Python爬虫—requests库get和post方法使用
Python爬虫—requests库get和post方法使用
requests库是一个常用于http请求的模块,性质是和urllib,urllib2是一样的,作用就是向指定目标网站的后台服务器发起请求,并接收服务器返回的响应内容。
1. 安装requests库
- 使用pip install requests安装
如果再使用pip安装python模块出现timeout超时异常,可使用国内豆瓣源进行安装。
pip install requests -i https://pypi.douban.com/simple
- 手动下载安装包安装
同样的,某些库安装出现异常便可采取这种逛淘宝的操作方式。不过,当你在选择的时候一定要注意实际项目所需求的python库的版本,以免后期出现问题。
网站:https://pypi.org
2.requests.get()方法使用
所谓的get方法,便是利用程序使用HTTP协议中的GET请求方式对目标网站发起请求,同样的还有POST,PUT等请求方式,其中GET是我们最常用的,通过这个方法我们可以了解到一个请求发起到接收响应的过程。(HTTP常见请求方式:http://www.noob.com/http/http-methods.html)
实现方式:
import requests
start_url = 'https://www.baidu.com'
response = requests.get(url=start_url)
print(response) # 返回值:<Response [200]>
这是一个最简单实现请求的方式,最后返回一个响应对象,响应对象中携带的数值便是HTTP状态码,你可以根据这些状态码的值来判定请求的成功以及推测失败的原因。(HTTP状态码:http://www.noob.com/http/http-status-codes.html)
这并不是一个完整的请求,因为服务器在接收到你的程序的请求信息时,它可以明确的从Request headers中看到你是在用程序发起请求接收响应,为了完善我们的请求,可以自定义请求头信息,利用get()方法的headers参数。
我们可以从浏览器的F12开发者工具中Network下找到请求网址的headers信息,保存下来作为我们自定义参数。如:
import requests
# 目标url
start_url = 'https://www.baidu.com'
# 自定义headers
headers = {"Host": "www.baidu.com",
"Referer": "https://www.baidu.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
}
