小爬爬5:scrapy介绍3持久化存储
一.两种持久化存储的方式
1.基于终端指令的吃持久化存储:
特点:终端指令的持久化存储,只可以将parse方法的返回值存储到磁盘文件
因此我们需要将上一篇文章中的author和content作为返回值的内容,我们可以将所有内容数据放在列表中,
每个字典存储作者名字和内容,最好将定义的列表返回即可
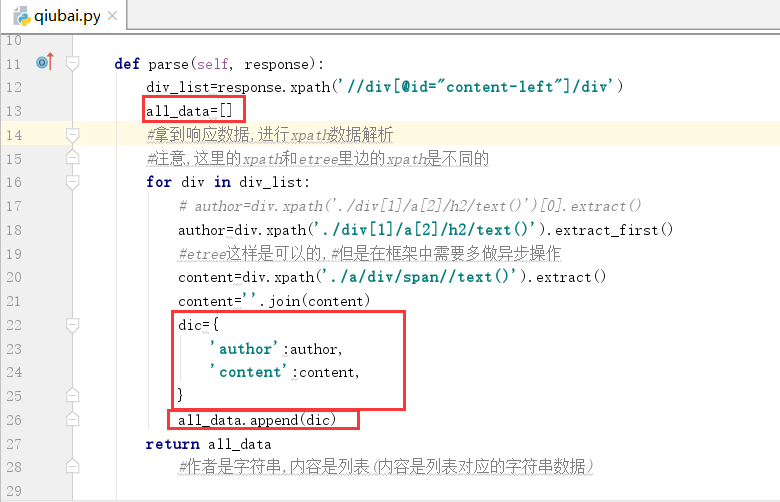
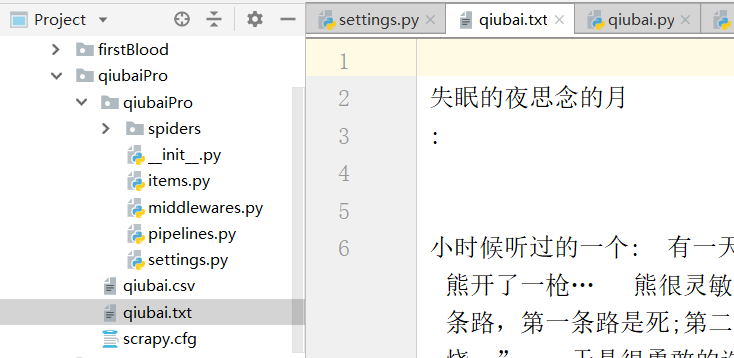
我们在下图的终端中运行下面的命令

我们右击整个爬虫工程,点击下面的选项,同步产生的数据
我们得到下面的qiubai.csv内容
思考可不可以保存到txt后缀的文件中?只支持下面的文件格式,因此不支持
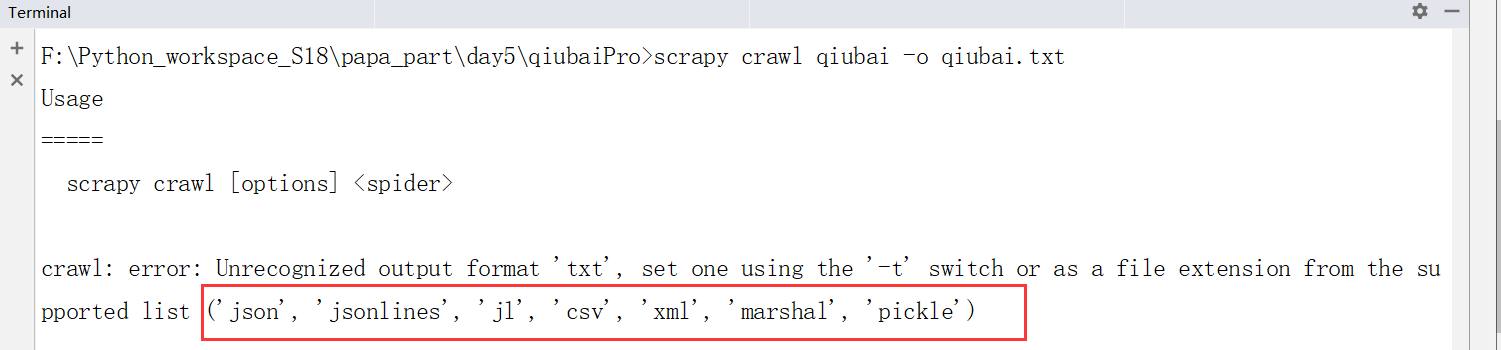
基于终端的命令:scrapy crawl qiubai -o qiubai.csv
