scrapy框架中多个spider,tiems,pipelines的使用及运行方法
用scrapy只创建一个项目,创建多个spider,每个spider指定items,pipelines.启动爬虫时只写一个启动脚本就可以全部同时启动。
本文代码已上传至github,链接在文未。
一,创建多个spider的scrapy项目
scrapy startproject mymultispider
cd mymultispider
scrapy genspider myspd1 sina.com.cn
scrapy genspider myspd2 sina.com.cn
scrapy genspider myspd3 sina.com.cn
二,运行方法
1.为了方便观察,在spider中分别打印相关信息
import scrapy
class Myspd1Spider(scrapy.Spider):
name = 'myspd1'
allowed_domains = ['sina.com.cn']
start_urls = ['http://sina.com.cn/'] def parse(self, response):
print('myspd1')
其他如myspd2,myspd3分别打印相关内容。
2.多个spider运行方法有两种,第一种写法比较简单,在项目目录下创建crawl.py文件,内容如下
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # myspd1是爬虫名
process.crawl('myspd1')
process.crawl('myspd2')
process.crawl('myspd3') process.start()
为了观察方便,可在settings.py文件中限定日志输出
LOG_LEVEL = 'ERROR'
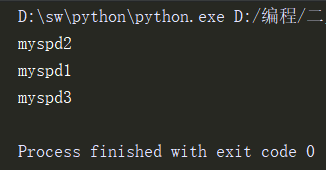
右键运行此文件即可,输出如下
3.第二种运行方法为修改crawl源码,可以从官方的github中找到:https://github.com/scrapy/scrapy/blob/master/scrapy/commands/crawl.py
在spiders目录的同级目录下创建一个mycmd目录,并在该目录中创建一个mycrawl.py,将crawl源码复制进来,修改其中的run方法,改为如下内容
def run(self, args, opts):
# 获取爬虫列表
spd_loader_list = self.crawler_process.spider_loader.list()
# 遍历各爬虫
for spname in spd_loader_list or args:
self.crawler_process.crawl(spname, **opts.spargs)
print("此时启动的爬虫:" + spname)
self.crawler_process.start()
在该文件的目录下创建初始化文件__init__.py
完成后机构目录如下

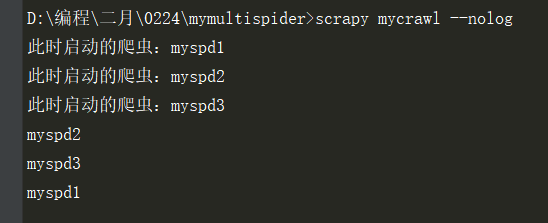
使用命令启动爬虫
scrapy mycrawl --nolog
输出如下:
三,指定items
1,这个比较简单,在items.py文件内创建相应的类,在spider中引入即可
items.py
import scrapy class MymultispiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass class Myspd1spiderItem(scrapy.Item):
name = scrapy.Field() class Myspd2spiderItem(scrapy.Item):
name = scrapy.Field() class Myspd3spiderItem(scrapy.Item):
name = scrapy.Field()
spider内,例myspd1
# -*- coding: utf-8 -*-
import scrapy
from mymultispider.items import Myspd1spiderItem class Myspd1Spider(scrapy.Spider):
name = 'myspd1'
allowed_domains = ['sina.com.cn']
start_urls = ['http://sina.com.cn/'] def parse(self, response):
print('myspd1')
item = Myspd1spiderItem()
item['name'] = 'myspd1的pipelines'
yield item
四,指定pipelines
1,这个也有两种方法,方法一,定义多个pipeline类:
pipelines.py文件内:
class Myspd1spiderPipeline(object):
def process_item(self,item,spider):
print(item['name'])
return item class Myspd2spiderPipeline(object):
def process_item(self,item,spider):
print(item['name'])
return item class Myspd3spiderPipeline(object):
def process_item(self,item,spider):
print(item['name'])
return item
1.1settings.py文件开启管道
ITEM_PIPELINES = {
# 'mymultispider.pipelines.MymultispiderPipeline': 300,
'mymultispider.pipelines.Myspd1spiderPipeline': 300,
'mymultispider.pipelines.Myspd2spiderPipeline': 300,
'mymultispider.pipelines.Myspd3spiderPipeline': 300,
}
1.2spider中设置管道,例myspd1
# -*- coding: utf-8 -*-
import scrapy
from mymultispider.items import Myspd1spiderItem class Myspd1Spider(scrapy.Spider):
name = 'myspd1'
allowed_domains = ['sina.com.cn']
start_urls = ['http://sina.com.cn/']
custom_settings = {
'ITEM_PIPELINES': {'mymultispider.pipelines.Myspd1spiderPipeline': 300},
} def parse(self, response):
print('myspd1')
item = Myspd1spiderItem()
item['name'] = 'myspd1的pipelines'
yield item
指定管道的代码
custom_settings = {
'ITEM_PIPELINES': {'mymultispider.pipelines.Myspd1spiderPipeline': 300},
}
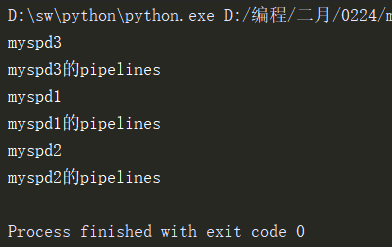
1.3运行crawl文件,运行结果如下
2,方法二,在pipelines.py文件内判断是哪个爬虫的结果
2.1 pipelines.py文件内
class MymultispiderPipeline(object):
def process_item(self, item, spider):
if spider.name == 'myspd1':
print('myspd1的pipelines')
elif spider.name == 'myspd2':
print('myspd2的pipelines')
elif spider.name == 'myspd3':
print('myspd3的pipelines')
return item
2.2 settings.py文件内只开启MymultispiderPipeline这个管道文件
ITEM_PIPELINES = {
'mymultispider.pipelines.MymultispiderPipeline': 300,
# 'mymultispider.pipelines.Myspd1spiderPipeline': 300,
# 'mymultispider.pipelines.Myspd2spiderPipeline': 300,
# 'mymultispider.pipelines.Myspd3spiderPipeline': 300,
}
2.3spider中屏蔽掉指定pipelines的相关代码
# -*- coding: utf-8 -*-
import scrapy
from mymultispider.items import Myspd1spiderItem class Myspd1Spider(scrapy.Spider):
name = 'myspd1'
allowed_domains = ['sina.com.cn']
start_urls = ['http://sina.com.cn/']
# custom_settings = {
# 'ITEM_PIPELINES': {'mymultispider.pipelines.Myspd1spiderPipeline': 300},
# } def parse(self, response):
print('myspd1')
item = Myspd1spiderItem()
item['name'] = 'myspd1的pipelines'
yield item
2.4 运行crawl.py文件,结果如下