response = requests.get(url=start_url, headers=headers)
print(response) # 返回值:<Response [200]>
不同的网站对于请求头中的字段信息有着不同的要求,某些关键字段需要在html源码中去寻找,然后自己组织定义到headers中完成请求。
对于一些特定的网站会对某一时间段内你所在ip的请求次数坐监测,从而判断此请求是否为非人类发出的,get()方法同样为我们提供了在请求时更换ip的操作方式,只需要像自定义headers一样定义我们的可用ip即可,如下:
import requests
start_url = 'https://www.baidu.com'
headers = {"Host": "www.baidu.com",
"Referer": "https://www.baidu.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
}
# 自定义代理ip,此处的ip需要自行更换,只需要将ip和port按格式拼接即可,可以去网上免费代理中寻找:http://www.xicidaili.com/nn
proxies = {"https": "https://127.0.0.1:1080", "http": "http://127.0.0.1:1080"}
response = requests.get(url=start_url, headers=headers, proxies=proxies)
print(response) # 返回值:<Response [200]>
除此之外get还有很多请求参数,如timeout你可以设置请求时间,如果超过这个时间变自行结束请求,可以利用此判断请求代理的相应效率,避免在某些错误请求上浪费过多的时间。
3.requests.post()方法使用—构造formdata表单
post请求方式的使用和get方式并没有很大的区别,本质的区别在于它传递参数的方式并不像get方式一样,通过在url中拼接字段来发送给服务器,他采取了一种相较之下更为安全的操作方式,通过form表单的方式来向服务器传递查询条件。我们同样可以通过浏览器的F12开发者工具或者fiddler抓包工具来看到formdata这个字段,从中获取form表单中的字段信息,很多登录操作就是基于此。操作方式如下:
import requests
url = 'https://en.artprecium.com/catalogue/vente_309_more-than-unique-multiples-estampes/resultat'