优点:便捷
缺点:局限性强(只可以将数据写入本地文件,文件后缀是由具体要求)
2.基于管道的持久化存储
基于管道:
基于持久化存储的所有操作都必须写入到管道文件的管道类中
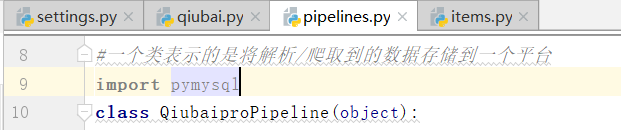
open io 以及数据库(mysql,redis等),pymysql等等都是基于持久化的存储操作
我们看到这个pipelines.py文件,以及这个文件中一个类
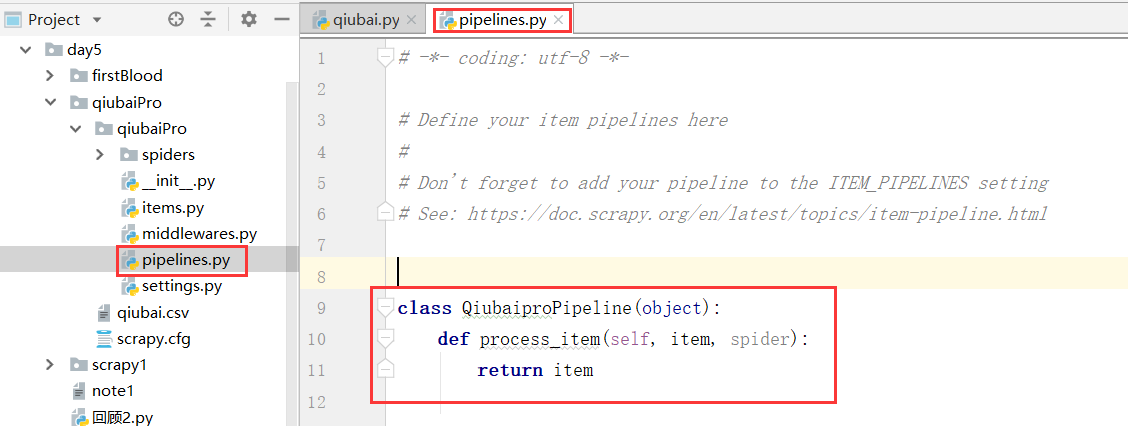
我们看到这个管道类中有一个item方法,以及item参数,只可以处理item类型的对象
#可以将item类型的对象中存储的数据进行持久化存储
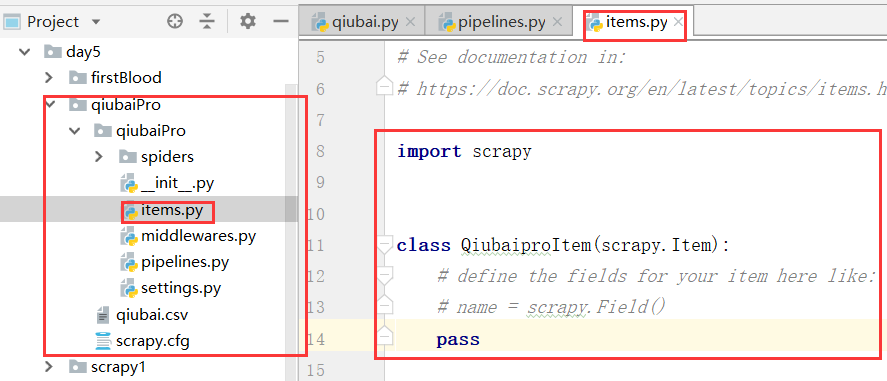
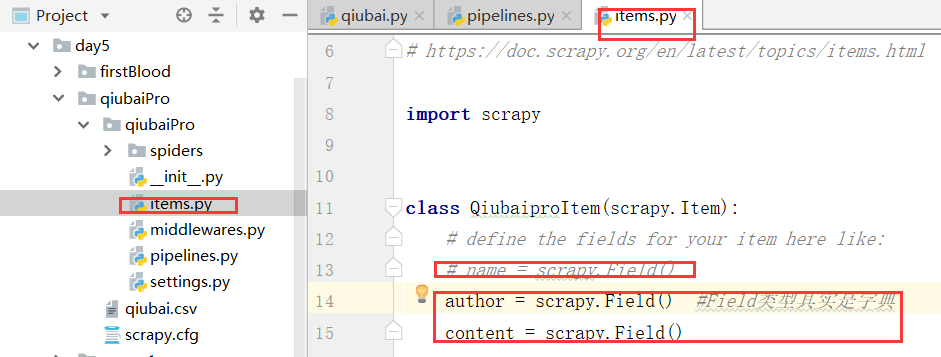
