根就不会有副本。
那好,现在,再依次把192。168.80.11和192.168.80.12启动起来。

再刷新!
那么,怎么认识,哪个框是主分片,哪个框是副本呢?
答:颜色深的是主分片。
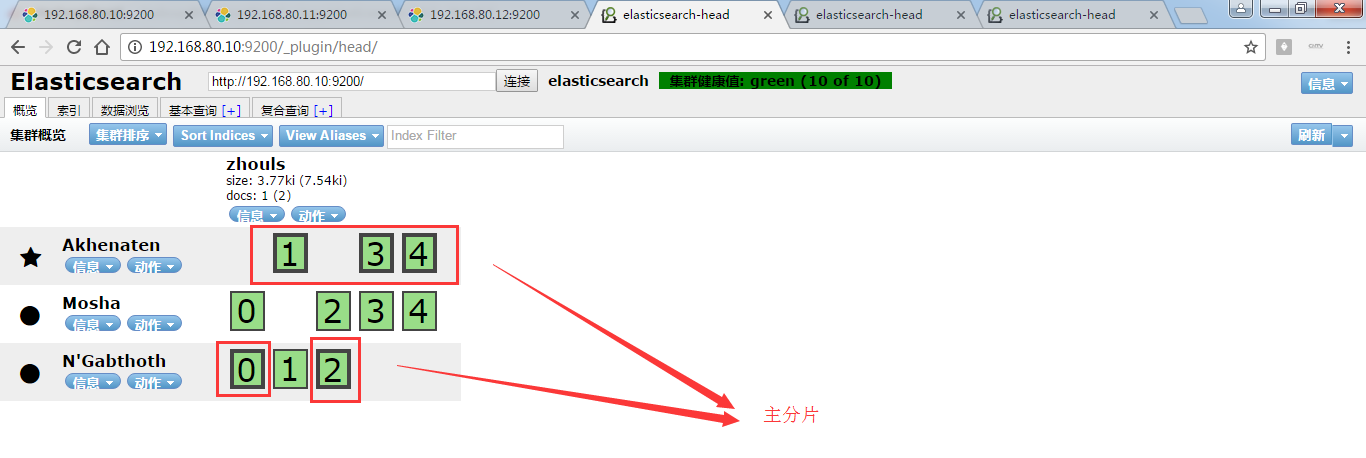
同理,192.168.80.11和192.168.80.12的情况也是一样:,如下
