DeepLearning - Regularization
I have finished the first course in the DeepLearnin.ai series. The assignment is relatively easy, but it indeed provides many interesting insight. You can find some summary notes of the first course in my previous 2 posts.
Now let's move on to the second course - Improving Deep Neural Networks: Hyper-parameter tuning, Regularization and Optimization..The second course mainly focus on some details in model tuning, including regularization, Batch, optimization, and some other techniques. Let's start with regularization.
Regularization is used to fight model over fitting. Almost all the model over fits to some extent. Because the distribution of your train and test set can't be exactly the same. Meaning your model will always learn something unique to your training set. That's why we need regularization. It tries to make your model more generalize without sacrificing too much performance- the trade off between bias (Performance) and variance (Generalization)
Any feedback is welcomed. And please correct me if I got anything wrong.
1. Parameter Regularization - L2
L2 regularization is a popular method outside NN. It is frequently used in regression, random forest and etc. With L2 regularization, the loss function of NN will be following:
\]
For layer L, above regularization term can be calculated as following:
\]
But why can adding L2 regularization help reduces over-fitting? We can get a rough idea of this from another name of it - weight Decay. Basically L2 works by pushing the weight close to 0. It is more obvious from gradient descent:
\]
\]
Further clean it up, we will get following:
\]
Compare with the original gradient, we can see after L2 regularization, parameter \(w\) will shrink by \((1- \alpha\epsilon)\) in each iteration.
So far I don't know whether you have the same confusion like me. Why would shrinking weight helps in reduce over-fitting? I found 2 ways to convince myself. Let's go with the intuition one first.
(1). Some intuition into weight decay
Andrew gives the below intuition, which is simple but very convincing. Below is Tanh function, it is frequently used as activation function in the hidden layer.
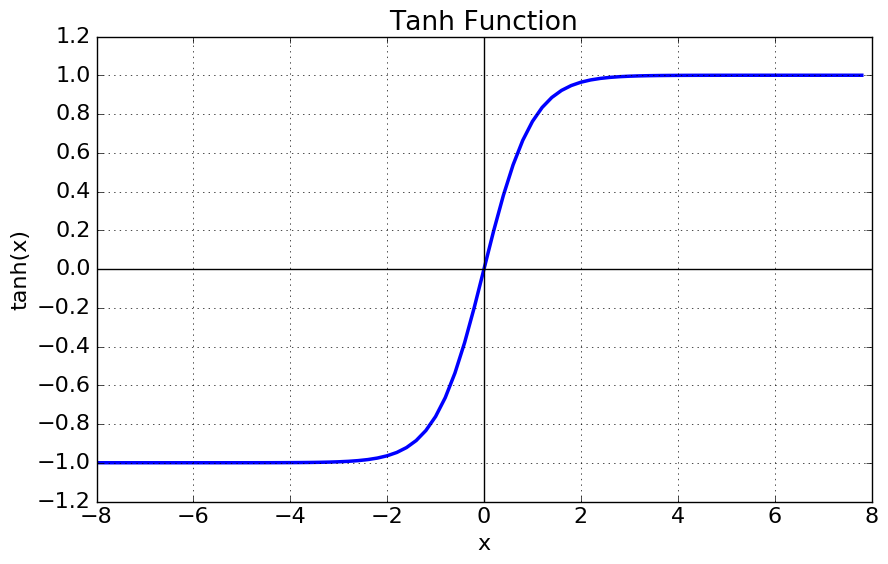
We can see when the function is around 0. it is almost linear. The non-linearity is more significant when the X gets bigger. Mean By pushing the weight close to 0, we will get a activation function with less non-linearity. Therefore weight decay can lead to a less complicated model and less over-fitting.
(2). Some math of weight decay
Of course, we can also prove the effect of **weight decay mathematically.
Let's use \(w^*\) to denote the optimal weight for original model without regularization. \(w^* = argmin_w{L(a, y)}\)
\(H\) is the Hessian matrix at \(w^*\), where \(H_{ij} = \frac{\partial^2L}{\partial{w_i}\partial{w_j}}\)
\(J\) is the Jacobian matrix at \(w^*\), where \(J_{j} = \frac{\partial{L}}{\partial{w_i}}\)
We can use Taylor rule to get the approximate form of the new loss function.
