第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
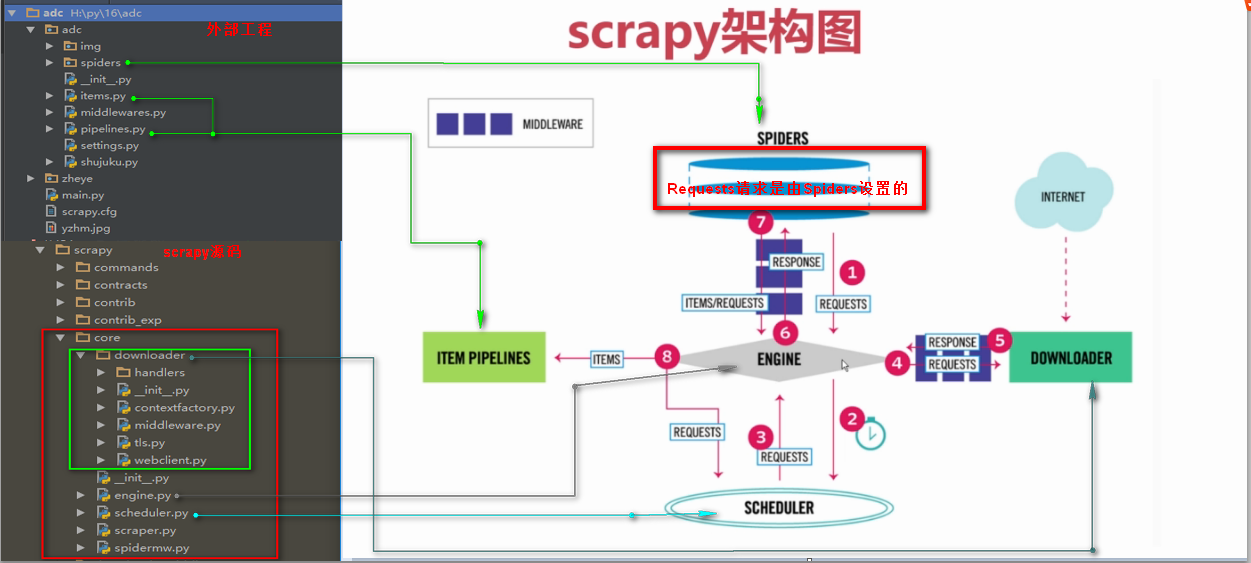
Requests请求
Requests请求就是我们在爬虫文件写的Requests()方法,也就是提交一个请求地址,Requests请求是我们自定义的
Requests()方法提交一个请求
参数:
url= 字符串类型url地址
callback= 回调函数名称
method= 字符串类型请求方式,如果GET,POST
headers= 字典类型的,浏览器用户代理
cookies= 设置cookies
meta= 字典类型键值对,向回调函数直接传一个指定值
encoding= 设置网页编码
priority= 默认为0,如果设置的越高,越优先调度
dont_filter= 默认为False,如果设置为真,会过滤掉当前url
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['www.luyin.org/'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #起始url函数,会替换start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request(
url='http://www.luyin.org/',
headers=self.header,
meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数
callback=self.parse
)] def parse(self, response):
title = response.xpath('/html/head/title/text()').extract()
print(title)
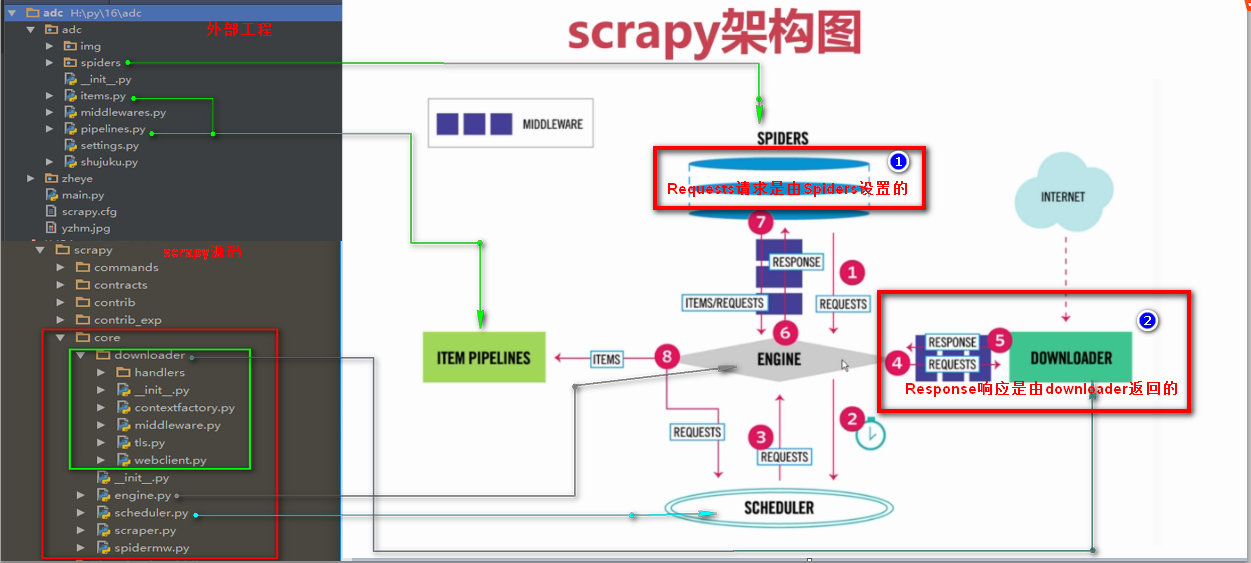
Response响应
Response响应是由downloader返回的响应

Response响应参数
headers 返回响应头
status 返回状态吗
body 返回页面内容,字节类型
url 返回抓取url
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['www.luyin.org/'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #起始url函数,会替换start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request(
url='http://www.luyin.org/',
headers=self.header,
meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数
callback=self.parse
)] def parse(self, response):
title = response.xpath('/html/head/title/text()').extract()
print(title)
print(response.headers)
print(response.status)
# print(response.body)
print(response.url)
第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍的更多相关文章
- 二十五 Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
Requests请求 Requests请求就是我们在爬虫文件写的Requests()方法,也就是提交一个请求地址,Requests请求是我们自定义的 Requests()方法提交一个请求 参数: ur ...
