Hive学习之路 (四)Hive的连接3种连接方式
一、CLI连接
进入到 bin 目录下,直接输入命令:
[hadoop@hadoop3 ~]$ hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/hive-common-2.3.3.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive> show databases;
OK
default
myhive
Time taken: 6.569 seconds, Fetched: 2 row(s)
hive>
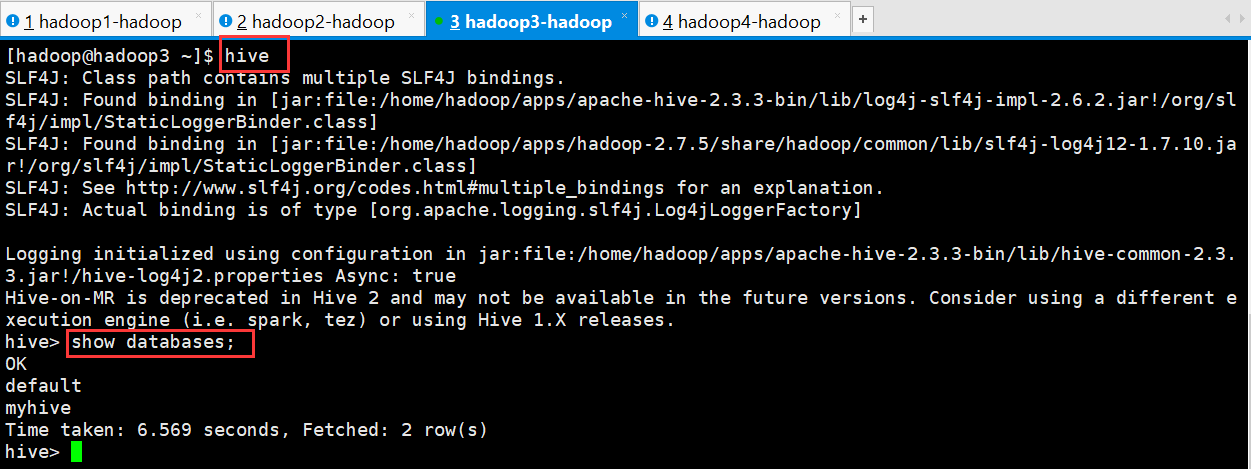
启动成功的话如上图所示,接下来便可以做 hive 相关操作
补充:
1、上面的 hive 命令相当于在启动的时候执行:hive --service cli
2、使用 hive --help,可以查看 hive 命令可以启动那些服务
3、通过 hive --service serviceName --help 可以查看某个具体命令的使用方式
二、HiveServer2/beeline
在现在使用的最新的 hive-2.3.3 版本中:都需要对 hadoop 集群做如下改变,否则无法使用
1、修改 hadoop 集群的 hdfs-site.xml 配置文件
加入一条配置信息,表示启用 webhdfs
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
2、修改 hadoop 集群的 core-site.xml 配置文件
加入两条配置信息:表示设置 hadoop 的代理用户
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
配置解析:
hadoop.proxyuser.hadoop.hosts 配置成*的意义,表示任意节点使用 hadoop 集群的代理用户 hadoop 都能访问 hdfs 集群,hadoop.proxyuser.hadoop.groups 表示代理用户的组所属
以上操作做好了之后(最好重启一下HDFS集群),请继续做如下两步:
第一步:先启动 hiveserver2 服务
启动方式,(假如是在 hadoop3 上):
启动为前台:hiveserver2
[hadoop@hadoop3 ~]$ hiveserver2
2018-04-04 10:21:49: Starting HiveServer2
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