\]
Because \(w^*\) is at optimzal, so \(J=0\) and \(H\) is positive. So above can be simplified as below
\]
The new gradient \(\tilde{w}\) is following
\]
And we will get the new optimal:
\]
Because H is positive matrix, so we can decompose H into \(H = Q\Lambda{Q^T}\). where \(\Lambda\) is interpreted as the importance of weight \(w\). So above form will be following:
\]
Each weight \(w_i\) is scaled by \(\frac{\lambda_i}{\lambda_i+\alpha}\). If \(w_i\) is bigger, regularization will has less impact. Basically L2 shrinks the weight that are not important to the model.
2. Dropout
Dropout is a very simple, yet very powerful technique in regularization. It functions by randomly assigning 0 to neuron in hidden layer. It can be easily understood using following code:
import numpy as np
drop = np.random.rand(a.shape) < keep_probs ## drop out rate
a = np.multiply(drop,a ) ## randomly turned off neuron
when keep_probs gets lower, more neuron will be shut down. And here is a few ways to understand why dropout can reduce overfitting
(1). Intuition 1 - spread out weight
One way to understand dropout is that it helps spread out the weights across neurons in each hidden layer.
It is possible that the original model has higher weight on a few neurons and much lower weight on others. With dropout, the lower weighted neruon will have relatively higher weight.
Simiilar method is also used in Random Forest. In each iteraion, we randomly select a subset of columns to build the tree, so that the less importan column will have higher probably to got picked.
(2). Intuition 2 - Bagging
Bagging(Bootstrap aggregating) is used to reduce the variance of model by averaging across several models. It is very popularly used in Kaggle competition. A lot of 1st rank model is actually an average of several models.
Just like investing in portfolio is generally less risky than investing in one asset. Because the asset themselves are not entirely correlated. Therefore the variance of portfolio is smaller than the sum of the variance from each asset.
To some extent, dropout is also bagging. It randomly shuts down neurons through forward propogation, leading to a slightly different neural netwrok in each iteration (sub neural network).
The difference is in bagging, all the models are independent, while using dropout, all the sub neural networks share all the parameters. And we can view the final neural network as an aggregation of all the sub neural networks.
(3). Intuition 3 - Noise injection
Dropout also can be viewed as injecting noise into the hidden layer.
It multiplies the original hidden neuron by a randomly generated indicator (0/1). Multiplicative noise is sometimes regarded as better than additive noise. Because for additive noise, the model can easily reverse it by giving bigger weight to make the added noise less significant.
3. Early Stopping
This technique is wildly used, because it is very easy to implement and very efficient. You just need to stop training after certain threshold - a hyper parameter to train.
The best part of this method is that it doesn't change anything in the model training. And it can be easily combined with other method.
Because final goal of the model is to have better performance on the test set. So the stopping threshold is set on the validation set. Basically we should stop the model when the validation error stops decreasing after N iteration, like following:
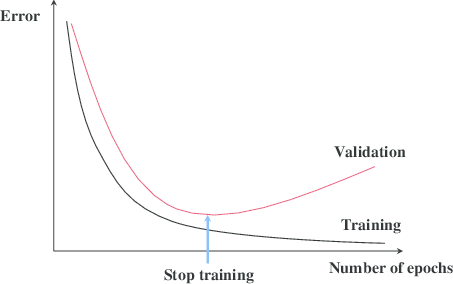
4. other methods
There are many other techniques like data augmentation, noise robustness, multi-task learning. They are mainly used at more specific area. We will go through them later.
Reference
- Ian Goodfellow, Yoshua Bengio, Aaron Conrville, "Deep Learning"
- Deeplearning.ai https://www.deeplearning.ai/
DeepLearning - Regularization的更多相关文章
- DeepLearning之路(三)MLP
DeepLearning tutorial(3)MLP多层感知机原理简介+代码详解 @author:wepon @blog:http://blog.csdn.net/u012162613/articl ...
