weighted Kernel k-means 加权核k均值算法理解及其实现(一)
那就从k-means开始吧
对于机器学习的新手小白来说,k-means算法应该都会接触到吧。传统的k-means算法是一个硬聚类(因为要指定k这个参数啦)算法。这里利用百度的解释
它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。K-means算法以欧式距离作为相似度测度,它是求对应某一初始聚类中心向量V最优分类,使得评价指标J最小。算法采用误差平方和准则函数作为聚类准则函数。
看上去好难懂,实际上任务就是要聚类,然后将相关的点聚成一堆嘛。这里我们可以给出k-means的核心公式
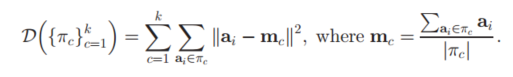
这里可以看到,实际上就是计算每个样本点簇中心的距离,然后判断出到哪个簇中心距离最短,然后分给那个簇。然后下次迭代时,簇中心就按照新分配的点重新进行计算了,然后所有的点再同样计算样本点到簇中心的距离,重新分配到不同的簇中。所以这样不断迭代下去,就能够收敛了,得到最后的聚类效果。
加上“核”?那就成了Kernel k-means
“核”是什么
核函数的方法已经被提出很久了,也得到了很多的推广应用。很多算法参进了核函数,就变得有趣得多。核函数通常与SVM经常结合在一起进行使用。总的来说,核函数,就是将输入空间,映射到高维的特征空间。然后再在高维的数据同看进行数据处理。这种映射的话,是非线性变换的,这也才能能够将输入空间映射出不同特征的高维空间。
当然,要给出这种非线性运算的确切算法,是很困难的。所以当我们的现实运算算法求解时候只用到了样本点的内积运算时候,而在低维输入空间中,我们有能够得到某个函数K(x,x′),它恰好等于在高维空间中这个内积,即K( x, x′) =<φ( x) ⋅φ( x′) > 。
那么这样就好办了,只要我们每次计算样本点投射到高维空间的值进行内积运算时,我们直接只需要使用函数K(x,x′),就可以得到。这就避免了我们将样本点映射到高维空间的操作,减少了计算的难度和复杂度。所以每次进行运算,只需要运算K(x,x′)即可。(理解这一点很重要噢,为下面Kernel k-means做铺垫)
那就给 k-means 加个“核”吧
核k-means,概括地来说,就是将数据点都投影到了一个高维的特征空间中(为啥要这么做呢,主要是突显出不同样本中的差异),然后再在这个高维的特征空间中,进行传统的k-means聚类。主要的思想就是这么简单,比起传统普通的k-means就多了一个步核函数的操作。所以它的公式也与传统k-means很相近:

这里所表示的,$a_i$是各个样本点,而$\phi( )$函数,则是表示将样本点映射至高维空间。而公式中的$m_c$,则是每个簇中的质心。
这个形式,对比起普通的k-means是不是很相近咧,同样是求各个高维空间中的样本特征(传统k-means中是样本点)与质心的距离,然后根据该样本点到不同质心距离,选择最小的(也就是说距离该样本点最近)的簇心,进行分配(将该样本点归为这个簇)。
这就让我们想起普通k-means的计算了,先算出各个簇具体簇心的具体值,然后就对所有样本点重新计算到各个簇心的距离,然后进行重新分派。
然而,在kernel k-means中,计算方法普通k-means大有不同。首先,在上述的公式中,$\phi(a_i)$,这个我们是很难算出来的。因为之前说明核函数的时候提到,这个这种非线性的函数映射,我们很难去得到准确的函数算法;其次,对于每个簇的中心$m_c$,即使我们有簇内所有点的数据,但我们也还是是很难去准确描述这个中心的。
因此,我们要开始对这个公式进行改造啦。
首选,我们将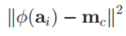
改写成
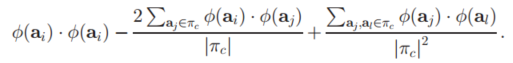
这个变化很明显是将这个平方公式进行展开,然后对$m_c$进行了替换,因为$m_c$实际上就是簇内所有数据所决定的。但是我们难以准确去表示而已,但是我们在算法等价上,这样运算的结果还是与质心相同的。
所以我们最终要计算的公式也发生了变化。将原本的完全平方式,进行了展开。
观察上面的完全平方展开式,我们可以发现:每一项中,需要使用到高维特征空间的值,都是在进行内积运算。因此符合我们之前所提到的,使用一个矩阵K函数,来代表高维特征空间中这两个值的内积结果。
即$k<a_i,a_j>$等价于$\phi(a_j)\phi(a_i)$。这样子,我们就根本不用管$\phi()$这个函数实际的运算定义是怎样的了。只需要使用到这两个特征进行相乘的结果。
来个小结
kernel k-means实际上公式上,就是将每个样本进行一个投射到高维空间的处理,然后再将处理后的数据使用普通的k-means算法思想进行聚类。
在计算上的话,由于要映射到高维空间中,而且还要找出各个簇的中心。这些如果没有能够得到映射到高维空间的函数,是很难直接计算到的。但是我们可以观察到,我们所要计算的公式,最终并不需要知道单独的一个样本点映射到高维空间的特征值,而是两个高维空间特征值的内积。所以,我们只需要得到一个K矩阵,矩阵中每个元素都表示高维空间,这两个样本点映射成特征后,进行内积计算所得到的结果。所以这个矩阵,实际上就是一个核函数矩阵。
那就再加上权重w来个weighted kernel k-means吧
看到这里,应该起码对kernel k-means有个理解吧。然后我们还要在这个基础,再加上一个权重w,也就是对每一个样本点,都给出一个权重$w_j$,区分出不同样本点的重要性。所以的话,我们的公式又增添了一点东西:
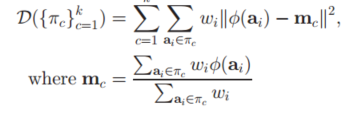