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Language": "zh",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "PHPSESSID=m2hbrvp548cg6v4ssp0l35kcj7; _ga=GA1.2.2052701472.1532920469; _gid=GA1.2.1351314954.1532920469; __atuvc=3%7C31; __atuvs=5b5e9a0418f6420c001",
"Host": "en.artprecium.com",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
}
# 构造form表单
data = {"IdEpoque": "",
"MotCle": "",
"Order": "",
"LotParPage": "All",
"IdTypologie": ""}
response = requests.post(url=url, data=data, headers=headers, timeout=10)
print(response) # 返回值:<Response [200]>
上面是一个电商网站的post请求查询的案例,当我们对页面显示商品数量进行更改时发现我们的url并没有发生改变,此时,我们便可以分析此动作是由ajax异步加载或者是通过post的请求方式来更改,我们可以通过开发者工具来获取我们想要的信息。
目标网址测试
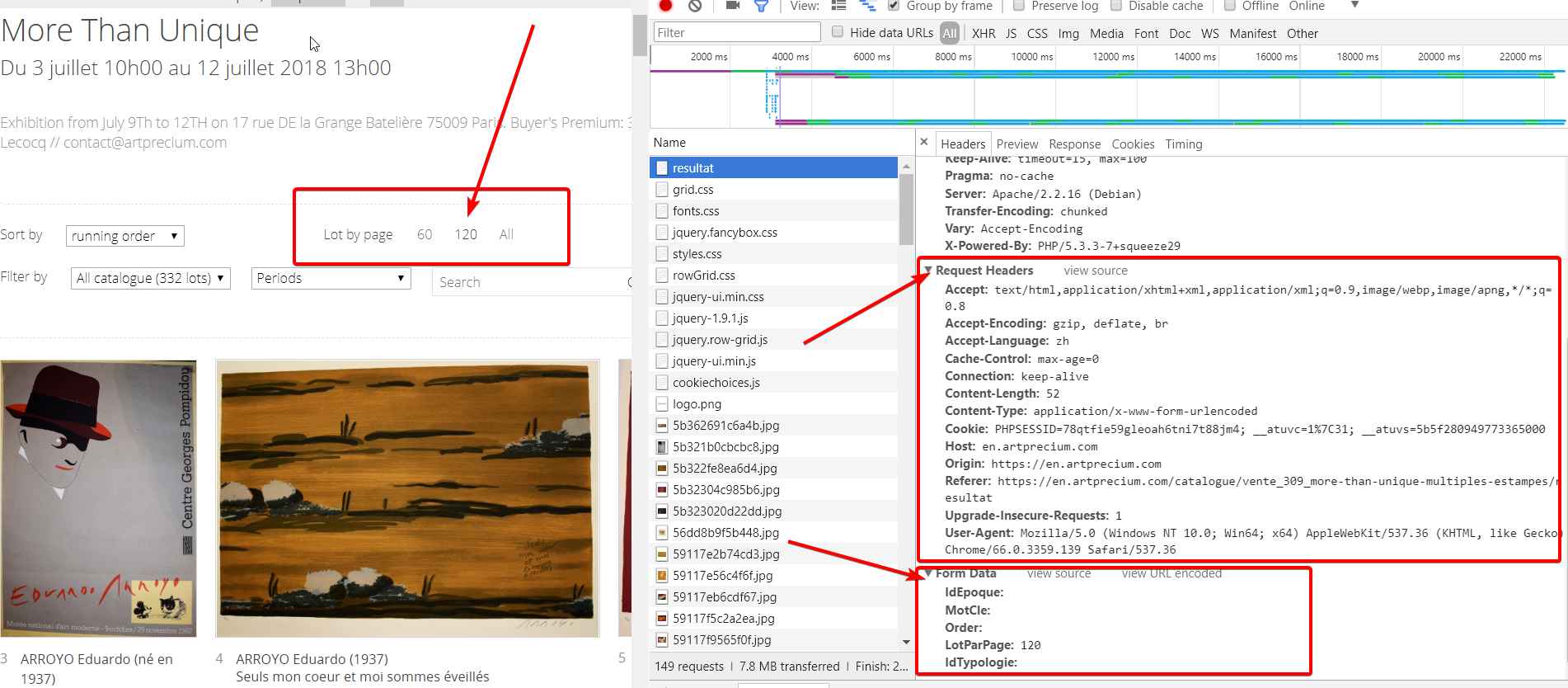
我们可以很容易的看到请求头信息和form表单信息,通过修改LotParPage字段信息可以获得不同数量商品的响应,在实际操作过程中要通过自己的测试确定headers中所必需的字段和自定义我们的form表单从而完成请求,对于post的其他参数和get大致相同,基本通用,有兴趣的话可以去官方查看requests的api文档。
4.requests.post()方法使用—发送json数据
post除了构造表单以外还可以像通过像服务器发送json信息的方式获取正确的请求,利用的便是中post(json={"key":"value"})的方式,操作流程大致与post发送form表单相似,案例是一个国外网站的demo,虽然全是一些看不懂的文字,但是无伤大雅,看个流程就好,目标网址:http://anticvarium/auction/archive
从这个页面中我们可以得到一个专场列表页,每个专场中有许多商品,当我们直接去请求每个专场的URL时不会得到任何结果,我们可以从开发者工具中找到他的真实接口,如下图所示
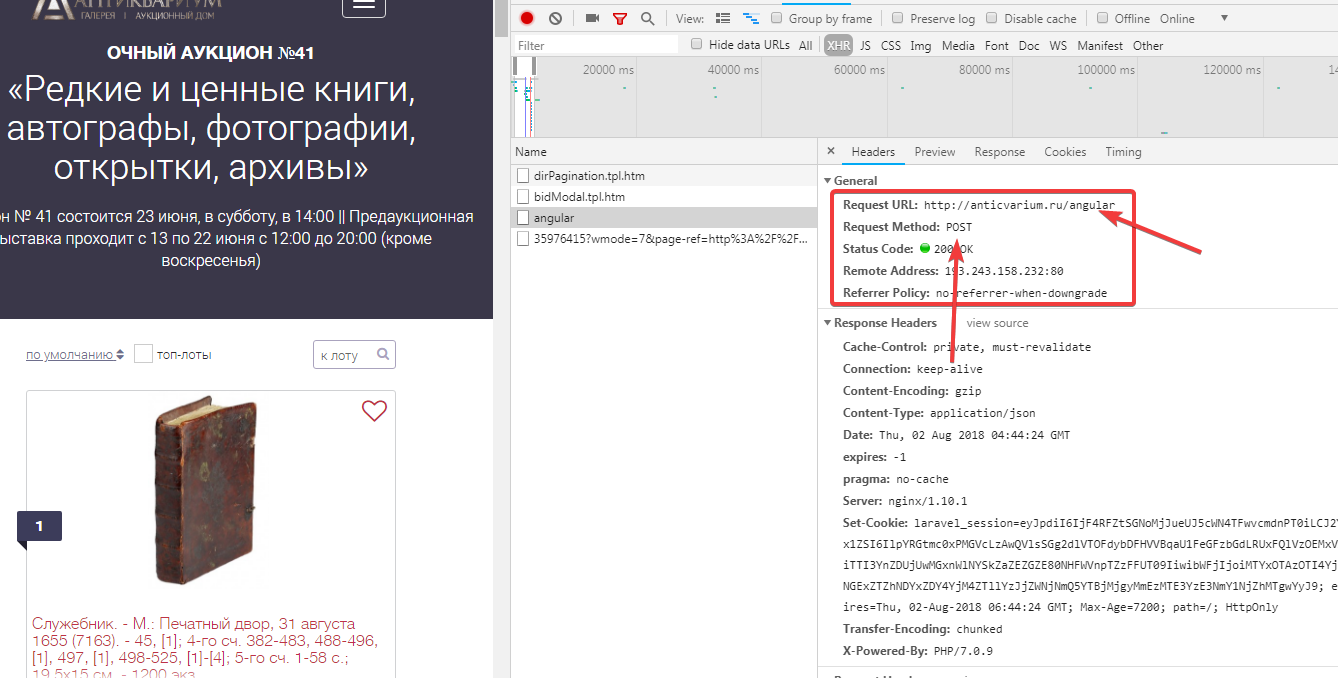
我们在看它像服务器传递的信息:
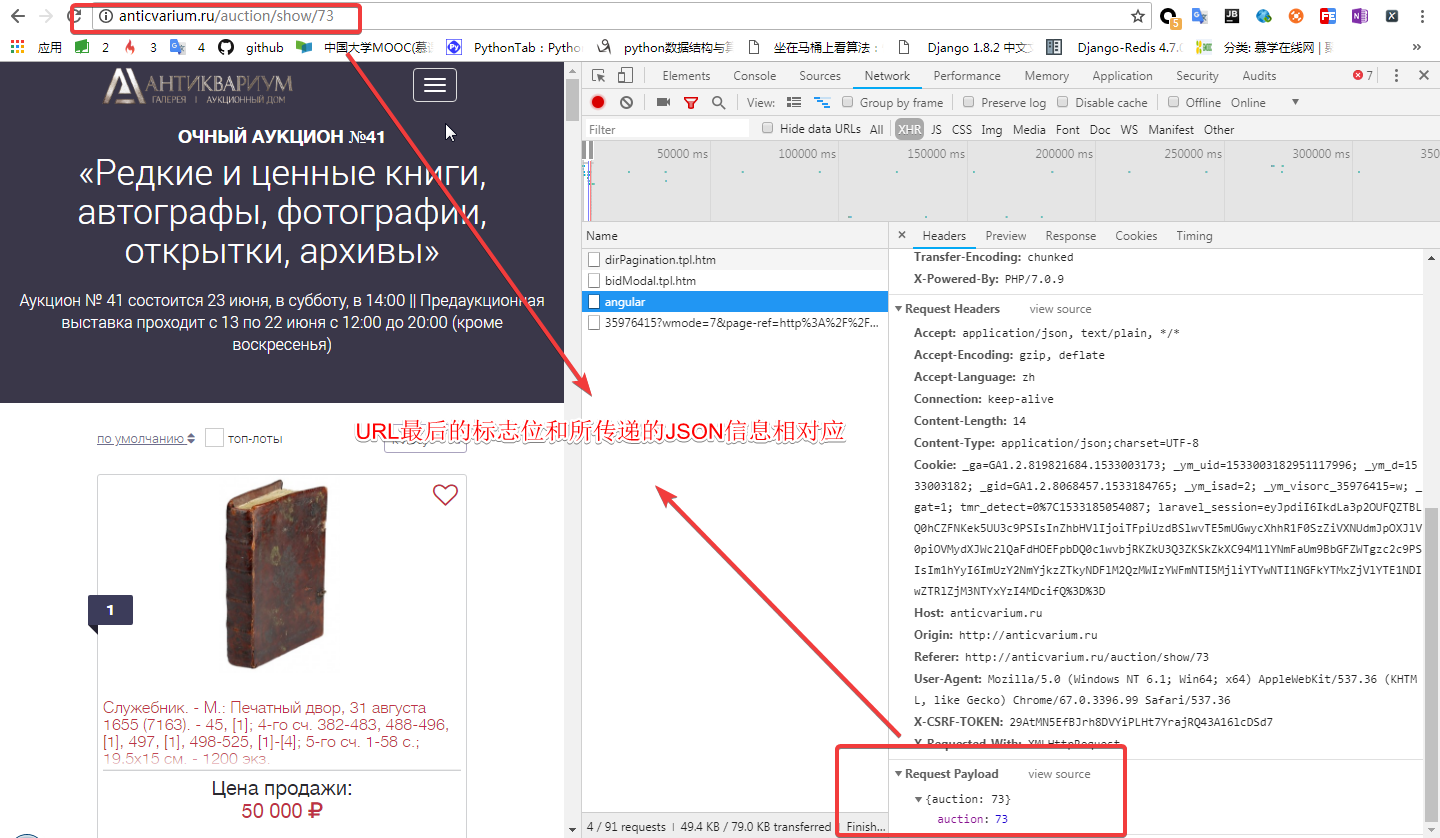
通过以上的分析,我们可以
url = 'http://anticvarium/angular'
headers = {
