实战|使用Spark Streaming写入Hudi
1. 项目背景
传统数仓的组织架构是针对离线数据的OLAP(联机事务分析)需求设计的,常用的导入数据方式为采用sqoop或spark定时作业逐批将业务库数据导入数仓。随着数据分析对实时性要求的不断提高,按小时、甚至分钟级的数据同步越来越普遍。由此展开了基于spark/flink流处理机制的(准)实时同步系统的开发。
然而实时同步数仓从一开始就面临如下几个挑战:
- 小文件问题。不论是spark的microbatch模式,还是flink的逐条处理模式,每次写入HDFS时都是几M甚至几十KB的文件。长时间下来产生的大量小文件,会对HDFS namenode产生巨大的压力。
- 对update操作的支持。HDFS系统本身不支持数据的修改,无法实现同步过程中对记录进行修改。
- 事务性。不论是追加数据还是修改数据,如何保证事务性。即数据只在流处理程序commit操作时一次性写入HDFS,当程序rollback时,已写入或部分写入的数据能随之删除。
Hudi是针对以上问题的解决方案之一。以下是对Hudi的简单介绍,主要内容翻译自官网。
2. Hudi简介
2.1 时间线(Timeline)
Hudi内部按照操作时刻(instant)对表的所有操作维护了一条时间线,由此可以提供表在某一时刻的视图,还能够高效的提取出延后到达的数据。每一个时刻包含:
- 时刻行为:对表操作的类型,包含:
commit:提交,将批次的数据原子性的写入表;
clean: 清除,后台作业,不断清除不需要的旧得版本的数据;
delta_commit:delta 提交是将批次记录原子性的写入MergeOnRead表中,数据写入的目的地是delta日志文件;
compacttion:压缩,后台作业,将不同结构的数据,例如记录更新操作的行式存储的日志文件合并到列式存储的文件中。压缩本身是一个特殊的commit操作;
rollback:回滚,一些不成功时,删除所有部分写入的文件;
savepoint:保存点,标志某些文件组为“保存的“,这样cleaner就不会删除这些文件;
- 时刻时间:操作开始的时间戳;
- 状态:时刻的当前状态,包含:
requested 某个操作被安排执行,但尚未初始化
inflight 某个操作正在执行
completed 某一个操作在时间线上已经完成
Hudi保证按照时间线执行的操作按照时刻时间具有原子性及时间线一致性。
2.2 文件管理
Hudi表存在在DFS系统的 base path(用户写入Hudi时自定义) 目录下,在该目录下被分成不同的分区。每一个分区以 partition path 作为唯一的标识,组织形式与Hive相同。
每一个分区内,文件通过唯一的 FileId 文件id 划分到 FileGroup 文件组。每一个FileGroup包含多个 FileSlice 文件切片,每一个切片包含一个由commit或compaction操作形成的base file 基础文件(parquet文件),以及包含对基础文件进行inserts/update操作的log files 日志文件(log文件)。Hudi采用了MVCC设计,compaction操作会将日志文件和对应的基础文件合并成新的文件切片,clean操作则删除无效的或老版本的文件。
2.3 索引
Hudi通过映射Hoodie键(记录键+ 分区路径)到文件id,提供了高效的upsert操作。当第一个版本的记录写入文件时,这个记录键值和文件的映射关系就不会发生任何改变。换言之,映射的文件组始终包含一组记录的所有版本。
2.4 表类型&查询
Hudi表类型定义了数据是如何被索引、分布到DFS系统,以及以上基本属性和时间线事件如何施加在这个组织上。查询类型定义了底层数据如何暴露给查询。
| 表类型 | 支持的查询类型 |
|---|---|
| Copy On Write写时复制 | 快照查询 + 增量查询 |
| Merge On Read读时合并 | 快照查询 + 增量查询 + 读取优化 |
2.4.1 表类型
Copy On Write:仅采用列式存储文件(parquet)存储文件。更新数据时,在写入的同时同步合并文件,仅仅修改文件的版次并重写。
Merge On Read:采用列式存储文件(parquet)+行式存储文件(avro)存储数据。更新数据时,新数据被写入delta文件并随后以异步或同步的方式合并成新版本的列式存储文件。
| 取舍 | CopyOnWrite | MergeOnRead |
|---|---|---|
| 数据延迟 | 高 | 低 |
| Update cost (I/O)更新操作开销(I/O) | 高(重写整个parquet) | 低(追加到delta记录) |
| Parquet文件大小 | 小(高更新(I/O)开销) | 大(低更新开销) |
| 写入频率 | 高 | 低(取决于合并策略) |
2.4.2 查询类型
- 快照查询:查询会看到以后的提交操作和合并操作的最新的表快照。对于merge on read表,会将最新的基础文件和delta文件进行合并,从而会看到近实时的数据(几分钟的延迟)。对于copy on write表,当存在更新/删除操作时或其他写操作时,会直接代替已有的parquet表。
- 增量查询:查询只会看到给定提交/合并操作之后新写入的数据。由此有效的提供了变更流,从而实现了增量数据管道。