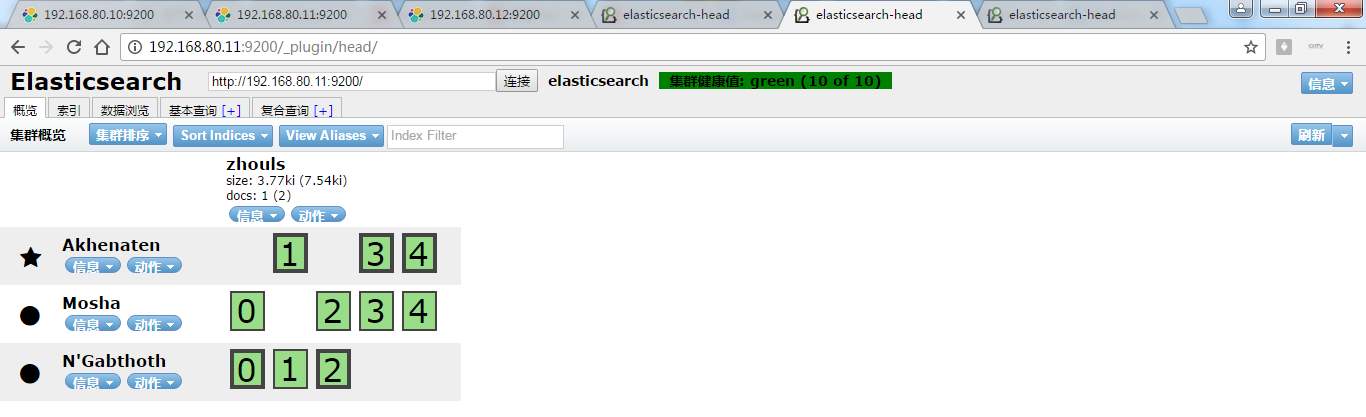
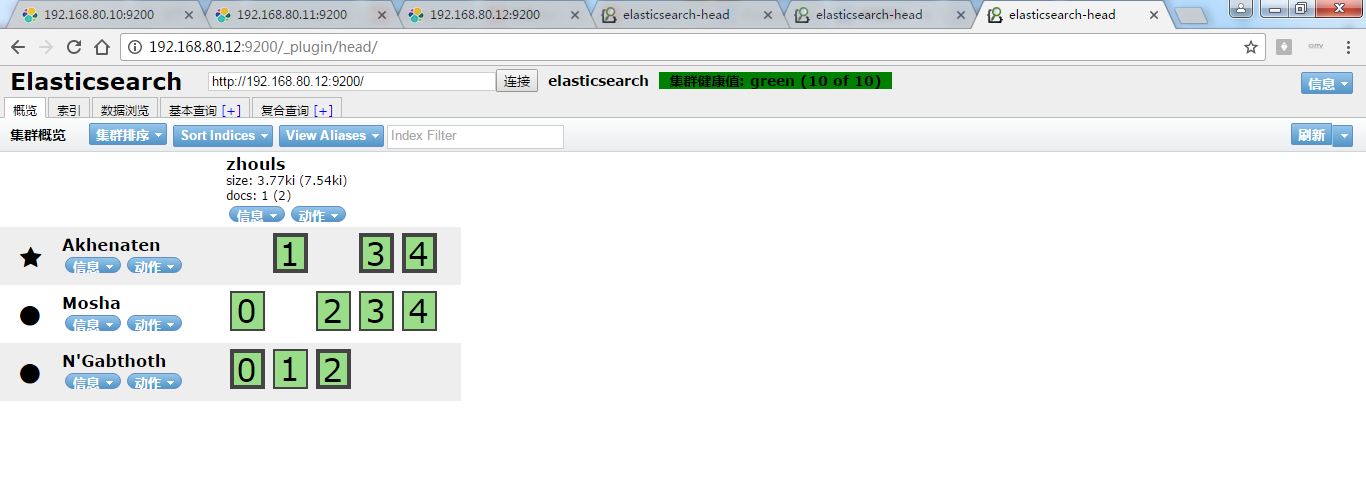
可以看出,注意:主分片和副本不会存在一个节点中!
分片,在磁盘里,本质就是一个目录。
4、recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