"Host": "anticvarium",
"Connection": "keep-alive",
"Content-Length": "14",
"Origin": "http://anticvarium",
"X-CSRF-TOKEN": "u1InfvhE23slcmReIJlgvI7IGzb3xQEvXHQbP3Bc",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Content-Type": "application/json;charset=UTF-8",
"Accept": "application/json, text/plain, */*",
"X-Requested-With": "XMLHttpRequest",
"Referer": "http://anticvarium/auction/show/66",
"Accept-Language": "zh",
"Cookie": "_ga=GA1.2.819821684.1533003173; _gid=GA1.2.258681840.1533003173; _ym_uid=1533003182951117996; _ym_d=1533003182; _ym_isad=2; _ym_visorc_35976415=w; tmr_detect=0%7C1533004777867; laravel_session=eyJpdiI6InZNSTlWSlYyUW1BaitUWTNBSjJKckE9PSIsInZhbHVlIjoibWprTDFxeTZZc0lOS2VTcmxIdzZJSkwwTVFXOHphN2FwTysxbXNHSDkybXE0VUZYakpTUlZ5Ykh6U2pFTTVJTWdWUHBUaVJwVGl1Q3RlTjdRQUhKNEE9PSIsIm1hYyI6IjQ5NmIwMGYxNDllZDFiNTY2ZmFjYWY5NjEyOTQ4MTZjYzQzNmFiY2EyMzFiOTY1Mzg3ODUyZTllN2U0MTQwYTEifQ%3D%3D",
}
response = requests.post(url, headers=headers, json={"auction": 66})
print(response) # 返回值:<Response [200]>
Python爬虫—requests库get和post方法使用的更多相关文章
- 【Python成长之路】Python爬虫 --requests库爬取网站乱码(\xe4\xb8\xb0\xe5\xa)的解决方法【华为云分享】
[写在前面] 在用requests库对自己的CSDN个人博客(https://blog.csdn.net/yuzipeng)进行爬取时,发现乱码报错(\xe4\xb8\xb0\xe5\xaf\x8c\ ...