- 读优化查询:查询会看到给定提交/合并操作之后表的最新快照。只会查看到最新的文件切片中的基础/列式存储文件,并且保证和非hudi列式存储表相同的查询效率。
| 取舍 | 快照 | 读取优化 |
|---|---|---|
| 数据延迟 | 低 | 高 |
| 查询延迟 | 高(合并基础/列式存储文件 + 行式存储delta / 日志 文件) | 低(原有的基础/列式存储文件查询性能) |
3. Spark结构化流写入Hudi
以下是整合spark结构化流+hudi的示意代码,由于Hudi OutputFormat目前只支持在spark rdd对象中调用,因此写入HDFS操作采用了spark structured streaming的forEachBatch算子。具体说明见注释。
package pers.machi.sparkhudi
import org.apache.log4j.Logger
import org.apache.spark.sql.catalyst.encoders.RowEncoder
import org.apache.spark.sql.{DataFrame, Row, SaveMode}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType}
object SparkHudi {
val logger = Logger.getLogger(SparkHudi.getClass)
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("SparkHudi")
//.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.default.parallelism", 9)
.config("spark.sql.shuffle.partitions", 9)
.enableHiveSupport()
.getOrCreate()
// 添加监听器,每一批次处理完成,将该批次的相关信息,如起始offset,抓取记录数量,处理时间打印到控制台
spark.streams.addListener(new StreamingQueryListener() {
override def onQueryStarted(queryStarted: QueryStartedEvent): Unit = {
println("Query started: " + queryStarted.id)
}
override def onQueryTerminated(queryTerminated: QueryTerminatedEvent): Unit = {
println("Query terminated: " + queryTerminated.id)
}
override def onQueryProgress(queryProgress: QueryProgressEvent): Unit = {
println("Query made progress: " + queryProgress.progress)
}
})
// 定义kafka流
val dataStreamReader = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "localhost:9092")
.option("subscribe", "testTopic")
.option("startingOffsets", "latest")
.option("maxOffsetsPerTrigger", 100000)
.option("failOnDataLoss", false)
// 加载流数据,这里因为只是测试使用,直接读取kafka消息而不做其他处理,是spark结构化流会自动生成每一套消息对应的kafka元数据,如消息所在主题,分区,消息对应offset等。
val df = dataStreamReader.load()
.selectExpr(
"topic as kafka_topic"
"CAST(partition AS STRING) kafka_partition",
"cast(timestamp as String) kafka_timestamp",
"CAST(offset AS STRING) kafka_offset",
"CAST(key AS STRING) kafka_key",
"CAST(value AS STRING) kafka_value",
"current_timestamp() current_time",
)
.selectExpr(
"kafka_topic"
"concat(kafka_partition,'-',kafka_offset) kafka_partition_offset",
"kafka_offset",
"kafka_timestamp",
"kafka_key",
"kafka_value",
"substr(current_time,1,10) partition_date")
// 创建并启动query
val query = df
.writeStream
.queryName("demo").
