lucene入门
一、lucene简介
Lucene是apache下的一个靠性能的、功能全面的用纯java开发的一个全文搜索引擎库。它几乎适合任何需要全文搜索应用程序,尤其是跨平台。lucene是开源的免费的工程。lucene使用简单但是提供的功能非常强大。相关特点如下:
- 在硬件上的速度超过150GB/小时
- 更小的内存需求,只需要1MB堆空间
- 快速地增加索引、与批量索引
- 索引的大小大于为被索引文本的20%-30%
lucene下载地址为:http://lucene.apache.org/
文本示例工程使用maven构建,lucene版本为5.2.1。相关依赖文件如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.shh</groupId>
<artifactId>lucene</artifactId>
<packaging>war</packaging>
<version>0.0.1-SNAPSHOT</version>
<name>lucene Maven Webapp</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<lucene.version>5.2.1</lucene.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency> <dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lucene.version}</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version>
</dependency> <!-- 分词器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>${lucene.version}</version>
</dependency> <dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>${lucene.version}</version>
</dependency>
</dependencies> <build>
<finalName>lucene</finalName>
</build>
</project>
二、示例
1、索引的创建
相关代码如下:
package com.test.lucene; import java.io.IOException;
import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; /**
* 创建索引
*/
public class IndexCreate { public static void main(String[] args) {
// 指定分词技术,这里使用的是标准分词
Analyzer analyzer = new StandardAnalyzer(); // indexWriter的配置信息
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer); // 索引的打开方式:没有则创建,有则打开
indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND); Directory directory = null;
IndexWriter indexWriter = null;
try {
// 索引在硬盘上的存储路径
directory = FSDirectory.open(Paths.get("D://index/test"));
//indexWriter用来创建索引文件
indexWriter = new IndexWriter(directory, indexWriterConfig);
} catch (IOException e) {
e.printStackTrace();
} //创建文档一
Document doc1 = new Document();
doc1.add(new StringField("id", "abcde", Store.YES));
doc1.add(new TextField("content", "中国广州", Store.YES));
doc1.add(new IntField("num", 1, Store.YES)); //创建文档二
Document doc2 = new Document();
doc2.add(new StringField("id", "asdff", Store.YES));
doc2.add(new TextField("content", "中国上海", Store.YES));
doc2.add(new IntField("num", 2, Store.YES)); try {
//添加需要索引的文档
indexWriter.addDocument(doc1);
indexWriter.addDocument(doc2); // 将indexWrite操作提交,如果不提交,之前的操作将不会保存到硬盘
// 但是这一步很消耗系统资源,索引执行该操作需要有一定的策略
indexWriter.commit();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭资源
try {
indexWriter.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
2、搜索
相关代码如下:
package com.test.lucene; import java.io.IOException;
import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; /**
* 搜索
*/
public class IndexSearch { public static void main(String[] args) {
//索引存放的位置
Directory directory = null;
try {
// 索引硬盘存储路径
directory = FSDirectory.open(Paths.get("D://index/test"));
// 读取索引
DirectoryReader directoryReader = DirectoryReader.open(directory);
// 创建索引检索对象
IndexSearcher searcher = new IndexSearcher(directoryReader);
// 分词技术
Analyzer analyzer = new StandardAnalyzer();
// 创建Query
QueryParser parser = new QueryParser("content", analyzer);
Query query = parser.parse("广州");// 查询content为广州的
// 检索索引,获取符合条件的前10条记录
TopDocs topDocs = searcher.search(query, 10);
if (topDocs != null) {
System.out.println("符合条件的记录为: " + topDocs.totalHits);
for (int i = 0; i < topDocs.scoreDocs.length; i++) {
Document doc = searcher.doc(topDocs.scoreDocs[i].doc);
System.out.println("id = " + doc.get("id"));
System.out.println("content = " + doc.get("content"));
System.out.println("num = " + doc.get("num"));
}
}
directory.close();
directoryReader.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
}
运行结果如下:

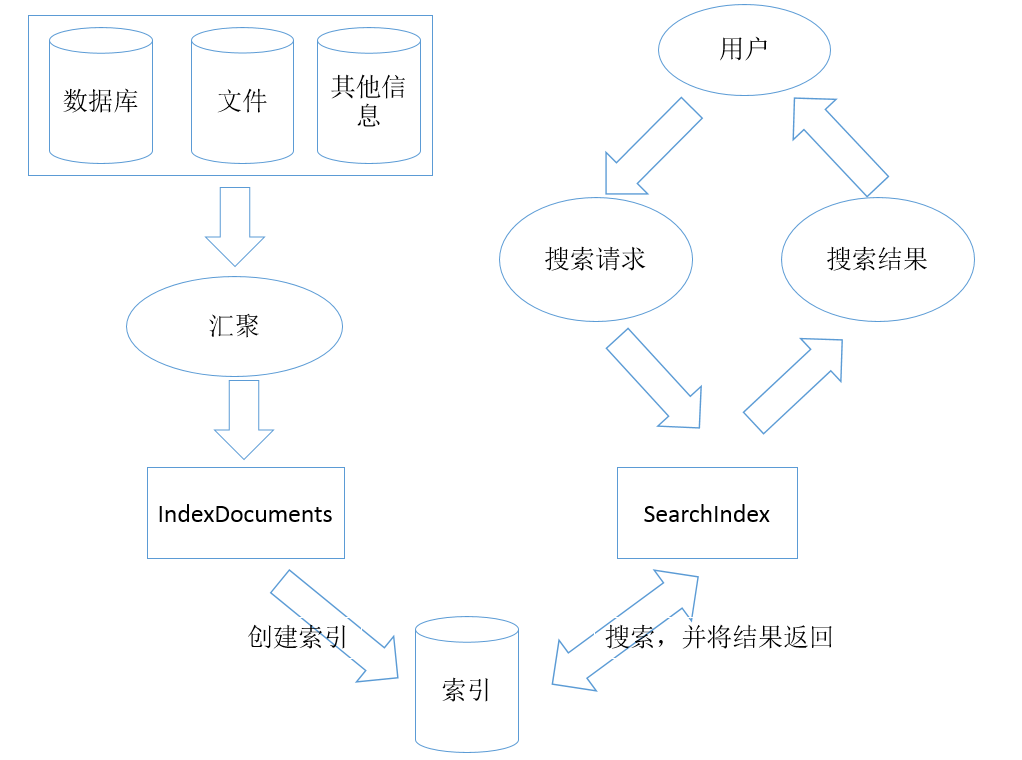
三、lucene的工作原理
lucene全文搜索分为两个步骤:
索引创建:将数据(包括数据库数据、文件等)进行信息提取,并创建索引文件。
搜索索引:根据用户的搜索请求,对创建的索引进行搜索,并将搜索的结果返回给用户。
相关示意图如下:
lucene入门的更多相关文章
- Lucene入门学习
技术原理: 开发环境: lucene包:分词包,核心包,高亮显示(highlight和memory),查询包.(下载请到官网去查看,如若下载其他版本,请看我的上篇文档,在luke里面) 原文文档: 入 ...