- 第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP 设置代理ip只需要,自定义一个中间件,重写process_request方法, request ...
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详 ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理
第三百三十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—深度优先与广度优先原理 网站树形结构 深度优先 是从左到右深度进行爬取的,以深度为准则从左到右的执行(递归方式实现)Scrapy默认 ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
随机推荐
- Fluent UDF【6】:预处理命令
今天要讲的内容是关于C语言的预处理.搞清楚了这个,就可以分析UDF中的各种头文件源代码,从此写UDF不求人. 1 关于预处理 在UDF的各种头文件中(文件路径D:\Program Files\ANSY ...
- lua -- table.nums
table.nums 计算表格包含的字段数量. 格式: count = table.nums(表格对象) Lua 的“#”操作可以取得表格的长度,但仅限从 开始连续数字为索引的表格.table.num ...
- C++11 override和final
30多年来,C++一直没有继承控制关键字.最起码这是不容易的,禁止一个类的进一步衍生是可能的但也很棘手.为避免用户在派生类中重载一个虚函数,你不得不向后考虑. C++ 11添加了两个继承控制关键字:o ...
- android开发图片分辨率
一直受到android开发图片分辨率问题困扰.drawable-(xdpi,hdpi,mdpi,ldpi,nodpi)这几个文件夹到底怎么放图片呢? dpi是什么呢? dpi是“dot per inc ...
- Mac下更改Python pip的源
步骤 ➜ ~ mkdir .pip ➜ ~ cd .pip ➜ .pip touch pip.conf ➜ .pip vi pip.conf 其中pip.conf的内容为: [global] inde ...
- 【神经网络】神经网络结构在命名实体识别(NER)中的应用
命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型,如下图.它是NLP领域中一些复杂任务(例如关系抽取,信息检索等)的 ...
- Zabbix监控JVM内存
上篇最后提到了jstat,jstat可以查看统计JVM内存信息,那么结合Zabbix,就可以监控多实例的JVM内存了. 1.下面两个脚本部署在被监控主机: vm.py 用于JVM实例PID查找,ps命 ...
- Python3求英文文档中每个单词出现的次数并排序
[本文出自天外归云的博客园] 题目要求: 1.统计英文文档中每个单词出现的次数. 2.统计结果先按次数降序排序,再按单词首字母降序排序. 3.需要考虑大文件的读取. 我的解法如下: import ch ...
- java基础篇---正则表达式
正则表达式在许多语言,例如Perl.PHP.Python.JavaScript和JScript,都支持用正则表达式处理文本,一些文本编辑器用正则表达式实现高级“搜索-替换”功能. 正则表达式是一种可以 ...
- Mysql 优化,慢查询
最近项目上遇到点问题,服务器出现连接超时.上次也是超时,问题定位到mongodb上,那次我修改好了,这次发现应该不是这个的问题了. 初步怀疑是mysql这边出问题了,写的sql没经过压力测试,导致用户 ...