三十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
elasticsearch(搜索引擎)介绍
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二最流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的。我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够一台开始并扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。Elasticsearch旨在解决所有这些问题和更多的问题。

全文搜索引擎种类
1、elasticsearch
2、solr
3、sphinx
关系数据搜素缺点,也就是直接通过数据库搜索

elasticsearch(搜索引擎)都能弥补以上缺点
elasticsearch安装
1、elasticsearch是由Java开发的,所以首先要安装Java环境
注意:elasticsearch所需要的Java环境必须大于或者等于1.8版本
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
我们下载Windows x64版本,jdk-8u144-windows-x64.exe文件,直接安装
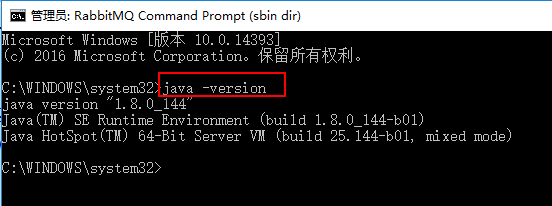
安装好后,我们cmd命令输入:java -version 查看java版本
2、elasticsearch-rtf安装
下载地址:https://github.com/medcl/elasticsearch-rtf 集成了我们很多插件
运行系统可用内存>2G
以下是集成安装的官方插件,个别插件需要配置才能使用,可根据需要删除 plugins 目录无关的插件,重启 elasticsearch 生效。
bin/elasticsearch-plugin install discovery-multicast
bin/elasticsearch-plugin install analysis-icu
bin/elasticsearch-plugin install analysis-kuromoji
bin/elasticsearch-plugin install analysis-phonetic
bin/elasticsearch-plugin install analysis-smartcn
bin/elasticsearch-plugin install analysis-stempel
bin/elasticsearch-plugin install analysis-ukrainian
bin/elasticsearch-plugin install discovery-file
bin/elasticsearch-plugin install ingest-attachment
bin/elasticsearch-plugin install ingest-geoip
bin/elasticsearch-plugin install ingest-user-agent
bin/elasticsearch-plugin install mapper-attachments
bin/elasticsearch-plugin install mapper-size
bin/elasticsearch-plugin install mapper-murmur3
bin/elasticsearch-plugin install lang-javascript
bin/elasticsearch-plugin install lang-python
bin/elasticsearch-plugin install repository-hdfs
bin/elasticsearch-plugin install repository-s3
bin/elasticsearch-plugin install repository-azure
bin/elasticsearch-plugin install repository-gcs
bin/elasticsearch-plugin install store-smb
bin/elasticsearch-plugin install discovery-ec2
bin/elasticsearch-plugin install discovery-azure-classic
bin/elasticsearch-plugin install discovery-gce
elasticsearch-rtf下载好解压后将文件夹复制到一个目录会得到以下文件

双击进入bin文件夹里,按shlft+鼠标右键,在此处打开命令窗口,输入 elasticsearch.bat 回车运行
然后在浏览器输入http://127.0.0.1:9200/ 返回数据说明成功

3、安装elasticsearch-rtf(搜索引擎)的可视化管理工具elasticsearch-head
注意:(搜索引擎)的可视化管理工具elasticsearch-head,的安装要用到node.js的npm 插件管理器
所以要先安装node.js的npm 插件管理器
下载地址:https://nodejs.org/en/download/
我们下载windows版本即可,下载后安装即可
安装后cdm命令:npm 如下显示表示安装成功

npm命令是node.js的npm 插件管理器,也就是下载插件安装插件的管理器,因为下载都是国外服务器很慢会掉线,我们需要使用淘宝的npm镜像cnpm
执行命令:npm install -g cnpm --registry=https://registry.npm.taobao.org 启用淘宝的npm镜像cnpm,注意:启用后当我们要输入npm命令时,就需要输入cnpm
(搜索引擎)的可视化管理工具elasticsearch-head的安装
下载地址:https://github.com/mobz/elasticsearch-head
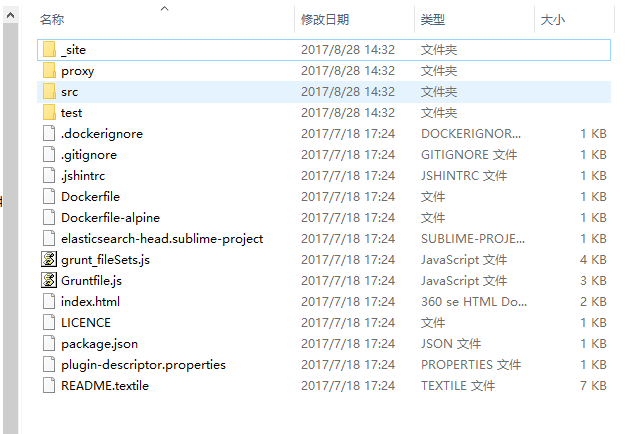
下载后解压到指定目录,会得到以下文件
cd进入到解压的elasticsearch-head目录
执行命令:cnpm install 安装elasticsearch-head的依赖包
在执行命令:cnpm run start 启动elasticsearch-head(搜索引擎)的可视化管理工具
访问后可以看到(搜索引擎)的可视化管理工具