.foreachBatch { (batchDF: DataFrame, _: Long) => {
batchDF.persist()
println(LocalDateTime.now() + "start writing cow table")
batchDF.write.format("org.apache.hudi")
.option(TABLE_TYPE_OPT_KEY, "COPY_ON_WRITE")
.option(PRECOMBINE_FIELD_OPT_KEY, "kafka_timestamp")
// 以kafka分区和偏移量作为组合主键
.option(RECORDKEY_FIELD_OPT_KEY, "kafka_partition_offset")
// 以当前日期作为分区
.option(PARTITIONPATH_FIELD_OPT_KEY, "partition_date")
.option(TABLE_NAME, "copy_on_write_table")
.option(HIVE_STYLE_PARTITIONING_OPT_KEY, true)
.mode(SaveMode.Append)
.save("/tmp/sparkHudi/COPY_ON_WRITE")
println(LocalDateTime.now() + "start writing mor table")
batchDF.write.format("org.apache.hudi")
.option(TABLE_TYPE_OPT_KEY, "MERGE_ON_READ")
.option(TABLE_TYPE_OPT_KEY, "COPY_ON_WRITE")
.option(PRECOMBINE_FIELD_OPT_KEY, "kafka_timestamp")
.option(RECORDKEY_FIELD_OPT_KEY, "kafka_partition_offset")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partition_date")
.option(TABLE_NAME, "merge_on_read_table")
.option(HIVE_STYLE_PARTITIONING_OPT_KEY, true)
.mode(SaveMode.Append)
.save("/tmp/sparkHudi/MERGE_ON_READ")
println(LocalDateTime.now() + "finish")
batchDF.unpersist()
}
}
.option("checkpointLocation", "/tmp/sparkHudi/checkpoint/")
.start()
query.awaitTermination()
}
}
4. 测试结果
受限于测试条件,这次测试没有考虑update操作,而仅仅是测试hudi对追加新数据的性能。
数据程序一共运行5天,期间未发生报错导致程序退出。
kafka每天读取数据约1500万条,被消费的topic共有9个分区。
几点说明如下
1 是否有数据丢失及重复
由于每条记录的分区+偏移量具有唯一性,通过检查同一分区下是否有偏移量重复及不连续的情况,可以断定数据不存丢失及重复消费的情况。
2 最小可支持的单日写入数据条数
数据写入效率,对于cow及mor表,不存在更新操作时,写入速率接近。这本次测试中,spark每秒处理约170条记录。单日可处理1500万条记录。
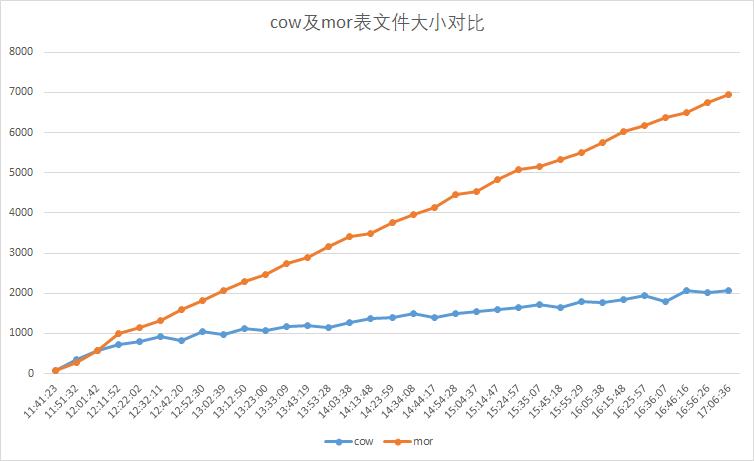
3 cow和mor表文件大小对比
每十分钟读取两种表同一分区小文件大小,单位M。结果如下图,mor表文件大小增加较大,占用磁盘资源较多。不存在更新操作时,尽可能使用cow表。
实战|使用Spark Streaming写入Hudi的更多相关文章
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十之铭文升级版
铭文一级: 第八章:Spark Streaming进阶与案例实战 updateStateByKey算子需求:统计到目前为止累积出现的单词的个数(需要保持住以前的状态) java.lang.Illega ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十七之铭文升级版
铭文一级: 功能1:今天到现在为止 实战课程 的访问量 yyyyMMdd courseid 使用数据库来进行存储我们的统计结果 Spark Streaming把统计结果写入到数据库里面 可视化前端根据 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十五之铭文升级版
铭文一级:[木有笔记] 铭文二级: 第12章 Spark Streaming项目实战 行为日志分析: 1.访问量的统计 2.网站黏性 3.推荐 Python实时产生数据 访问URL->IP信息- ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记二十一之铭文升级版
