论文《learning to link with wikipedia》
learning to link with wikipedia
一、本文目标:
如何自动识别非结构化文本中提到的主题,并将其链接到适当的Wikipedia文章中进行解释。
二、主要借鉴论文:
Mihalcea and Csomai----Wikify!: linking documents to encyclopedic knowledge
第一步:detection(identifying the terms and phrases from which links should be made):
link probabilities:它作为锚的维基百科文章数量,除以提及它的文章数量。
第二步:disambiguation:从短语和上下文的单词中提取特征。
Medelyan et al.---- Topic Indexing with Wikipedia.
Disambiguation:
Balancing the commonness (or prior probability) of each sense and how the sense relates to its surrounding context.

三、两大步骤:link disambiguation and link detection
Link disambiguation:
Commonness and Relatedness
1.The commonness of a sense is defined by the number of times it is used as a destination in Wikipedia.
2.Our algorithm identifies these cases by comparing each possible sense with its surrounding context. This is a cyclic problem because these terms may also be ambiguous
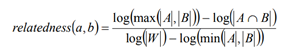
where a and b are the two articles of interest, A and B are the sets of all articles that link to a and b respectively, and W is set of all articles in Wikipedia.
Some context terms are better than others
1.单词The是明确的,因为它只用于链接到文章的语法概念,但是对于消除其他概念的歧义,它没有任何价值。
link probability 可以解决这个问题。很多文章提到the,但没有把它作为链接使用。
2. 许多上下文术语都是与文档的中心无关的. 我们可以使用Relatedness的度量方法,通过计算一个术语与所有其他上下文术语的平均语义关联,来确定该术语与这个中心线程的关系有多密切。
These two variables—link probability and relatedness—are averaged to provide a weight for each context term.
Combining the features
图中,大多关于“树”是与本文是不相关的,因为该文档显然是关于计算机科学的。如果在上下文不明确或混淆的情况下,则应选择最常用。这在大多数情况下都是正确的。
引入最后一个feature: context quality
This takes into account the number of terms involved, the extent they relate to each other, and how often they are used as Wikipedia links.
the commonness of each sense,its relatedness to the surrounding context,context quality
这三个feature来训练一个分类器。
注:这个分类器并不是为每一项选择最好的词义,而是独立考虑每一种候选,并产生它的概率。
训练阶段需要考虑的问题:参数,分类器。
参数:specifies the minimum probability of senses that are considered by the algorithm.
---- 2%
分类器:C4.5
link detection:
link detection首先收集文档中的所有n-grams,并保留那些概率超过非常低的阈值(这用于丢弃无意义的短语和停止词)。使用分类器消除所有剩余短语的歧义。

1.会有几个链接与之相关的情况。就像Democrats and Democratic Party的情况一样。
2.如果分类器发现多个可能的情况,术语可能指向多个候选。例如,民主党人可以指该党或任何民主的支持者。
Features of these articles are used to inform the classifier about which topics should and should not be linked:
Link Probability
Mihalcea and Csomai’s link probability to recognize the majority of links
引入两个feature: the average and the maximum
the average: expected to be more consistent
the maxinum: be more indicative of links
比如:Democratic Party 比 the party 有更高的链接可能性。
Relatedness
此文中,读者更可能对克林顿、奥巴马和民主党感兴趣,而不是佛罗里达州或密歇根州。
希望与文档中心线相关的主题更有可能被链接。
引入feature: the average relatedness
between each topic and all of the other candidates.
Disambiguation Confidence
使用分类器的结果作为置信度。
引入两个feature: average and maximum values
Generality
对于读者来说,为他们不知道的主题提供链接要比为那些不需要解释的主题提供链接更有用。
为一个链接定义一个generality表示它位于Wikipedia类别树中的最小深度。
通过从构成Wikipedia组织层次结构根的基本类别开始执行广度优先搜索来计算。
Location and Spread
三个feature: Frequency first occurrence last occurrence
第一次和最后一次出现的距离用于体现文档讨论主题的一致性。
训练阶段唯一要配置的变量是初始链接概率阈值,用于丢弃无意义的短语和停止单词。
--6.5%
四.WIKIFICATION IN THE WILD
Data: Xinhua News Service, the New York Times, and the Associated Press.