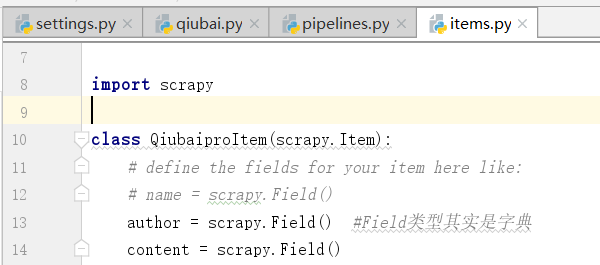
通过item类型的对象进行处理,我们通过对上边的数据写入items.py文件进行处理
下面我们进行定制,我们参考的是给定的公式
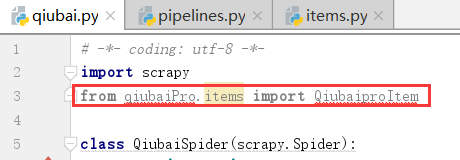
下面我们再爬虫文件中导入类,爆红是不一定代表出错,在这里可以体现
下面我们可以实例化这个item对象,
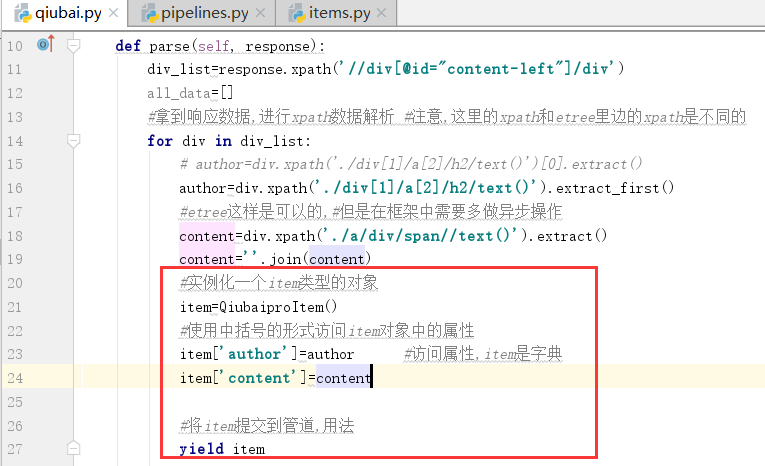
上边的for循环执行几次,在下面的process_item执行几次
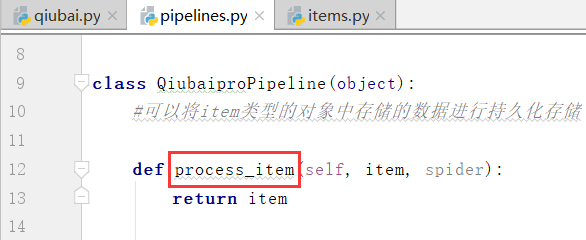
写完函数:
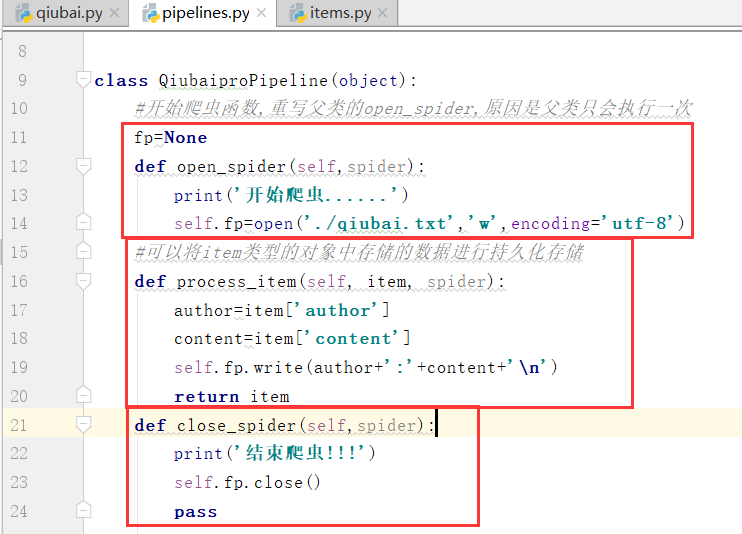
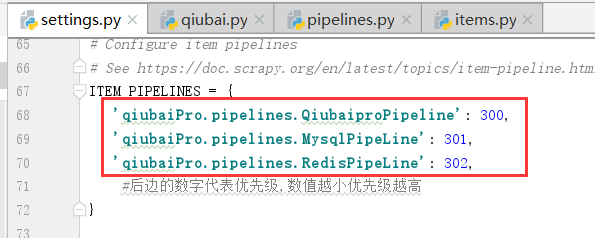
写完函数,我们需要在settings.py配置文件中开启管道.