- Lucene 入门需要了解的东西
全文搜索引擎的原理网上大段的内容,要想深入的学习,最好的办法就是先用一下,lucene 发展比较快,下面是写第一个demo 要注意的一些事情: 1.Lucene的核心jar包,下面几个包分别位于不同 ...
- Lucene入门的基本知识(四)
刚才在写创建索引和搜索类的时候发现非常多类的概念还不是非常清楚,这里我总结了一下. 1 lucene简单介绍 1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不 ...
- Lucene入门教程
Lucene教程 1 lucene简介 1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么 ...
- Lucene入门教程(转载)
http://blog.csdn.net/tianlincao/article/details/6867127 Lucene教程 1 lucene简介 1.1 什么是lucene Lucene ...
- Lucene入门-安装和运行Demo程序
Lucene版本:7.1 一.下载安装包 https://lucene.apache.org/core/downloads.html 二.安装 把4个必备jar包和路径添加到CLASSPATH \lu ...
- Lucene入门简介
一 Lucene产生的背景 数据库中的搜索很容易实现,通常都是使用sql语句进行查询,而且能很快的得到查询结果. 为什么数据库搜索很容易? 因为数据库中的数据存储是有规律的,有行有列而且数据格式.数 ...
- Lucene入门案例一
1. 配置开发环境 官方网站:http://lucene.apache.org/ Jdk要求:1.7以上 创建索引库必须的jar包(lucene-core-4.10.3.jar,lucene-anal ...
- Java Lucene入门
1.lucene版本:7.2.1 pom文件: <?xml version="1.0" encoding="UTF-8"?> <project ...
随机推荐
- JS魔法堂:那些困扰你的DOM集合类型
一.前言 大家先看看下面的js,猜猜结果会怎样吧! 可选答案: ①. 获取id属性值为id的节点元素 ②. 抛namedItem is undefined的异常 var nodes = documen ...
- 微软必应词典客户端的案例分析——个人Week3作业
第一部分 调研,评测 Bug探索 Bug No1.高亮语义匹配错位 环境: windows8,使用必应词典版本PC版:3.5.0 重现步骤: 1. 搜索"funny face"这一 ...
- Web前端开发十日谈
=========================================================================== 原文章: http://kb.cnblogs.c ...
- LeetCode - 30. Substring with Concatenation of All Words
30. Substring with Concatenation of All Words Problem's Link --------------------------------------- ...
- 重构第30天 尽快返回 (Return ASAP)
理解:把条件语句中复杂的判断用尽快返回来简化. 详解:如首先声明的是前面讲的”分解复杂判断“,简单的来说,当你的代码中有很深的嵌套条件时,花括号就会在代码中形成一个长长的箭头.我们经常在不同的代码中看 ...
- ActiveReports 报表应用教程 (6)---分组报表
在 ActiveReports 中可以设置单级分组.嵌套分组,同时,还可以使用表格.列表以及矩阵等数据区域控件对数据源进行分组操作.分组报表在商业报表系统中应用不胜枚举,客户信息归类统计表.商品分类统 ...
- USE “schema_name” in PostgreSQL
http://timmurphy.org/tag/mysql/ http://timmurphy.org/2009/11/17/use-schema_name-in-postgresql/ ===== ...
- FreeBSD10上编译尝试DeepIn UI
经历了两百多次命令的输入尝试,终于搞定. 1 git clone https://github.com/linuxdeepin/deepin-ui.git 11 git clone https://g ...
- Gson解析的小例子
最近解析些复杂的节点数据解析,用安卓自带的json解析比较麻烦所以只能用Gson解析,所以从网上下了点demo来看看 http://blog.csdn.net/tkwxty/article/detai ...
- js 倒计时 跳转
1. setTimeout() 方法用于在指定的毫秒数后调用函数或计算表达式. setTimeout() 只执行 code 一次.如果要多次调用,请使用 setInterval() 或者让 code ...