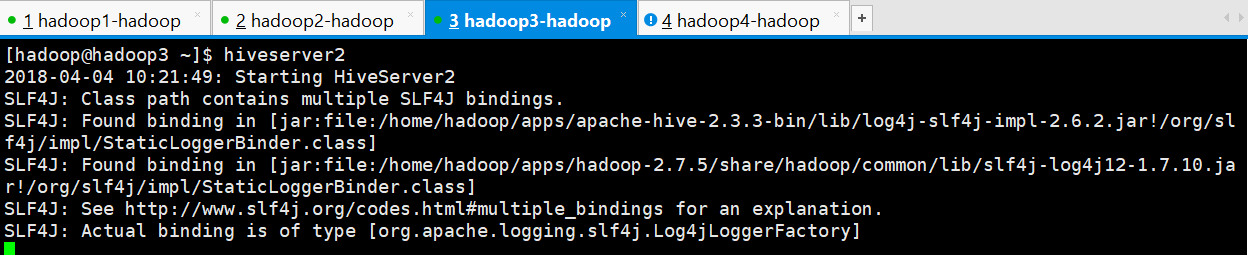
启动会多一个进程
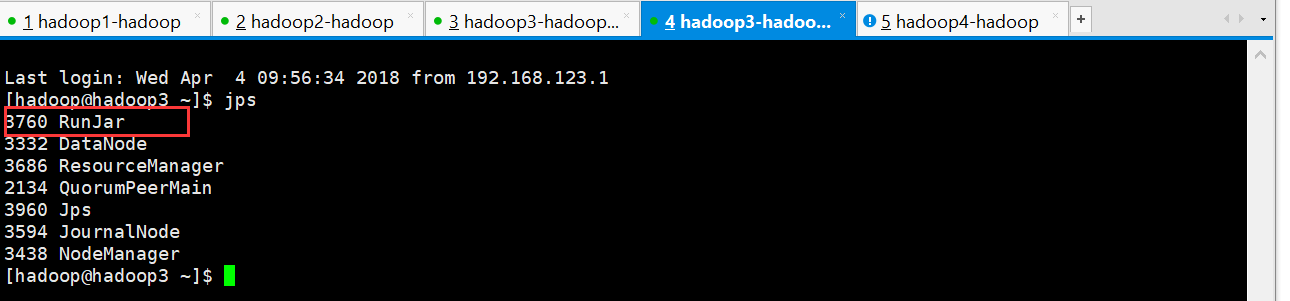
启动为后台:
nohup hiveserver2 1>/home/hadoop/hiveserver.log 2>/home/hadoop/hiveserver.err &
或者:nohup hiveserver2 1>/dev/null 2>/dev/null &
或者:nohup hiveserver2 >/dev/null 2>&1 &
以上 3 个命令是等价的,第一个表示记录日志,第二个和第三个表示不记录日志
命令中的 1 和 2 的意义分别是:
1:表示标准日志输出
2:表示错误日志输出 如果我没有配置日志的输出路径,日志会生成在当前工作目录,默认的日志名称叫做: nohup.xxx
[hadoop@hadoop3 ~]$ nohup hiveserver2 1>/home/hadoop/log/hivelog/hiveserver.log 2>/home/hadoop/log/hivelog/hiveserver.err &
[1] 4352
[hadoop@hadoop3 ~]$
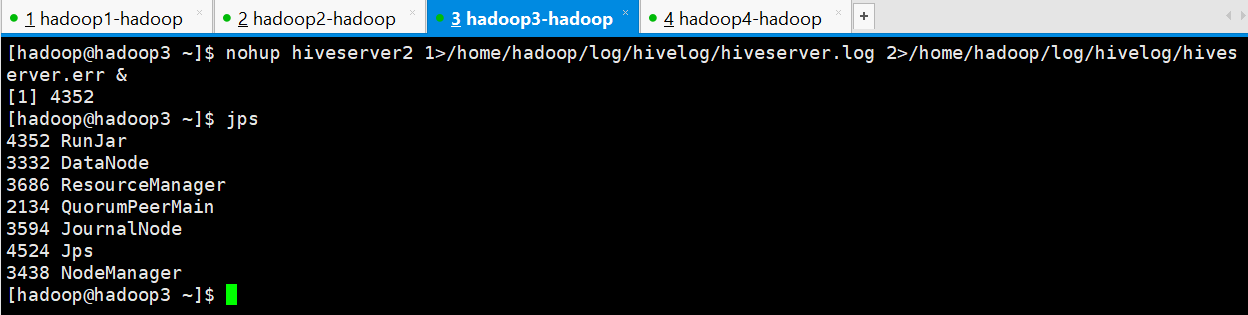
PS:nohup 命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束, 那么可以使用 nohup 命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。 nohup 就是不挂起的意思(no hang up)。 该命令的一般形式为:nohup command &
第二步:然后启动 beeline 客户端去连接:
执行命令:
[hadoop@hadoop3 ~]$ beeline -u jdbc:hive2//hadoop3:10000 -n hadoop
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
scan complete in 1ms
scan complete in 2374ms
No known driver to handle "jdbc:hive2//hadoop3:10000"
Beeline version 2.3.3 by Apache Hive
beeline>
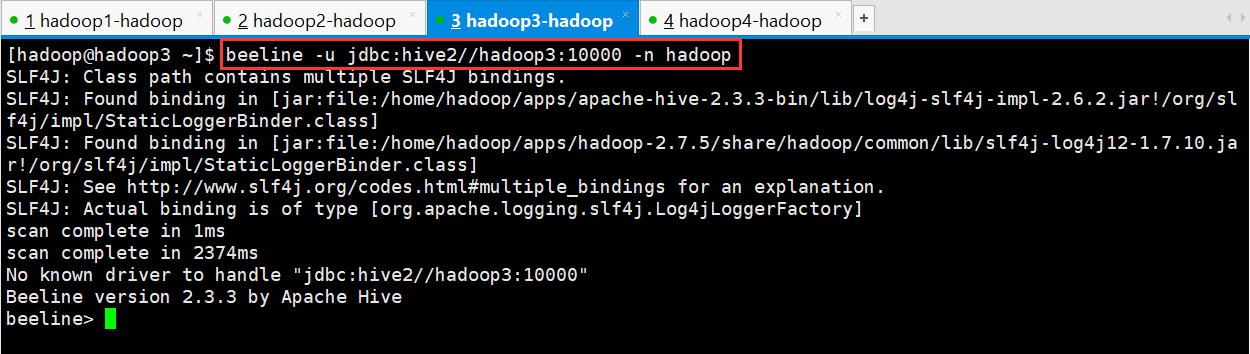
-u : 指定元数据库的链接信息
-n : 指定用户名和密码
另外还有一种方式也可以去连接:
先执行 beeline
然后按图所示输入:!connect jdbc:hive2://hadoop02:10000
按回车,然后输入用户名,这个 用户名就是安装 hadoop 集群的用户名
[hadoop@hadoop3 ~]$ beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/hadoop/apps/apache-hive-2.3.3-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop/apps/hadoop-2.7.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 2.3.3 by Apache Hive
beeline> !connect jdbc:hive2://hadoop3:10000
Connecting to jdbc:hive2://hadoop3:10000
Enter username for jdbc:hive2://hadoop3:10000: hadoop
Enter password for jdbc:hive2://hadoop3:10000: ******
Connected to: Apache Hive (version 2.3.3)
Driver: Hive JDBC (version 2.3.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://hadoop3:10000>
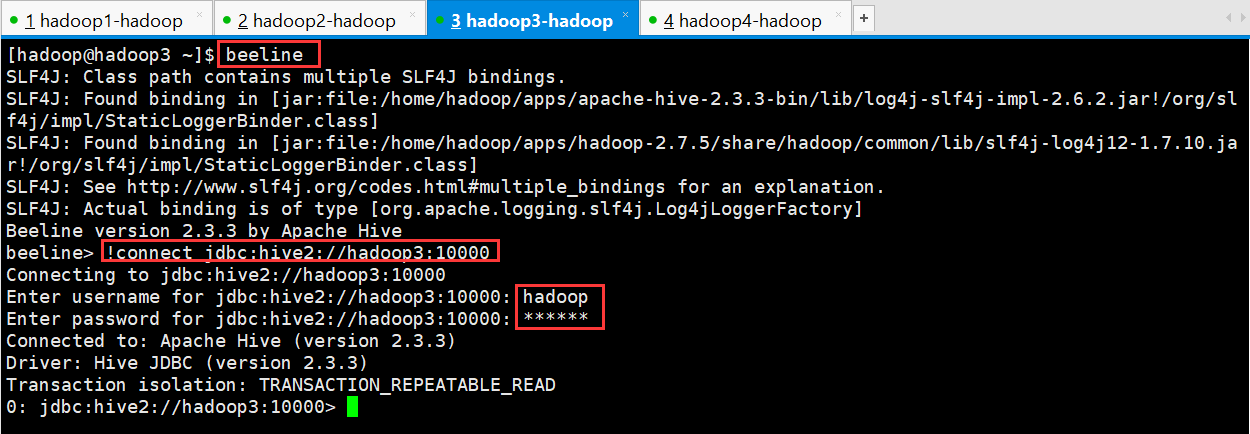
接下来便可以做 hive 操作
三、Web UI
1、 下载对应版本的 src 包:apache-hive-2.3.2-src.tar.gz
2、 上传,解压
tar -zxvf apache-hive-2.3.2-src.tar.gz
3、 然后进入目录${HIVE_SRC_HOME}/hwi/web,执行打包命令:
jar -cvf hive-hwi-2.3.2.war *
在当前目录会生成一个 hive-hwi-2.3.2.war
4、 得到 hive-hwi-2.3.2.war 文件,复制到 hive 下的 lib 目录中
cp hive-hwi-2.3.2.war ${HIVE_HOME}/lib/
5、 修改配置文件 hive-site.xml
<property>
<name>hive.hwi.listen.host</name>
<value>0.0.0.0</value>