我们看到显示未连接,我们需要配置elasticsearch-rtf(搜索引擎)连接,在elasticsearch-rtf/config/elasticsearch.yml 这个文件里配置
在文件的最后面写入
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-methods: OPTIONS, HEAD, GET, POST, PUT, DELETE
重启elasticsearch-rtf(搜索引擎)后就可以连接了

安装Kibana 5.1.2版本
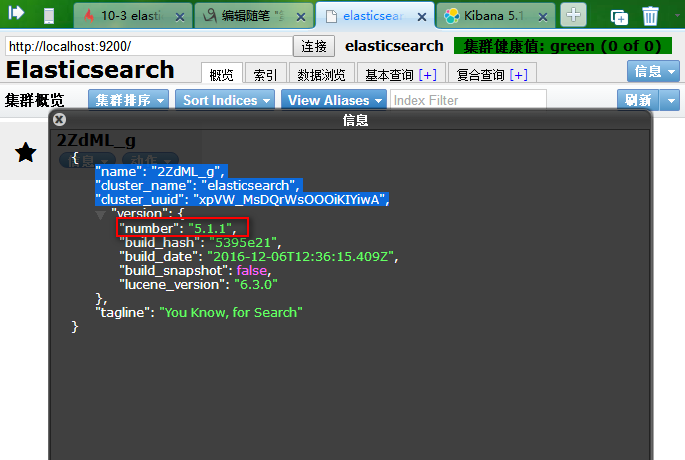
注意:Kibana的版本要对应elasticsearch-head里信息里的版本
下载地址:https://www.elastic.co/downloads/past-releases/kibana-5-1-2
我们下载windows版即可
将下载文件解压到指定目录,进入kibana-5.1.2/bin文件夹
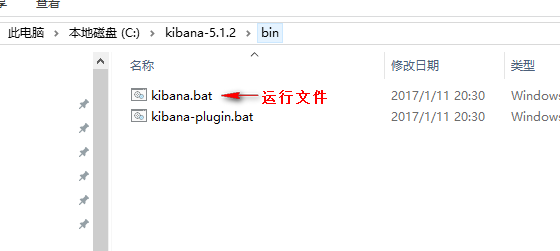
cd 进入kibana-5.1.2/bin文件夹
执行命令:kibana.bat 运行kibana-5.1.2

浏览器访问:http://localhost:5601 如下显示说明成功

三十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装的更多相关文章
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
随机推荐
- HTTP缓存实现的原理
浏览器是如何知道使用缓存的,其实这都是通过http中,浏览器将最后修改时间发送请求给web服务器,web服务器收到请求后跟服务器上的文档最后修改的时间对比,如果web服务器上最新文档修改时间小于或者等 ...
- Qt隐式共享与显式共享
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/Amnes1a/article/details/69945878Qt中的很多C++类都使用了隐式数据共 ...
- Java HashMap工作原理及实现(转载)
https://yikun.github.io/2015/04/01/Java-HashMap工作原理及实现/
- Redis与Memcached的比较(转)
原文:http://blog.nosqlfan.com/html/3729.html 这两年Redis火得可以,Redis也常常被当作Memcached的挑战者被提到桌面上来.关于Redis与Memc ...
- CSDN2015博客之星评选之拉票环节
最近接到CSDN邀请,参加了CSDN 2015博客之星 的评选活动,下面是给我拉票的链接地址: http://vote.blog.csdn.net/blogstar2015/candidate?use ...
- mysql 练习题(Day44)
init.sql文件内容 /* 数据导入: Navicat Premium Data Transfer Source Server : localhost Source Server Type : M ...
- this与super关键字总结
Ⅰ.this 用类名定义一个变量的时候,定义的应该只是一个引用,外面可以通过这个引用来访问这个类里面的属性和方法.类里面也有一个引用来访问自己的属性和方法,这个引用就是 this 对象,它可以在类里面 ...
- redis.conf配置项说明
#是否以后台进程运行,默认为no,如果需要以后台进程运行则改为yes daemonize no #如果以后台进程运行的话,就需要指定pid,你可以在此自定义redis.pid文件的位置. pidfil ...
- Storm--命令行解析
strom的命令行解析 Commands: activate classpath deactivate dev-zookeeper drpc help jar kill list localconfv ...
- Apache 工作模式配置优化
Apahce 工作模式配置 1.查看当前MPM工作模式 /usr/local/apache2/bin/apachectl -V Server version: Apache/2.4.27 (Unix) ...