什么时间定义多个管道类?items.py文件中的什么时间定义成字符串类型?
运行下面的命令:
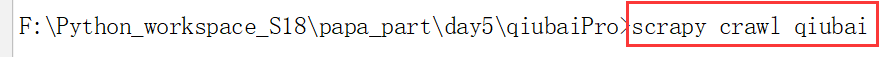
我们看到下面的开始和结束爬虫


这个时候,我们生成了一个txt持久化的文件
注意,下图为什么不用字符串类型,用json类型?Field是万能的数据类型,什么都能存储
思考,什么时间定义多个管道?
一份redis,一份本地存储,一份mysql,这个时候就需要多个管道类
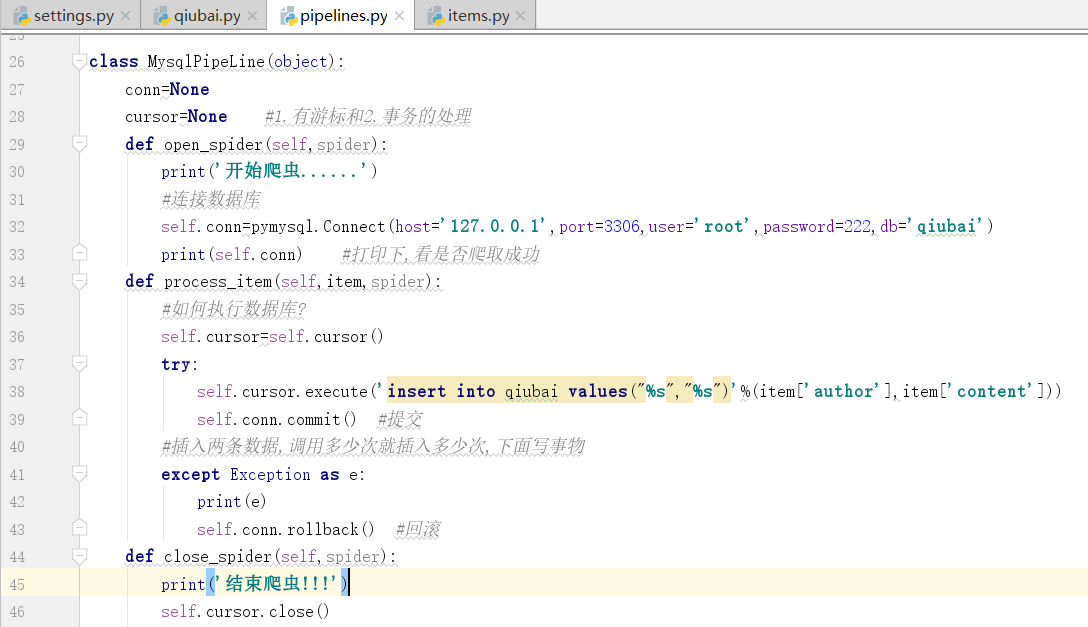
导入一个pymysql
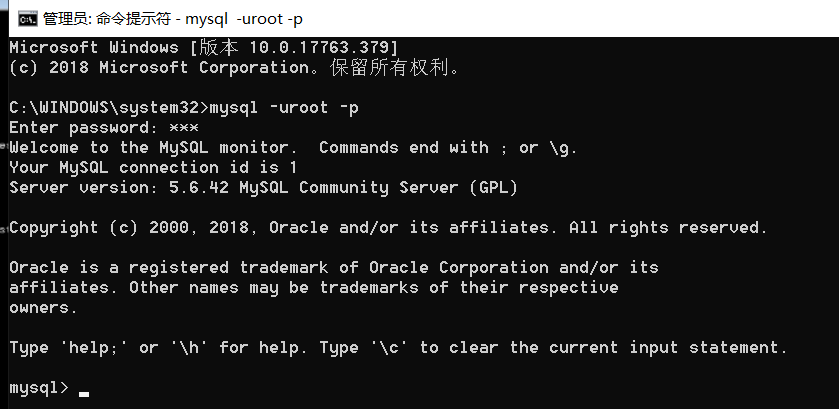
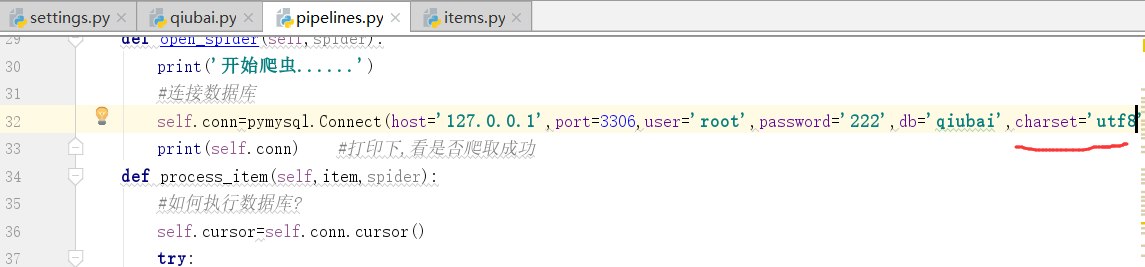