这里可以看到,公式中计算样本高维空间特征到簇中心距离 的平方后,还乘以了一个权重$w_j$,对于不同的样本点,其权重都可能不同。所以就只是简单地乘多了一个权重,公式的计算方法跟 kernel k-means还是很相似的。
我们将平方项展开,然后将$m_c$项进行替换。然后我们的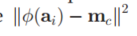
得到以下结果:
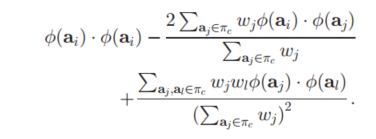
如果我们再将其中的$\phi(a_i)\phi(a_i)$使用K的核函数矩阵($K(a_i,a_j)=phi(a_i)\phi(a_i)$)进行替换,则得到以下结果:
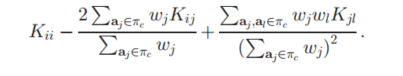
简直完美,是吧。
下篇预告
时间比较紧,所以就先写这些,关于算法的实现细节,以及复杂度分析。将于下篇介绍。
算法代码已经推上了码云,有兴趣的小伙伴可以clone下来把玩。
https://git.oschina.net/subaiDeng/Kernel-k-means
另外,写这篇博客,是参考了正在查阅的一篇论文:
《Weighted Graph Cuts without Eigenvectors : A Multilevel Approach》
Yuqiang Guan and Brian Kulis
大家有兴趣也可以去看看。
花絮
本人学浅才疏,若在书写内容或者表达方式上存在错误,欢迎大家指出,也欢迎大家一起讨论。
weighted Kernel k-means 加权核k均值算法理解及其实现(一)的更多相关文章
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 聚类--K均值算法
import numpy as np from sklearn.datasets import load_iris iris = load_iris() x = iris.data[:,1] y = ...
- 第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
import numpy as np x = np.random.randint(1,100,[20,1]) y = np.zeros(20) k = 3 def initcenter(x,k): r ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 【机器学习】K均值算法(II)
k聚类算法中如何选择初始化聚类中心所在的位置. 在选择聚类中心时候,如果选择初始化位置不合适,可能不能得出我们想要的局部最优解. 而是会出现一下情况: 为了解决这个问题,我们通常的做法是: 我们选取K ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
随机推荐
- HTML——UL+CSS设计
截图例如,下面的: <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/ ...
- sharepoint 2013 userprofile 用户信息
Sharepoint2013获得当前用户userfrofile 基本介绍: 什么使用户配置文件. 用户属性和用户配置文件属性提供有关 SharePoint 用户的信息,如显示名称.电子邮件.标题以及其 ...
- oracle看到用户的所有表名、表睐、字段名称、现场的目光、是空的、字段类型
--oracle看到用户的所有表名.表睐.字段名称.现场的目光.是空的.字段类型 select distinct TABLE_COLUMN.*, TABLE_NALLABLE.DATA_TYPE, T ...
- C#开发Linux守护进程
用C#开发Linux守护进程 Linux守护进程(Daemon)是Linux的后台服务进程,它脱离了与控制终端的关联,直接由Linux init进程管理其生命周期,即使你关闭了控制台,daemon ...
- FZU2082
树链剖分后要处理的是边的权值,而不是点的权值,但是只要边权下放到点,就可以了 如图 但是问题是,求图4->5路径的权值之和, 那么就会把点3给算进去 那么就要减去, 或者干脆不加进去 有两种方法 ...
- 报错compile_str() flow.php on line 375的解决方法
flow.php line 375,flow.php 找到375行: * 保存收货人信息 */ $consignee = array( 'address_id' => empty($_POST ...
- sgu 286. Ancient decoration(最小环覆盖)
给你一个n个点,每个点度为k(k为偶数)的无向图,问是否能将图中的n条边染色,使得每个点都拥有两条被染色的边.也就是说,是否存在拥有原图中n条边的子图,使得每个点的度为2?仔细想想,每个点的度为2,实 ...
- 【前段开发】行内元素和块级元素总结(HTML CSS)
块级元素 <address> information on author <blockquote> long quotation <button> push but ...
- EJB_消息驱动发展bean
消息驱动发展bean Java信息服务(Java MessageService) Java 信息服务(Java Message Service,简称 JMS)是用于訪问企业消息系统的开发商中立的API ...
- datagrid标题头粗体
//标题头粗体 //$("#R_datagrid .datagrid-header-row td div span").each(function (i, th) { ...