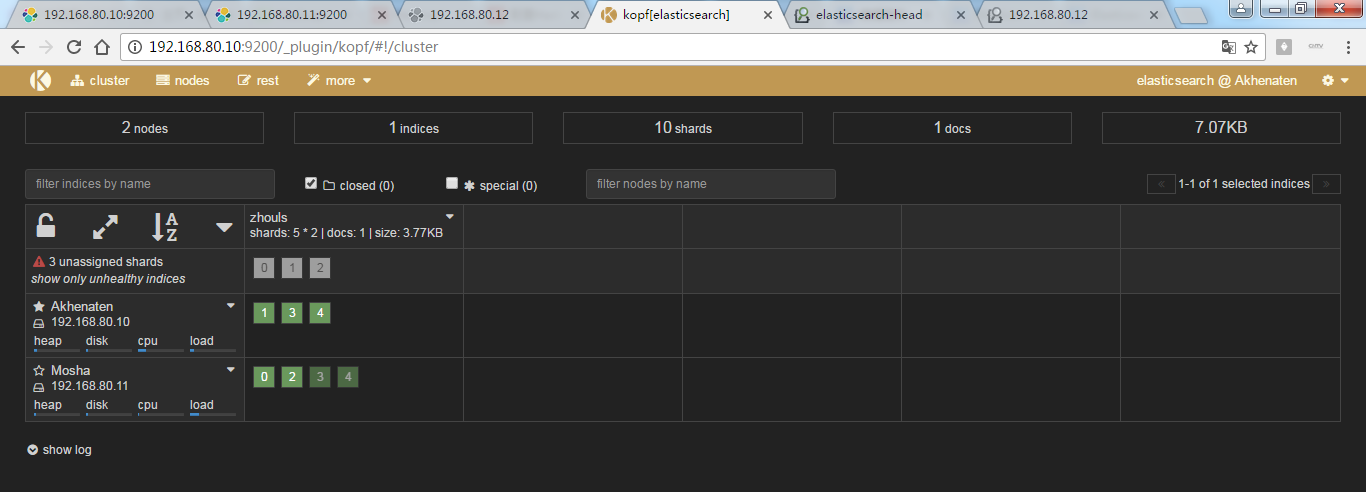
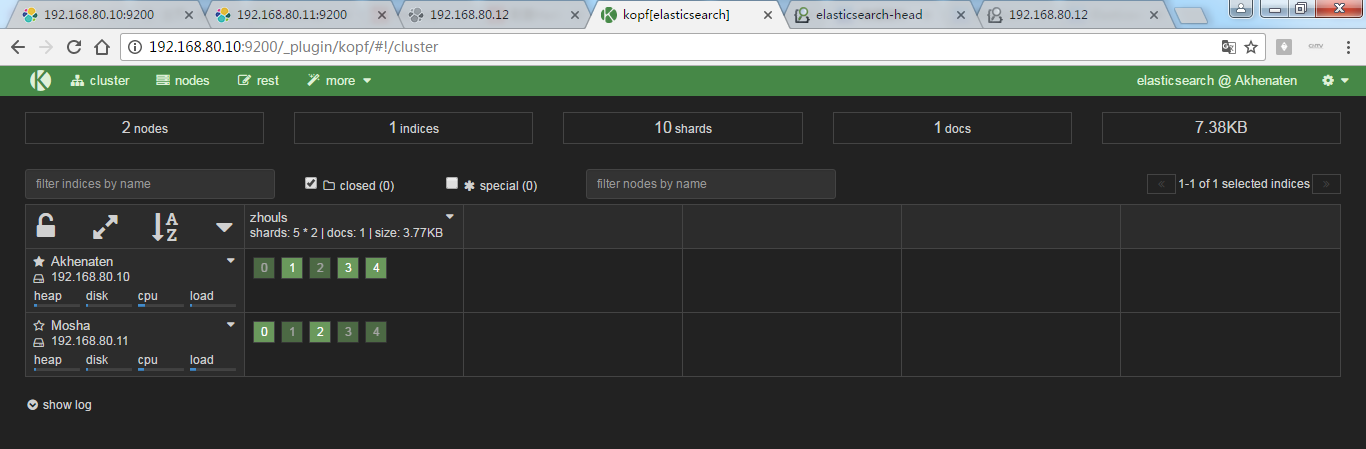
为了,更好的观看es核心概念之recovery数据重新分布的效果,我在3台机器组建的es集群里演示,并且,先开启192.168.80