登录数据库


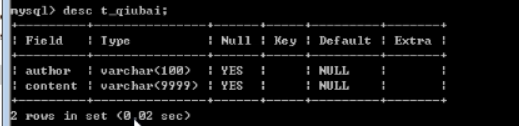

下面,我们新建一个数据库

下面创建一个表

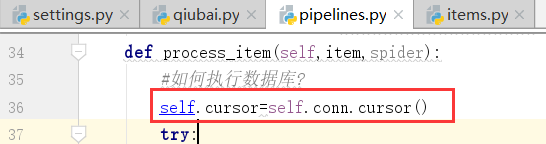
下面,我们连接数据库
在open中连接数据库
mysql端口:3306
redis端口:6379
修改下面的管道配置文件settings.py
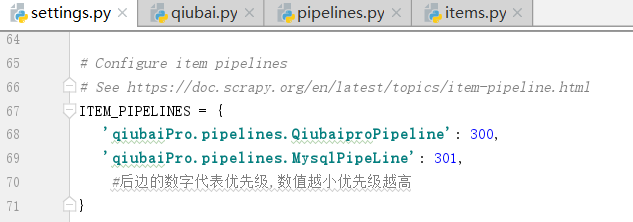
现在有两个管道类,谁先执行

我们的爬虫文件只提交了一个item,我们该如何处理?按照顺序,一定是献给了Qiubai,因为上边的这个数字Qiubai比Mysql小
当第一个类处理完item,第二个没有item了,我们该如何操作?