<description>监听的地址</description>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>监听的端口号</description>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-2.3.2.war</value>
<description>war 包所在的地址</description>
</property>
6、 复制所需 jar 包
1、cp ${JAVA_HOME}/lib/tools.jar ${HIVE_HOME}/lib
2、再寻找三个 jar 包,都放入${HIVE_HOME}/lib 目录:
commons-el-1.0.jar
jasper-compiler-5.5.23.jar
jasper-runtime-5.5.23.jar
不然启动 hwi 服务的时候会报错。
7、 安装 ant
1、 上传 ant 包:apache-ant-1.9.4-bin.tar.gz
2、 解压 tar -zxvf apache-ant-1.9.4-bin.tar.gz -C ~/apps/
3、 配置环境变量 vi /etc/profile 在最后增加两行: export ANT_HOME=/home/hadoop/apps/apache-ant-1.9.4 export PATH=$PATH:$ANT_HOME/bin 配置完环境变量别忘记执行:source /etc/profile
4、 验证是否安装成功

8、上面的步骤都配置完,基本就大功告成了。进入${HIVE_HOME}/bin 目录:
${HIVE_HOME}/bin/hive --service hwi
或者让在后台运行: nohup bin/hive --service hwi > /dev/null 2> /dev/null &
9、 前面配置了端口号为 9999,所以这里直接在浏览器中输入: hadoop02:9999/hwi
10、至此大功告成

Hive学习之路 (四)Hive的连接3种连接方式的更多相关文章
- [转帖]Hive学习之路 (一)Hive初识
Hive学习之路 (一)Hive初识 https://www.cnblogs.com/qingyunzong/p/8707885.html 讨论QQ:1586558083 目录 Hive 简介 什么是 ...
- Hive学习之路 (一)Hive初识
Hive 简介 什么是Hive 1.Hive 由 Facebook 实现并开源 2.是基于 Hadoop 的一个数据仓库工具 3.可以将结构化的数据映射为一张数据库表 4.并提供 HQL(Hive S ...