- Coursera深度学习(DeepLearning.ai)编程题&笔记
因为是Jupyter Notebook的形式,所以不方便在博客中展示,具体可在我的github上查看. 第一章 Neural Network & DeepLearning week2 Logi ...
- 课程回顾-Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
训练.验证.测试划分的量要保证数据来自一个分布偏差方差分析如果存在high bias如果存在high variance正则化正则化减少过拟合的intuitionDropoutdropout分析其它正则 ...
- 我眼中的正则化(Regularization)
警告:本文为小白入门学习笔记 在机器学习的过程中我们常常会遇到过拟合和欠拟合的现象,就如西瓜书中一个例子: 如果训练样本是带有锯齿的树叶,过拟合会认为树叶一定要带有锯齿,否则就不是树叶.而欠拟合则认为 ...
- Coursera机器学习+deeplearning.ai+斯坦福CS231n
日志 20170410 Coursera机器学习 2017.11.28 update deeplearning 台大的机器学习课程:台湾大学林轩田和李宏毅机器学习课程 Coursera机器学习 Wee ...
- WHAT I READ FOR DEEP-LEARNING
WHAT I READ FOR DEEP-LEARNING Today, I spent some time on two new papers proposing a new way of trai ...
- Deeplearning - Overview of Convolution Neural Network
Finally pass all the Deeplearning.ai courses in March! I highly recommend it! If you already know th ...
- DeepLearning Intro - sigmoid and shallow NN
This is a series of Machine Learning summary note. I will combine the deep learning book with the de ...
- deeplearning.ai 旁听如何做课后编程作业
在上吴恩达老师的深度学习课程,在coursera上. 我觉得课程绝对值的49刀,但是确实没有额外的钱来上课.而且课程提供了旁听和助学金. 之前在coursera上算法和机器学习都是直接旁听的,这些课旁 ...
随机推荐
- AndroidUI组件之AdapterViewFilpper
package com.gc.adapterviewflipperdemo; /** * 功能:自己主动播放的图片库 * @author Android将军 */ /* * 1.AdapterView ...
- 微服务—熔断器Hystrix
前言在微服务架构中,我们将系统拆分成了一个个的服务单元,各单元应用间通过服务注册与发现的方式互相依赖. 由于每个单元都在不同的进程中运行,依赖通过远程调用的方式执行,这样就有可能因为网络原因或是依赖服 ...
- 手把手教你创建私有podspec
本文来自 网易云社区 . CocoaPods是iOS非常好用的类库管理工具,可以非常方便的管理和更新项目中使用到的第三方库,以及将自己项目中的公共组件交由它管理. 工作中比较常用到的是通过CocoaP ...
- 浅谈JS异步轮询和单线程机制
单线程特点执行异步操作 js是单线程语言,浏览器只分配给js一个主线程,用来执行任务(函数),但一次只能执行一个任务,这些任务就会排队形成一个任务队列排队等候执行.一般而已,相对耗时的操作是要通过异步 ...
- centos 7 配置nginx 的yum源
在/etc/yum.repos.d里创建nginx.repo文件: touch nginx.repo vim nginx.repo 填写如下内容后保存 [nginx] name=nginx repo ...
- sign
sign字段构成:登录类型(2Bytes) + userid(不定长,最长10Bytes,用户id或设备id) + time(10Bytes) + token(32Bytes).其中:token = ...
- 网页中的图像<img>
插入图像 img标记的属性及描述 属性 值 描述 alt text 定义有关图形的短描述 src URL 要显示图像的URL height pixels% 定义图像的高度 width pixels% ...
- 一个数据仓库时代开始--Hive
一.什么是 Apache Hive? Apache Hive 是一个基于 Hadoop Haused 构建的开源数据仓库系统,我们使用它来查询和分析存储在 Hadoop 文件中的大型数据集.此外,通过 ...
- 06.搭建kafka集群环境并测试
参考: https://www.cnblogs.com/zhangs1986/p/6565639.html https://www.cnblogs.com/frankdeng/p/9403883.ht ...
- HIVE基本语法以及HIVE分区
HIVE小结 HIVE基本语法 HIVE和Mysql十分类似 建表规则 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name da ...