正则爬取京东商品信息并打包成.exe可执行程序。
本文爬取内容,输入要搜索的关键字可自动爬取京东网站上相关商品的店铺名称,商品名称,价格,爬取100页(共100页)
代码如下;
import requests
import re
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
} def get_all(url,key):
for page in range(1,200,2):
params = {
'keyword':key,
'enc':'utf-8',
'page':page
}
num = int((int(page)+1)/2)
try:
response = requests.get(url=url,params=params,headers=headers)
# 转码
content = response.text.encode(response.encoding).decode(response.apparent_encoding)
data_all = re.findall('<div class="p-price">.*?<i>(.*?)</i>.*?<div class="p-name p-name-type-2">.*?title="(.*?)"'
'.*?<div class="p-shop".*?title="(.*?)"',content,re.S)
for i in data_all:
with open(key + '.txt', 'a+', encoding='utf-8') as f:
f.write('店铺名称:' + i[2]+'\n'+'商品名称:'+i[1]+'\n'+'价格:'+i[0]+'\n\n')
print('第'+str(num)+'页'+'数据下载中....')
except Exception as e:
print(e) if __name__ == '__main__':
print('输入要搜索的内容,获取京东商城里面的商品名称,店铺名称,商品价格')
key = input('输入搜索内容:')
url = 'https://search.jd.com/Search?'
get_all(url,key)
打包成.exe可执行文件。
需要用到pyinstaller包pip下载;
pip install pyinstaller
在线制作一个.ico图标,用来当程序图片,把图标和程序放在同一个文件夹下,

在.py文件目录下打开命令行窗口,执行打包命令;
E:\练习\最后阶段\0808\jd1>pyinstaller -F -i dog.ico jd.py
出现successfully表示打包成功;
27525 INFO: Building EXE from EXE-00.toc completed successfully.
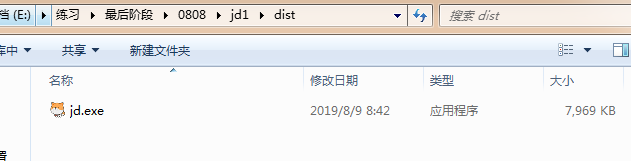
可执行程序在当前文件夹下的dist文件夹下;
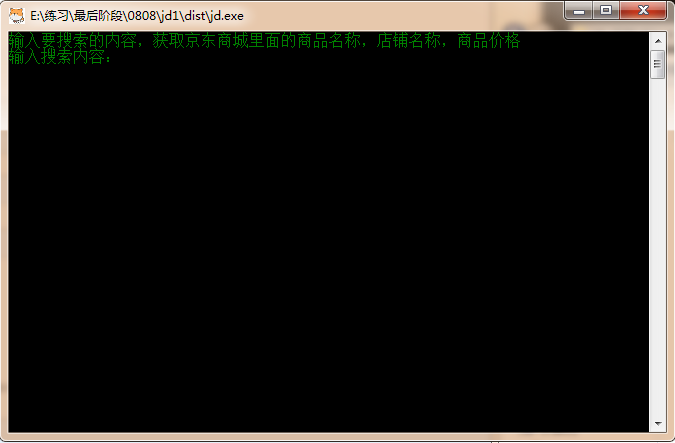
运行效果;
可同时执行多个程序;
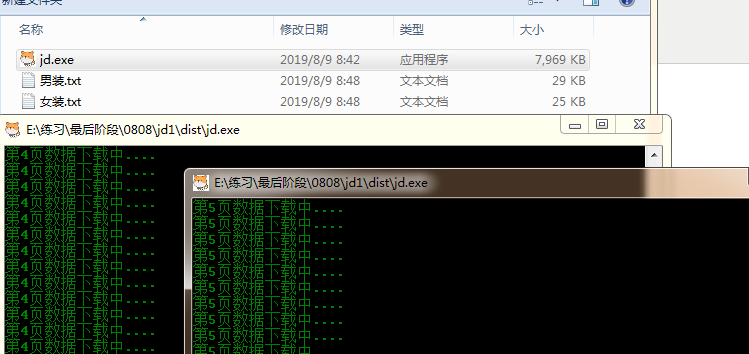
输出结果;
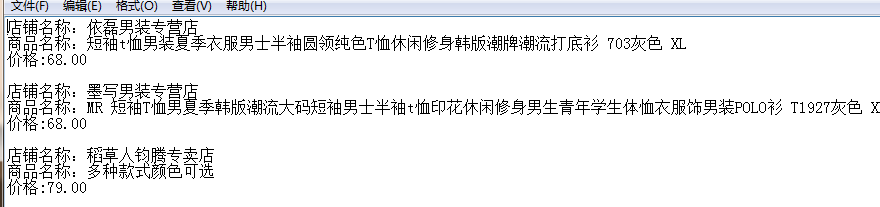
done。
正则爬取京东商品信息并打包成.exe可执行程序。的更多相关文章
- 正则爬取京东商品信息并打包成.exe可执行程序
本文爬取内容,输入要搜索的关键字可自动爬取京东网站上相关商品的店铺名称,商品名称,价格,爬取100页(共100页) 代码如下: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 1 ...