.10和192.168.80.11,然后,让192.168.80.12来启动!添加进来
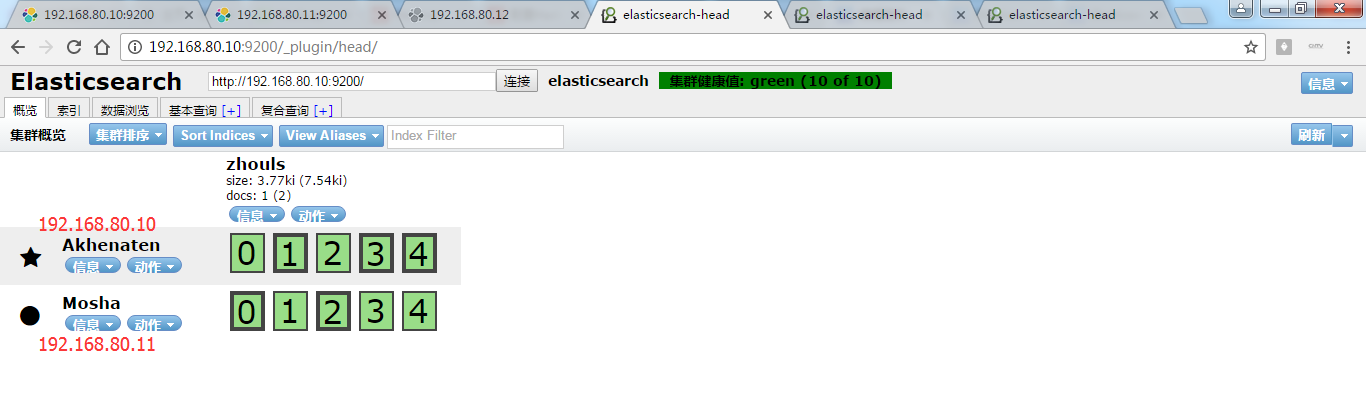
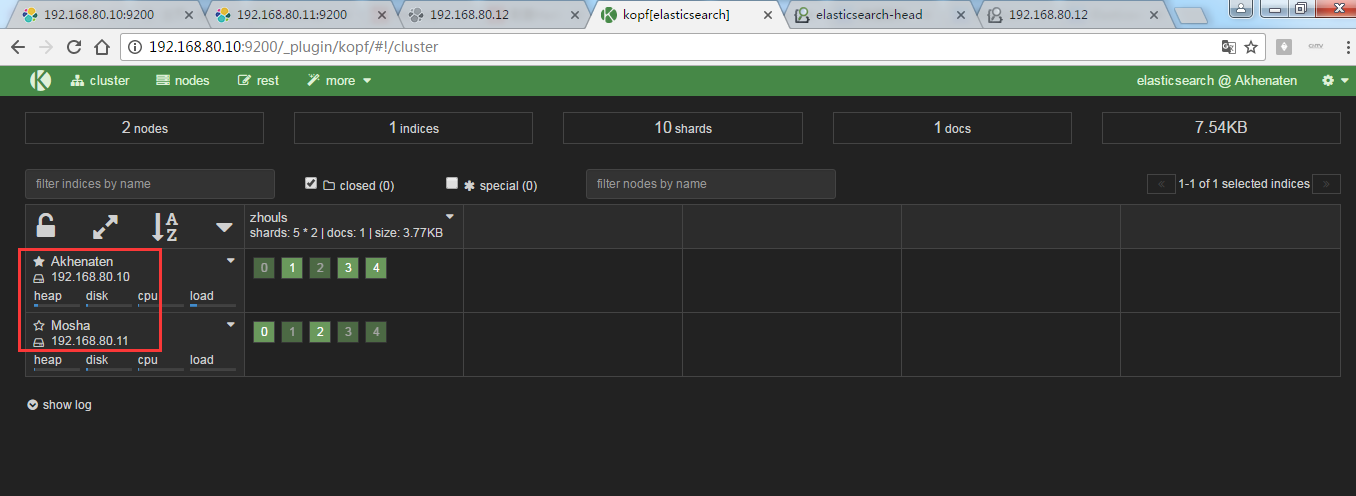
现在,进行启动192.168.80.12
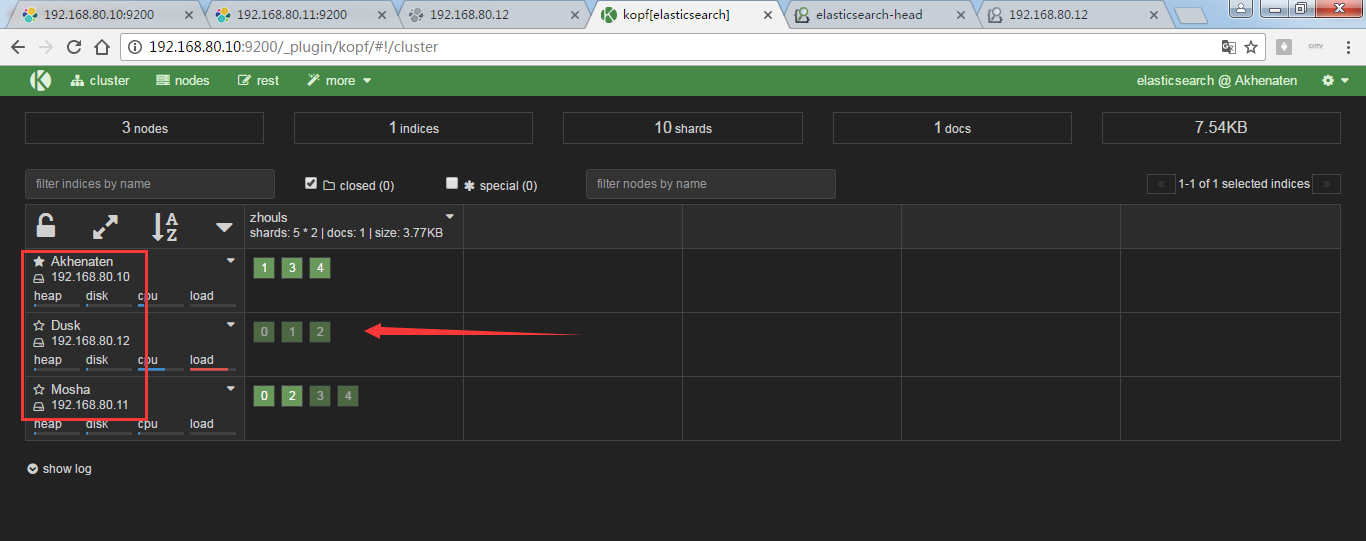