- Hive学习之路 (十一)Hive的5个面试题
一.求单月访问次数和总访问次数 1.数据说明 数据字段说明 用户名,月份,访问次数 数据格式 A,, A,, B,, A,, B,, A,, A,, A,, B,, B,, A,, A,, B,, B ...
- Hive 学习之路(八)—— Hive 数据查询详解
一.数据准备 为了演示查询操作,这里需要预先创建三张表,并加载测试数据. 数据文件emp.txt和dept.txt可以从本仓库的resources目录下载. 1.1 员工表 -- 建表语句 CREAT ...
- Hive学习之路 (二十一)Hive 优化策略
一.Hadoop 框架计算特性 1.数据量大不是问题,数据倾斜是个问题 2.jobs 数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次 汇总,产生十几个 jobs,耗时很长.原 ...
- Hive学习之路 (二十)Hive 执行过程实例分析
一.Hive 执行过程概述 1.概述 (1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等 (2)操作符 Opera ...
- Hive学习之路 (十八)Hive的Shell操作
一.Hive的命令行 1.Hive支持的一些命令 Command Description quit Use quit or exit to leave the interactive shell. s ...
- Apache Hive (四)Hive的连接3种连接方式
转自:https://www.cnblogs.com/qingyunzong/p/8715925.html 一.CLI连接 进入到 bin 目录下,直接输入命令: [hadoop@hadoop3 ~] ...
- Hive 学习之路(七)—— Hive 常用DML操作
一.加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (p ...
随机推荐
- 二:Jquery-action
一:dom对象和jq对象 1.对象含义: dom对象:js方法获取元素,将dom对象存储在变量中 jq对象:jq方法获取元素的jq对象,将jq对象存储在变量中 相互之间不能使用另外一个对象的任何属性和 ...
- centos7下更新firefox
下载最新版firefox 1.点击三条线-问号-firefox帮助-安装和更新-linux安装-系统和语言下载 保存到指定目录,比如home下 2.解压 tar xjf firefox-*.tar.b ...
- STL:vector<bool> 和bitset
今天某个地方要用到很多位标记于是想着可以用下bitset,不过发现居然是编译时确定空间的,不能动态分配.那就只能用vector来代替一下了,不过发现居然有vector<bool>这个特化模 ...
- Django基础四之模板系统
一 语法 模板渲染的官方文档 关于模板渲染你只需要记两种特殊符号(语法): {{ }}和 {% %} 变量相关的用{{}},逻辑相关的用{%%}. 二 变量 在Django的模板语言中按此语法使 ...
- android studio 加载libs
eclipse 项目转 android studio libs 不能加载 导致不能导入 记录下:libs 放在和src 同路径 dependencies:增加 compile files('libs ...
- Global Average Pooling Layers for Object Localization
For image classification tasks, a common choice for convolutional neural network (CNN) architecture ...
- 搭建Kafka开发环境
Kafka版本是:kafka_2.10-0.8.2.1 1.maven工程方式 在pom.xml中配置kafka依赖 1 2 3 4 5 <dependency> <grou ...
- 使用 Azure CLI 创建 Linux 虚拟机
Azure CLI 用于从命令行或脚本创建和管理 Azure 资源. 本指南详细介绍了如何使用 Azure CLI 部署运行 Ubuntu 服务器的虚拟机. 服务器部署以后,将创建 SSH 连接,并且 ...
- 《SQL Server 2008从入门到精通》--20180704
XML查询技术 XML文档以一个纯文本的形式存在,主要用于数据存储.不但方便用户读取和使用,而且使修改和维护变得更容易. XML数据类型 XML是SQL Server中内置的数据类型,可用于SQL语句 ...
- python处理excel(一):读
功能:读取一个excel里的第2个sheet,将该sheet的内容全部输出. #coding=utf8 import xlrd def read_excel(): workbook = xlrd.op ...