2019基于python的网络爬虫系列,爬取糗事百科
**因为糗事百科的URL改变,正则表达式也发生了改变,导致了网上许多的代码不能使用,所以写下了这一篇博客,希望对大家有所帮助,谢谢!**
废话不多说,直接上代码。
为了方便提取数据,我用的是beautifulsoup库和requests
``## 具体代码如下
```
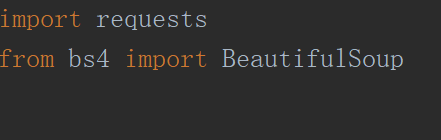
import requests
from bs4 import BeautifulSoup
def download_page(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0"}
r = requests.get(url, headers=headers)
return r.text
def get_content(html):
soup = BeautifulSoup(html, 'html.parser')
con = soup.find(id='main')
con_list = con.find_all('div', class_="cat_llb")
for i in con_list:
author = i.find('h3').string # 获取名字
content = i.find('div', id="endtext").get_text() # 获取内容
save_txt(author, content)
def save_txt(*args):
for i in args:
with open('qiubai.txt', 'a', encoding='utf-8') as f:
f.write(i+'\n'+'\n')
# def save_txt(str):
# for i in str:
#
# with open('qiubai.txt', 'a', encoding='utf-8') as f:
# f.write(str + '\n')
# f.write(i)
def main():
# 可以构造如下 url,
for i in range(1, 20):
url = 'http://www.lovehhy.net/Joke/Detail/QSBK/{}'.format(i)
html = download_page(url)
get_content(html)
if __name__ == '__main__':
main()
```
哦 ,对了,新网站的地址是http://www.lovehhy.net/Joke/Detail/QSBK/
有什么不懂得欢迎留言
2019基于python的网络爬虫系列,爬取糗事百科的更多相关文章
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
- python+正则提取+ip代理爬取糗事百科文字信息
很多网站都有反爬措施,最常见的就是封ip,请求次数过多服务器会拒绝连接,如图: 在程序中设置一个代理ip,可有效的解决这种问题,代码如下: # 需要的库 import requests import ...
- Python爬虫:爬取糗事百科
网上看到的教程,但是是用正则表达式写的,并不能运行,后面我就用xpath改了,然后重新写了逻辑,并且使用了双线程,也算是原创了吧#!/usr/bin/python# -*- encoding:utf- ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- 8.Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- [爬虫]用python的requests模块爬取糗事百科段子
虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更 ...
随机推荐
- LeetCode题:旋转链表
原题: 给定一个链表,旋转链表,将链表每个节点向右移动 k 个位置,其中 k 是非负数. 示例 1: 输入: 1->2->3->4->5->NULL, k = 2输出: ...
- Java DOM解析器 - 查询XML文档
这是需要我们查询的输入XML文件: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <?xml version="1.0"?> ...
- zabbix主动模式设置
zabbix客户端发数据给服务端分为主被动两种模式,主动模式是zabbix客户端主动向服务端发送数据,被动模式是被动等待服务端来取数据. 主动模式: 客户端每隔一段时间主动向服务端发起连接请求--&g ...
- flask中配置并使用mongodb
在你安装并运行了mongodb的情况下: 随便在一个文件中写入以下代码: import pymongo client = pymongo.MongoClient(host="localhos ...
- JQ实现仿淘宝条件筛选
首先看下效果: Js代码: <script type="text/javascript"> $(".search_qxxx > ul > li & ...
- JNI 在Android Studio利用NDK编译运行一个简单的c库
NDK开发,其实是为了项目需要调用底层的一些C/C++的一些东西:另外就是为了效率更加高些.如果你在Eclipse+ADT下开发过NDK就能体会到要么是配置NDK还要下载Cygwin,配置Cygwin ...
- 如何通过cmd命令远程重启或远程关闭Windows服务器
一.想要远程控制服务器,前提条件是远程服务器需要开启IPC$ ,且本地能访问远程服务器445端口 1.开启ipc$ net share IPC$ 2.如果只指定管理员才有执行ipc$的权限 net s ...
- C stdarg.h
参考:https://www.cnblogs.com/bettercoder/p/3488299.html 博主:运动和行动 va_start宏,获取可变参数列表的第一个参数的地址(list是类 ...
- 【LeetCode】Hash
[451] Sort Characters By Frequency [Medium] 给一个字符串,要求返回按照字母出现频率的排序后的字符串.(哈希表+桶排) 有个技巧是Hash用Value作为In ...
- shell脚本进行设置启动/关闭
vi /etc/init.d/confluence ----------------------------- #!/bin/bash# chkconfig: 2345 85 15# Provides ...