论文《learning to link with wikipedia》的更多相关文章
- 论文《A Generative Entity-Mention Model for Linking Entities with Knowledge Base》
A Generative Entity-Mention Model for Linking Entities with Knowledge Base 一.主要方法 提出了一种生成概率模型,叫做en ...
- Entity Framework Model First下改变数据库脚本的生成方式
在Entity Framework Model First下, 一个非常常见的需求是改变数据库脚本的生成方式.这个应用场景是指,当用户在Designer上单击鼠标右键,然后选择Generate Dat ...
- Entity Framework的核心 – EDM(Entity Data Model) 一
http://blog.csdn.net/wangyongxia921/article/details/42061695 一.EnityFramework EnityFramework的全程是ADO. ...
- EF,ADO.NET Entity Data Model简要的笔记
1. 新建一个项目,添加一个ADO.NET Entity Data Model的文件,此文件会生成所有的数据对象模型,如果是用vs2012生的话,在.Designer.cs里会出现“// Defaul ...
- Create Entity Data Model
http://www.entityframeworktutorial.net/EntityFramework5/create-dbcontext-in-entity-framework5.aspx 官 ...
- 论文分享|《Universal Language Model Fine-tuning for Text Classificatio》
https://www.sohu.com/a/233269391_395209 本周我们要分享的论文是<Universal Language Model Fine-tuning for Text ...
- Entity Framework Tutorial Basics(5):Create Entity Data Model
Create Entity Data Model: Here, we are going to create an Entity Data Model (EDM) for SchoolDB datab ...
- ASP.NET-MVC中Entity和Model之间的关系
Entity 与 Model之间的关系图 ViewModel类是MVC中与浏览器交互的,Entity是后台与数据库交互的,这两者可以在MVC中的model类中转换 MVC基础框架 来自为知笔记(Wiz ...
- How to: Use the Entity Framework Model First in XAF 如何:在 XAF 中使用EF ModelFirst
This topic demonstrates how to use the Model First entity model and a DbContext entity container in ...
- 创建实体数据模型【Create Entity Data Model】(EF基础系列5)
现在我要来为上面一节末尾给出的数据库(SchoolDB)创建实体数据模型: SchoolDB数据库的脚本我已经写好了,如下: USE master GO IF EXISTS(SELECT * FROM ...
随机推荐
- “土法炮制”之 OOM框架
一.什么是OOM框架? OOM 的全拼是 Object-Object-Map,意思是对象与对象之间的映射,OOM框架要解决的问题就是对象与对象之间数据的自动映射. 举一个具体的例子:用过MVC模式开发 ...
- 深入理解协程(四):async/await异步爬虫实战
本文目录: 同步方式爬取博客标题 async/await异步爬取博客标题 本片为深入理解协程系列文章的补充. 你将会在从本文中了解到:async/await如何运用的实际的爬虫中. 案例 从CSDN上 ...
- 定时器之Quart.net(2)
第一步:Install-Package Quartz namespace ProjectEdb { class Program { static void Main(string[] args) { ...
- springcloud复习1
1.SpringCloud是什么?SpringCloud=分布式微服务架构下的一站式解决方案,是各个微服务架构落地技术的集合体,俗称微服务全家桶. 2.SpringCloud和SpringBoot是什 ...
- python爬虫——urllib使用代理
收到粉丝私信说urllib库的教程还没写,好吧,urllib是python自带的库,没requests用着方便.本来嘛,python之禅(import this自己看)就说过,精简,效率,方便也是大家 ...
- 搞定SpringBoot多数据源(3):参数化变更源
目录 1. 引言 2. 参数化变更源说明 2.1 解决思路 2.2 流程说明 3. 实现参数化变更源 3.1 改造动态数据源 3.1.1 动态数据源添加功能 3.1.2 动态数据源配置 3.2 添加数 ...
- 【实战】使用 Kettle 工具将 mysql 数据增量导入到 MongoDB 中
最近有一个将 mysql 数据导入到 MongoDB 中的需求,打算使用 Kettle 工具实现.本文章记录了数据导入从0到1的过程,最终实现了每秒钟快速导入约 1200 条数据.一起来看吧~ 一.K ...
- 4、python基础语法
前言:本文主要介绍python的一些基础语法,包括标识符的定义.行和缩进.引号和注释.输入输出.变量的定义. 一.标识符 1.凡是我们自己取的名字,都是标识符. 2.在Python里,标识符由字母.下 ...
- 个人第4次作业—Alpha项目测试
这个作业属于哪个课程 课程链接 这个作业要求在哪里 作业要求 团队名称 CTRL_IKUN(团队博客) 这个作业的目标 对非本小组的三个项目进行软件测试 一.测试人员个人信息 学号 201731032 ...
- c#数字图像处理(十一)图像旋转
如果平面上的点绕原点逆时针旋转θº,则其坐标变换公式为: x'=xcosθ+ysinθ y=-xsinθ+ycosθ 其中,(x, y)为原图坐标,(x’, y’)为旋转后的坐标.它的逆变换公式为 ...