- selenium+phantomjs爬取京东商品信息
selenium+phantomjs爬取京东商品信息 今天自己实战写了个爬取京东商品信息,和上一篇的思路一样,附上链接:https://www.cnblogs.com/cany/p/10897618. ...
- Python爬虫-爬取京东商品信息-按给定关键词
目的:按给定关键词爬取京东商品信息,并保存至mongodb. 字段:title.url.store.store_url.item_id.price.comments_count.comments 工具 ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- 八个commit让你学会爬取京东商品信息
我发现现在不用标题党的套路还真不好吸引人,最近在做相关的事情,从而稍微总结出了一些文字.我一贯的想法吧,虽然才疏学浅,但是还是希望能帮助需要的人.博客园实在不适合这种章回体的文章.这里,我贴出正文的前 ...
- python爬虫——用selenium爬取京东商品信息
1.先附上效果图(我偷懒只爬了4页) 2.京东的网址https://www.jd.com/ 3.我这里是不加载图片,加快爬取速度,也可以用Headless无弹窗模式 options = webdri ...
- 爬虫之selenium爬取京东商品信息
import json import time from selenium import webdriver """ 发送请求 1.1生成driver对象 2.1窗口最大 ...
- Java爬虫爬取京东商品信息
以下内容转载于<https://www.cnblogs.com/zhuangbiing/p/9194994.html>,在此仅供学习借鉴只用. Maven地址 <dependency ...
随机推荐
- element ui表格常用功能如:导出 新增 删除 多选 跨页多选 固定表头 多级表头 合并行列 等常见需求
<template> <div class="table-cooperte"> <el-table :data="tableData&quo ...
- IntelliJ Idea 常用10款插件(提高开发效率)
出自:https://blog.csdn.net/weixin_41846320/article/details/82697818 插件安装方式: 1.Background Image Plus 这款 ...
- javascript中var、let、const的区别
这几天修改别人的js,发现声明变量有的用var,有的用let,那它们有什么区别呢? javascript中声明变量的方式有:var.let.const 1.var (1)作用域: 整个函数范围内,或者 ...
- 【洛谷5537】【XR-3】系统设计(哈希_线段树上二分)
我好像国赛以后就再也没有写过 OI 相关的博客 qwq Upd: 这篇博客是 NOIP (现在叫 CSP 了)之前写的,但是咕到 CSP 以后快一个月才发表 -- 我最近这么咕怎么办啊 -- 题目 洛 ...
- json对象转js对象
json数据: { "YD1": 0, "YD2": 0, "YD3": 0, "YD4": 0, "YD5& ...
- JVM堆内存参数优化,让性能飞起来
堆内存是Java进程的重要组成部分,几乎所有与应用相关的内存空间都和堆有关.现在主要介绍与堆内存相关的参数设置,这些参数对Java虚拟机中非常重要的,也是对程序性能有着重要的影响.让你彻底脱离OOM内 ...
- Listener学习
监听器Listener用于监听web应用中某些对象.信息的创建.销毁.增加,修改,删除等动作的发生,然后作出相应的响应处理.当范围对象的状态发生变化的时候,服务器自动调用监听器对象中的方法.常用于统计 ...
- Tkint中Label&Button&Scale的使用
top.geometry()设定窗口的初始大小 scale.set()设定滑块的初始值 scale.get()获取滑块变化的值 控件通过回调函数与其他控件进行通信(Label控件中的文本会受到Scal ...
- AVR单片机教程——数码管
先解答之前一个思考题:如果不把引脚配置为输出而写高电平,连接LED会怎样? 实验结果是,LED会亮,但相比于输出高电平的情况,亮度很低.这是为什么呢? 通过上一篇教程我们知道,引脚输入输出模式是由寄存 ...
- mongodb常规操作语句
db.c_user.insertOne({ name: "ljm", pwd: "123456" }); //插入一个 db.c_user.insertMany ...