我们没有说哦process_item的返回值是什么?也就是这个函数有返回值,返回给的是下一个执行的管道类也就是item,症结就在这个地方
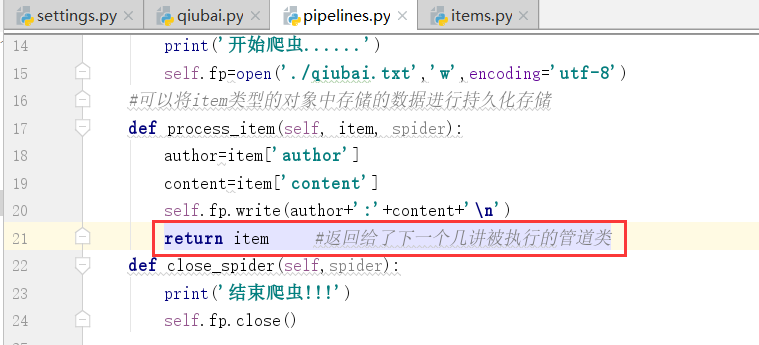
以此类推,我们加上这么一个管道类的返回值
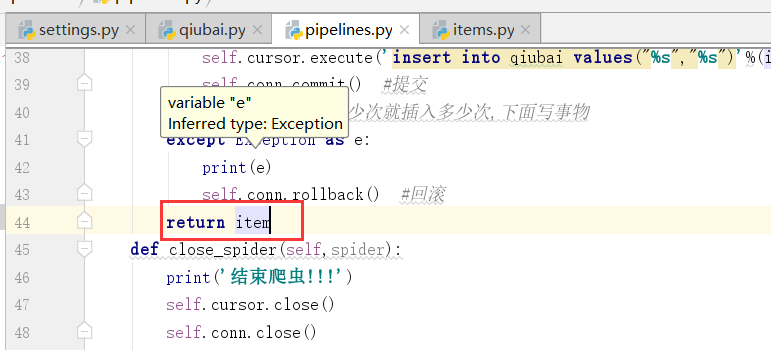
下面执行一下,看是否会有错,可能会出现数据库编码的问题
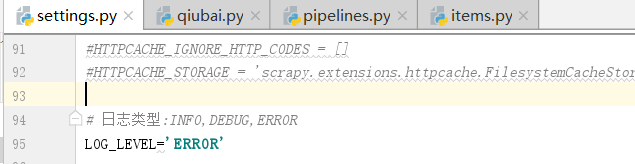
总结数据库日志类型:INFO,DEBUG,ERROR
我们可以指定日志输出的类型
运行得到下面的结果:

原因:
运行,得到下面的结果:

在执行这个过程中可能会出现编码问题,如何修改?

我们在连接的时候加上

查看上边表qiubai的信息
我们在分布式的时候会用到redis
启动redis

导入redis包
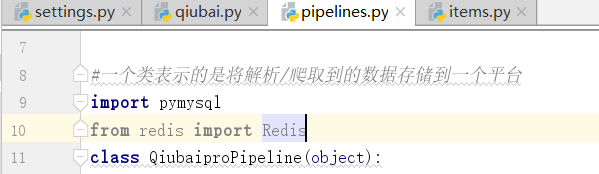
下面开始写类
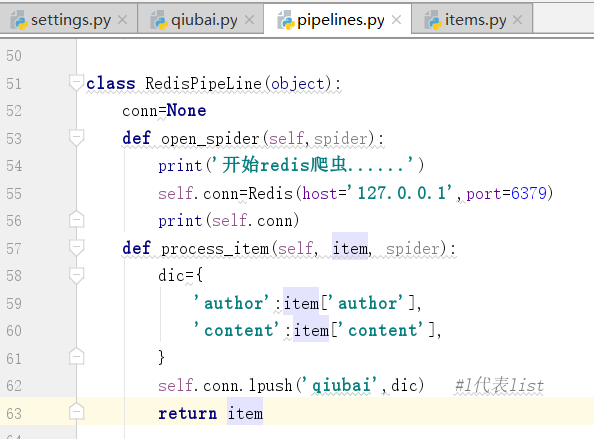
=
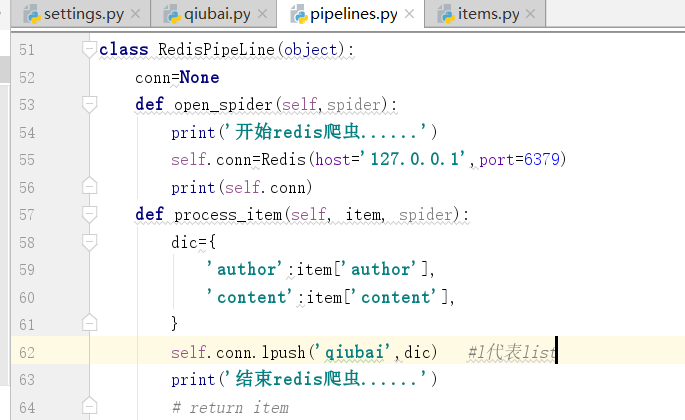
重新安装redis,换成2的版本
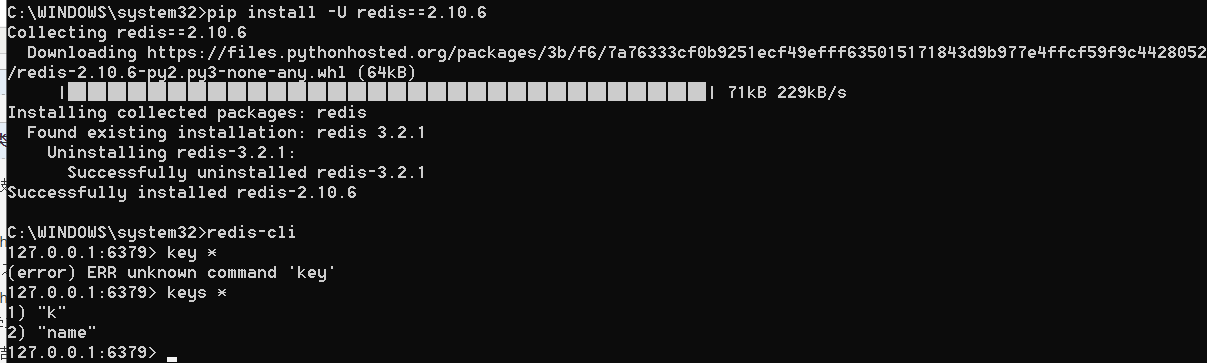