铭文一级: DataV功能说明1)点击量分省排名/运营商访问占比 Spark SQL项目实战课程: 通过IP就能解析到省份.城市.运营商 2)浏览器访问占比/操作系统占比 Hadoop项目:userA ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十八之铭文升级版
铭文一级: 功能二:功能一+从搜索引擎引流过来的 HBase表设计create 'imooc_course_search_clickcount','info'rowkey设计:也是根据我们的业务需求来 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十六之铭文升级版
铭文一级: linux crontab 网站:http://tool.lu/crontab 每一分钟执行一次的crontab表达式: */1 * * * * crontab -e */1 * * * ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十四之铭文升级版
铭文一级: 第11章 Spark Streaming整合Flume&Kafka打造通用流处理基础 streaming.conf agent1.sources=avro-sourceagent1 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十二之铭文升级版
铭文一级: ======Pull方式整合 Flume Agent的编写: flume_pull_streaming.conf simple-agent.sources = netcat-sources ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十一之铭文升级版
铭文一级: 第8章 Spark Streaming进阶与案例实战 黑名单过滤 访问日志 ==> DStream20180808,zs20180808,ls20180808,ww ==> ( ...
随机推荐
- WTM 3.5发布,VUE来了!
千呼万唤中,WTM的Vue前后端分离版本终于和大家见面了,我曾经跟群里1000多位用户保证过Vue版本会在春天到来,吹过的牛逼总算是圆上了. WTM一如既往地追求最大程度提高生产效率,所以内置的代码生 ...
- 常用正则表达式(手机号、邮箱、URL地址、身份证等等)
一.前言 不好的习惯:1.每一次用到正则都是上网copy一份,也没有去学习思考,看看都是什么意思: 2.一个项目里不同的地方用到了相同的校验,一直在重复的copy代码,并没有统一起来,万一哪天要修改规 ...
- python浅学【网络服务中间件】之MongoDB
一.关于MongoDB: MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统. 在高负载的情况下,添加更多的节点,可以保证服务器性能. MongoDB 旨在为WEB应用提供 ...
- Chrome EC框架探索_0.0_引言
0.0 引言 嵌入式硬件抽象框架常常面临着这样的尴尬:封装层次较高的(arduino,mbed)不能充分暴露必要的API并面临着性能问题,封装层次较低的(HAL,LL)接口复杂且开发困难.近日发现的一 ...
- springboot2 + mybatis 多种方式实现多数据配置
业务系统复杂程度增加,为了解决数据库I/O瓶颈,很自然会进行拆库拆表分服务来应对.这就会出现一个系统中可能会访问多处数据库,需要配置多个数据源. 第一种场景:项目服务从其它多处数据库取基础数据进行业务 ...
- java——构造器理解
构造器理解 什么是构造器 构造器也叫构造方法:用于对象的初始化: 写构造器注意事项 构造器名与类名一致:有返回值但是不能定义返回类型(返回值类型是本类,可以加一个空的return): 构造器的调用 通 ...
- 初步进入linux世界
[Linux 系统启动过程] Linux的启动其实和windows的启动过程很类似,不过windows我们是无法看到启动信息的,而linux启动时我们会看到许多启动信息,例如某个服务是否启动. Lin ...
- WePY框架 input,checkbox-group,radio-group等change 一般处理方法
布局搞定了,接下来就是数据处理方面了 form表单中常用标签,绑定change方法: 方法的具体实现 根据打印出来e的结果可以看到,e指代当前标签对象,包含属性方法等 从detail中可以获取多选框选 ...
- SpringBoot 集成多数据源
一个项目中怎么划分数据库,可以通过具体业务需求. 项目中数据源怎么如何划分,通过注解的方式@Datasource(ref="") 在方法上指定,会连接指定的数据源,这种方式比较繁琐 ...
- vscode vue 模版生成,vue 一键生成
vscode vue 模版 继上篇文章(vue 格式化),顺便记录下 vue 模版生成.图片就不在贴了,如果有找不到 vscode 插件商店的可以访问上篇文章. 一.安装 VueHelper 在 vs ...