同样,也是,框线深的是主分片,浅的是副本。
再把,192.168.80.12kill掉
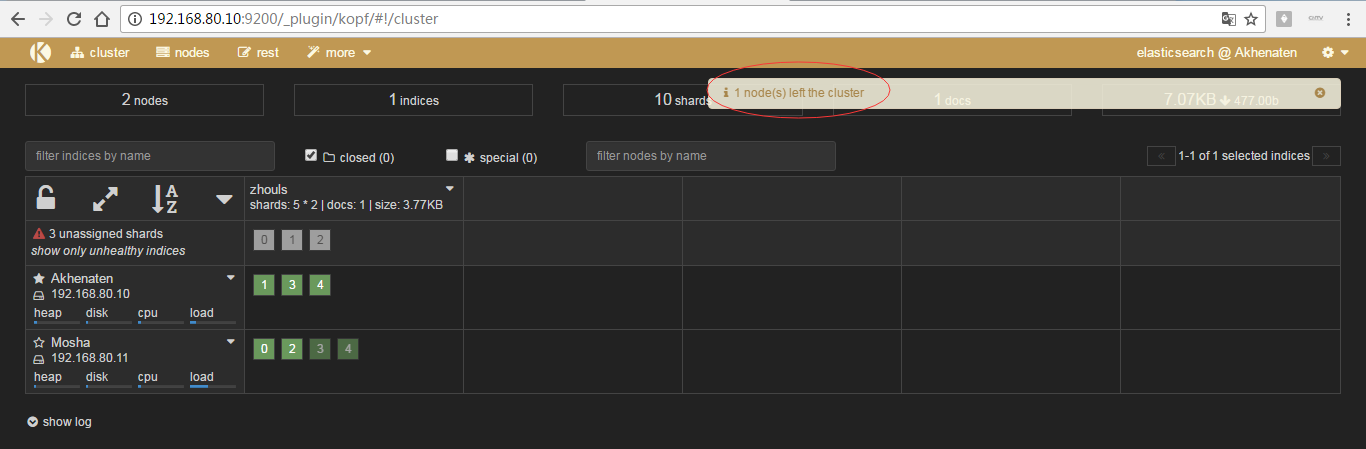
注意:如果索引很多,则数据恢复的工作非常慢!
问:恢复期间,访问数据会出现问题吗?
答:不会,因为,会有副本。只是说,访问有延迟!