代码git地址:https://github.com/terroristhouse/crawler
python系列教程:
链接:https://pan.baidu.com/s/10eUCb1tD9GPuua5h_ERjHA
提取码:h0td

scrapy框架中多个spider,tiems,pipelines的使用及运行方法的更多相关文章
- scrapy框架中Spiders用法
scrapy框架中Spiders用法 Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据 总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以 ...
- Scrapy框架中的CrawlSpider
小思考:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法二: ...
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- 爬虫(十五):Scrapy框架(二) Selector、Spider、Downloader Middleware
1. Scrapy框架 1.1 Selector的用法 我们之前介绍了利用Beautiful Soup.正则表达式来提取网页数据,这确实非常方便.而Scrapy还提供了自己的数据提取方法,即Selec ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- python学习之-用scrapy框架来创建爬虫(spider)
scrapy简单说明 scrapy 为一个框架 框架和第三方库的区别: 库可以直接拿来就用, 框架是用来运行,自动帮助开发人员做很多的事,我们只需要填写逻辑就好 命令: 创建一个 项目 : cd 到需 ...
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
随机推荐
- context:component-scan标签的诠释
XML中配置context:component-scan时,spring会自动的扫描这个包下被这些注解标识的类@Component,@Service,@Controller,@Repository,同 ...
- Asp.Net Core 3.1 Api 集成Abp项目依赖注入
Abp 框架 地址https://aspnetboilerplate.com/ 我们下面来看如何在自己的项目中集成abp的功能 我们新建core 3.1 API项目和一个core类库 然后 两个项目都 ...
- Java 8 Stream流编程学习
本文是自己学习菜鸟教程中总结的笔记,用于快速找代码,完整的文档见菜鸟教程:Java 8 Stream Stream 使用一种类似用SQL语句从数据库查询数据的直观方式来提供一种对Java集合运算和表达 ...
- ssh隧道使用
在内网中几乎所有的linux服务器和网络设备都支持ssh协议.一般情况下,ssh协议是允许通过防火墙和边界设备的,所以经常被攻击者利用.同时ssh协议的传输过程是加密的,所以我们很难区分合法的ssh会 ...
- Miniio安装登陆密码报错问题,注意检查区分带小写!
------------恢复内容开始------------ #创建minio专用文件目录mkdir -p /app/minio/datamkdir -p /app/minio/configchmod ...
- iperf安装使用教程
https://linoxide.com/monitoring-2/install-iperf-test-network-speed-bandwidth/
- CGI fastCgi php-fpm PHP-CGI 辨析
CGI fastCgi php-fpm PHP-CGI 辨析 LNMP环境中的nginx是不支持php的,需要通过fastcgi插件来处理有关php的请求.而php需要php-fpm这个组件提供该功能 ...
- .Net Core初识以及启动配置
.net程序员为什么要学习.net core .Net Core 是.Net的未来,微软在19年 5月已经明确说明,未来只有.Net 5(=.NET Core vNext),.Net 5是.net c ...
- input输入框联想功能
一直想找一个可以连接后台,可以根据后台内容的input输入框,可以实现联想功能,网上找到一个简单的静态页面的输入框联想,经过一番修改之后终于可以实现读取自己定义的数组的联想了,其实也比较简单就是格式的 ...
- 13、FrameRely
Frame Relay 美国国家标准化协会(American National Standard Institute,简称ANSI)国际电信联盟远程通信标准化组 ITU-T 1.是由ITU和ANSI制 ...