- python爬虫---requests库的用法
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下 ...
- Python爬虫---requests库快速上手
一.requests库简介 requests是Python的一个HTTP相关的库 requests安装: pip install requests 二.GET请求 import requests # ...
- Python爬虫--Requests库
Requests Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,requests是python实现的最简单易用的HTTP库, ...
- python爬虫——requests库使用代理
在看这篇文章之前,需要大家掌握的知识技能: python基础 html基础 http状态码 让我们看看这篇文章中有哪些知识点: get方法 post方法 header参数,模拟用户 data参数,提交 ...
- Python爬虫 requests库基础
requests库简介 requests是使用Apache2 licensed 许可证的HTTP库. 用python编写. 比urllib2模块更简洁. Request支持HTTP连接保持和连接池,支 ...
- Python 爬虫-Requests库入门
2017-07-25 10:38:30 response = requests.get(url, params=None, **kwargs) url : 拟获取页面的url链接∙ params : ...
- python中requests库使用方法详解
目录 python中requests库使用方法详解 官方文档 什么是Requests 安装Requests库 基本的GET请求 带参数的GET请求 解析json 添加headers 基本POST请求 ...
- python爬虫---selenium库的用法
python爬虫---selenium库的用法 selenium是一个自动化测试工具,支持Firefox,Chrome等众多浏览器 在爬虫中的应用主要是用来解决JS渲染的问题. 1.使用前需要安装这个 ...
随机推荐
- struts2方法无法映射问题:There is no Action mapped for namespace [/] and action name [m_hi] associated with context path []
使用struts的都知道,下面使用通配符定义的方式很常见,并且使用也很方便: <action name="Crud_*" class="example.Crud&q ...
- 清空echarts的option
将相应的echarts的option治为空 $("#tt5sbmc").html("");
- 走进JavaWeb技术世界4:Servlet 工作原理详解
从本篇开始,正式进入Java核心技术内容的学习,首先介绍的就是Java web应用的核心规范servlet 转自:https://www.ibm.com/developerworks/cn/java/ ...
- Projects: Linux scalability: Accept() scalability on Linux 惊群效应
小结: 1.不必要的唤醒 惊群效应 https://github.com/benoitc/gunicorn/issues/792#issuecomment-46718939 https://www.c ...
- WebView调用js方法获取返回值的完美解决方案
在Android项目中我们或多或少会涉及到与js交互的问题,这其中WebView是必须掌握的控件,今天主要说说我们通过WebView调用js方法,然后如何很好的获取返回值.这里我总结了三种方式,大家可 ...
- C之输入输出
%d - int%ld – long (long int)%lld - long long%hd – short 短整型 (half int) %c - char%f - float%lf – dou ...
- Eclipse的下载地址
下载地址:http://eclipse.org/
- 12 Flutter仿京东商城项目 商品列表页面请求数据、封装Loading Widget、上拉分页加载更多
ProductList.dart import 'package:flutter/material.dart'; import '../services/ScreenAdaper.dart'; imp ...
- 【403】COMP9024 Exercise
Week 1 Exercises fiveDigit.c There is a 5-digit number that satisfies 4 * abcde = edcba, that is,whe ...
- JAVA 基础编程练习题34 【程序 34 三个数排序】
34 [程序 34 三个数排序] 题目:输入 3 个数 a,b,c,按大小顺序输出. 程序分析:利用指针方法. package cskaoyan; public class cskaoyan34 { ...