问:具体多少个副本,或具体多少个分片,该怎么处理呢?在实际生产中。
答:具体牵扯到ES的优化!后续,请见我的博客, https://i.cnblogs.com/posts?categoryid=950999 。
5、 Gateway
代表es索引的持久化存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。当这个es集群关闭再重新启动时就会从gateway中读取索引数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和Amazon的s3云存储服务。
比如,我下面写的这篇博客。
Elasticsearch之Hadoop插件的安装(图文详解)
6、discovery.zen(es的自动发现节点机制机制)
代表es的自动发现节点机制,es的一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
并没有如spark、hadoop一样,使用zookeeper。
点对点,即数据的传输并不需要通过服务器,直接通过网络中节点就可以了。
如果是同网段,则默认是使用多播机制。
如果是不同网段的节点如何组成es集群呢?如下
禁用自动发现机制
discovery.zen.ping.multicast.enabled: false
设置新节点被启动时能够发现的主节点列表
discovery.zen.ping.unicast.hosts: ["192.168.20.210" , "192.168.20.211" . "192.168.20.212" ]
更详细,见官网
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery.html
7、Transport(内部节点或集群与客户端的交互方式)
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
更详细,见官网
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-transport.html

8、settings(修改索引库默认配置)
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-create-index.html
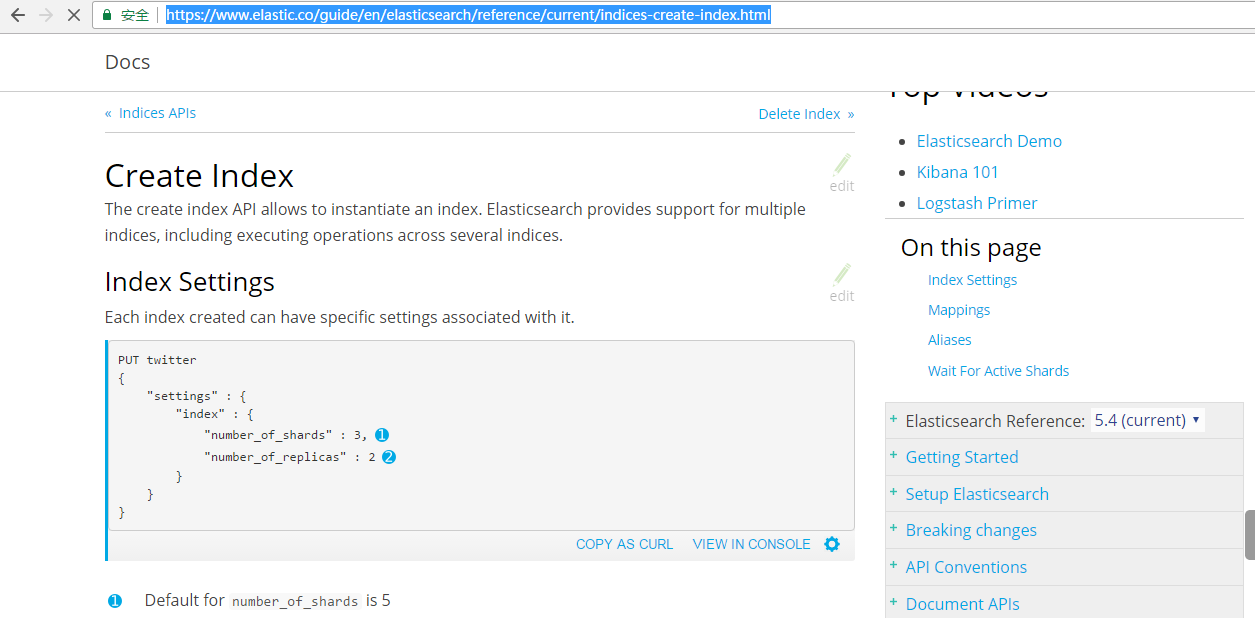
Elasticsearch之settings和mappings
推荐
Elasticsearch之重要核心概念(cluster(集群)、shards(分配)、replicas(索引副本)、recovery(据恢复或叫数据重新分布)、gateway(es索引的持久化存储方式)、discovery.zen(es的自动发现节点机制机制)、Transport(内部节点或集群与客户端的交互方式)、settings(修改索引库默认配置)和mappings)的更多相关文章
- ElasticStack系列之二十 & 数据均衡、迁移、冷热分离以及节点自动发现原理与机制
1. 数据均衡 某个shard分配到哪个节点上,一般来说,是由 ELasticSearch 自行决定的.以下几种情况会触发分配动作: 新索引的建立 索引的删除 新增副本分片 节点增减引发的数据均衡 在 ...