再次运行,我们可以成功执行
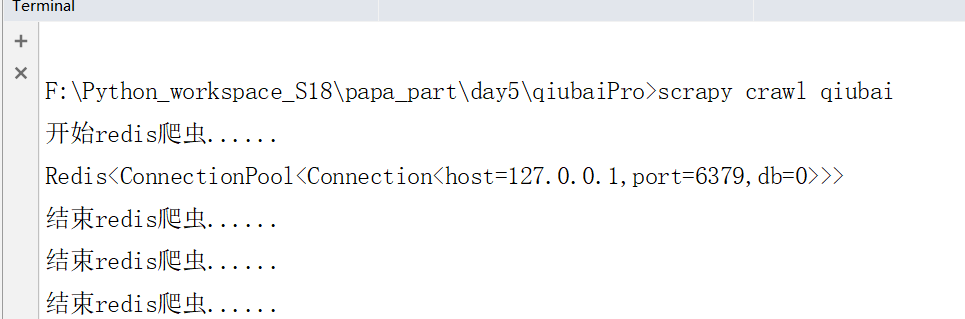
我们可以看到下面的内容qiubai
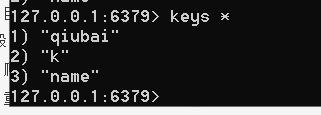
之一txt和mysql以及redis不能混合使用,容易报错
运行下面的命令,我们可以看到一串二进制数字.

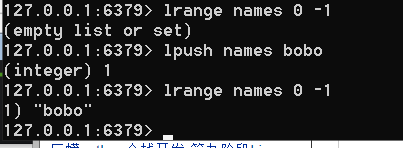
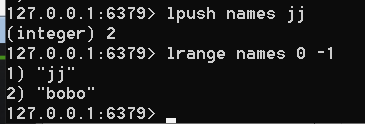
lpush names 'bobo'
添加和删除,见下图
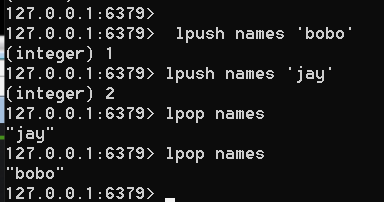
0到-1是全部取出,得到下面的内容
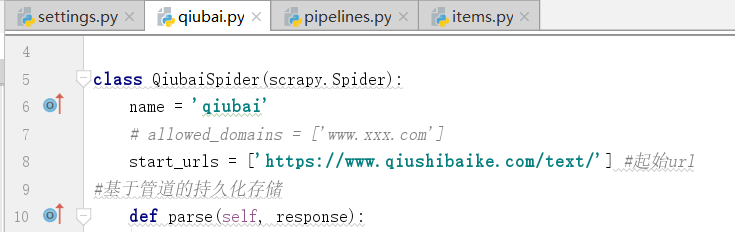
现在,我们只是发起了一个页面,我们将所有页码的url都放在start_urls列表中
如何爬取多个页码中的数据,请看下一节
小爬爬5:scrapy介绍3持久化存储的更多相关文章
- 小爬爬5:scrapy介绍2
1.scrapy:爬虫框架 -框架:集成了很多功能且具有很强通用性的一个项目模板 -如何学习框架:(重点:知道有哪些模块,会用就行) -学习框架的功能模板的具体使用. 功能:(1)异步爬取(自带buf ...
- scrapy框架的持久化存储
一 . 基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存 ...
- 小爬爬6.scrapy回顾和手动请求发送
1.数据结构回顾 #栈def push(self,item) def pop(self) #队列 def enqueue(self,item) def dequeue(self) #列表 def ad ...
- 11.scrapy框架持久化存储
今日概要 基于终端指令的持久化存储 基于管道的持久化存储 今日详情 1.基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的 ...
- scrapy框架持久化存储
基于终端指令的持久化存储 基于管道的持久化存储 1.基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文 ...
- Scrapy持久化存储
基于终端指令的持久化存储 保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作; 执行输出指定格式进行存储:将爬 ...
- Scrapy持久化存储-爬取数据转义
Scrapy持久化存储 爬虫爬取数据转义问题 使用这种格式,会自动帮我们转义 'insert into wen values(%s,%s)',(item['title'],item['content' ...
- 10 Scrapy框架持久化存储
一.基于终端指令的持久化存储 保证parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作. 执行输出指定格式进行存储:将爬取到的 ...
- scrapy之持久化存储
scrapy之持久化存储 scrapy持久化存储一般有三种,分别是基于终端指令保存到磁盘本地,存储到MySQL,以及存储到Redis. 基于终端指令的持久化存储 scrapy crawl xxoo - ...
随机推荐
- DSP日志打印 LOG_printf
LOG_printf 依托BIOS环境,需要引用下列头文件: #include <std.h> #include <log.h> 并且,要在.tcf环境中添加一个LOG ...
- 桥接模式(Bridge、Implementor)(具体不同平台日志记录,抽象与实现分离)
桥接模式(Bridge Pattern):将抽象部分与它的实现部分分离,使它们都可以独立地变化.它是一种对象结构型模式,又称为柄体(Handle and Body)模式或接口(Interface)模式 ...
- java代理概念
代理的概念 动态代理技术是整个java技术中最重要的一个技术,它是学习java框架的基础,不会动态代理技术,那么在学习Spring这些框架时是学不明白的. 动态代理技术就是用来产生一个对象的代理对象的 ...
- Windows 常用工具 & 开发工具 & Chrome插件 & Firefox 插件 & 办公软件
常用工具 1.FastStone 8.0 2.印象笔记 3.Chrome 4.Beyond Compare 5.Everything 6.有道词典 7.文本编辑软件 EditPlus UltraEdi ...
- Leetcode109. Convert Sorted List to Binary Search Tree有序链表转换二叉搜索树
给定一个单链表,其中的元素按升序排序,将其转换为高度平衡的二叉搜索树. 本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1. 示例: 给定的有序链表: [-10 ...
- Promise的源码实现(符合Promise/A+规范)
我们手写一个Promise/A+规范,然后安装测试脚本,以求通过这个规范. //Promise/A+源代码 // new Promise时,需要传递一个executor执行器,执行器立即执行 // e ...
- 其他pyton笔记
#小部分老男孩pyton课程 #所有脚本第一句话都要写解释以下脚本是用什么解释器 #!/usr/bin/env python #语言设置为:简体中文 #_*_coding:utf-8_*_ ##### ...
- WPF学习笔记-用Expression Blend制作自定义按钮
1.从Blend工具箱中添加一个Button,按住shift,将尺寸调整为125*125; 2.右键点击此按钮,选择Edit control parts(template)>Edit a cop ...
- 为啥Spring和Spring MVC包扫描要分开
开始学习springmvc各种小白问题 根据例子配置了spring扫描包,但是一直提示404错误,经过大量搜索,发现,扫描包的配置应该写在springmvc的配置文件中,而不是springmvc 配置 ...
- java-Map-system
一 概述 0--星期日1--星期一... 有对应关系,对应关系的一方是有序的数字,可以将数字作为角标. public String getWeek(int num){ if(num<0 || n ...