- ElasticSearch入门及核心概念介绍
Elasticsearch研究有一段时间了,现特将Elasticsearch相关核心知识和原理以初学者的角度记录下来,如有不当,烦请指正! 0. 带着问题上路——ES是如何产生的? (1)思考:大 ...
- ElasticSearch安装和核心概念
1.ElasticSearch安装 elasticsearch的安装超级easy,解压即用(要事先安装好java环境). 到官网 http://www.elasticsearch.org下载最新版的 ...
- JPA,EclipseLink 缓存机制学习(一) 树节点搜索问题引发的思考
最近在项目在使用JPA+EclipseLink 的方式进行开发,其中EclipseLink使用版本为2.5.1.遇到一些缓存方面使用不当造成的问题,从本篇开始逐步学习EclipseLink的缓存机制. ...
- ElasticSearch 全文检索— ElasticSearch 核心概念
ElasticSearch核心概念-Cluster 1)代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的.es的一个概念就是去中心化,字 ...
- Elasticsearch核心概念
Elasticsearch 核心概念 Cluster 代表一个集群, 集群中有多个节点, 其中一个为主节点, 该节点可以通过选举产生.(主从节点只针对于集群内部) 去中心化: 对于集群外来说无中心节点 ...
- ElasticSearch 核心概念
ElasticSearch核心概念-Cluster ElasticSearch核心概念-shards ElasticSearch核心概念-replicas ElasticSearch核心概念-reco ...
- ELK & ElasticSearch 5.1 基础概念及配置文件详解【转】
转自:https://blog.csdn.net/zxf_668899/article/details/54582849 配置文件 基本概念 接近实时NRT 集群cluster 索引index 文档d ...
- 理解maven的核心概念
原文出处:http://www.cnblogs.com/holbrook/archive/2012/12/24/2830519.html 好久没进行java方面的开发了,最近又完成了一个java相关的 ...
随机推荐
- jQuery插件开发的两种方法
1 类级别 类级别你可以理解为拓展jquery类,最明显的例子是$.ajax(...),相当于静态方法. 开发扩展其方法时使用$.extend方法,即jQuery.extend(object); $. ...
- AVL数
平衡二叉树(AVL树) AVL树是一种二叉搜索树,并且每个节点的左右子树高度之差最多为1.AVL树是第一个在最坏的情况下保证以O(logn)的时间进行搜索,插入和删除操作的数据结构,AVL树能在对数时 ...
- Sumblime Text3中使用vue-cli创建vue项目,代码不高亮,解决
问题如下:在Sumblime Text3中打开vue-cli常见的项目,代码一片灰色 解决如下: 第一步:下载文件Vue components 链接 GitHub - vuejs/vue-synta ...
- jQuery在多个div中,删除指定项
之前工作中有一个需求,就是在一堆图片列表中,点击具体的图片,并从界面移除:点击具体的图片,下载:这是一个思路 <style type="text/css" media=&qu ...
- 数据库SQL语句错误
Caused by: android.database.sqlite.SQLiteException: near "where": syntax error(Sqlite co ...
- shell编程-1.字符截取命令-列截取awk+printf
- Unity类继承关系 图
UnityEngine(命名空间) 其他命名空间 其他类 Object(类) 其他类(继承自Object) Component(类)(继承自Object) 其他类(继承自Component) Tran ...
- node——post提交新闻内容
获取用户post提交的数据分多次提交,因为post提交数据的时候,数据量可能比较大,会要影响服务器中获取用户所以.提交的所有数据,就必须监听request事件.那么,什么时候才表示浏览器把所有数据提交 ...
- Day01-04学习内容总结
学习内容小结 1.什么是编程,编程有什么用,什么是编程语言 2.计算的组成原理及组成部分 3.机械硬盘的工作原理 4.什么是操作系统,操作系统做了什么,为什么要有操作系统,操作系统有什么用 5.应用程 ...
- sklearn学习8-----GridSearchCV(自动调参)
一.GridSearchCV介绍: 自动调参,适合小数据集.相当于写一堆循环,自己设定参数列表,一个一个试,找到最合适的参数.数据量大可以使用快速调优的方法-----坐标下降[贪心,拿当前对模型影响最 ...