2019基于python的网络爬虫系列,爬取糗事百科
**因为糗事百科的URL改变,正则表达式也发生了改变,导致了网上许多的代码不能使用,所以写下了这一篇博客,希望对大家有所帮助,谢谢!**
废话不多说,直接上代码。
为了方便提取数据,我用的是beautifulsoup库和requests
``## 具体代码如下
```
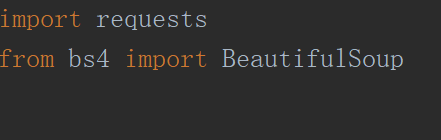
import requests
from bs4 import BeautifulSoup
def download_page(url):
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0"}
r = requests.get(url, headers=headers)
return r.text
def get_content(html):
soup = BeautifulSoup(html, 'html.parser')
con = soup.find(id='main')
con_list = con.find_all('div', class_="cat_llb")
for i in con_list:
author = i.find('h3').string # 获取名字
content = i.find('div', id="endtext").get_text() # 获取内容
save_txt(author, content)
def save_txt(*args):
for i in args:
with open('qiubai.txt', 'a', encoding='utf-8') as f:
f.write(i+'\n'+'\n')
# def save_txt(str):
# for i in str:
#
# with open('qiubai.txt', 'a', encoding='utf-8') as f:
# f.write(str + '\n')
# f.write(i)
def main():
# 可以构造如下 url,
for i in range(1, 20):
url = 'http://www.lovehhy.net/Joke/Detail/QSBK/{}'.format(i)
html = download_page(url)
get_content(html)
if __name__ == '__main__':
main()
```
哦 ,对了,新网站的地址是http://www.lovehhy.net/Joke/Detail/QSBK/
有什么不懂得欢迎留言
2019基于python的网络爬虫系列,爬取糗事百科的更多相关文章
- python网络爬虫--简单爬取糗事百科
刚开始学习python爬虫,写了一个简单python程序爬取糗事百科. 具体步骤是这样的:首先查看糗事百科的url:http://www.qiushibaike.com/8hr/page/2/?s=4 ...
- python爬虫之爬取糗事百科并将爬取内容保存至Excel中
本篇博文为使用python爬虫爬取糗事百科content并将爬取内容存入excel中保存·. 实验环境:Windows10 代码编辑工具:pycharm 使用selenium(自动化测试工具)+p ...
- python+正则提取+ip代理爬取糗事百科文字信息
很多网站都有反爬措施,最常见的就是封ip,请求次数过多服务器会拒绝连接,如图: 在程序中设置一个代理ip,可有效的解决这种问题,代码如下: # 需要的库 import requests import ...
- Python爬虫:爬取糗事百科
网上看到的教程,但是是用正则表达式写的,并不能运行,后面我就用xpath改了,然后重新写了逻辑,并且使用了双线程,也算是原创了吧#!/usr/bin/python# -*- encoding:utf- ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- 8.Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- [爬虫]用python的requests模块爬取糗事百科段子
虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Humans”,说明使用更 ...
随机推荐
- OO七大设计原则
一.单一职责原则(Single Responsibility Principle,SRP) 含义: 1.避免相同的职责分散到不同的类中 2.避免一个类承担太多职责 作用: 1.可以减少类之间的耦合 2 ...
- Java数据类型简介
Java数据类型 以下两行Java代码定义了两个整数:num1和num2: num1和num2是两个int类型的变量. int关键字指定它的后面是变量的名称,并表示数据类型整数,例如:10,15,70 ...
- Spring 使用@Async出现循环依赖Bean报错的解决方案
初现端倪 Caused by:org.springframework.beans.factory.BeanCurrentlyInCreationException: Errorcreating bea ...
- mysql 5.7.20 取得动态sql执行结果
drop procedure test; delimiter ;; CREATE procedure test() -- 取动态sql的值 begin ); ); set v_sqlcounts = ...
- python-函数-动态传参,作用域的问题,函数嵌套,global nonlocal
⼀. 函数参数--动态传参 之前我们说过了传参, 如果我们需要给⼀个函数传参, ⽽参数⼜是不确定的. 或者我给⼀个 函数传很多参数, 我的形参就要写很多, 很⿇烦, 怎么办呢. 我们可以考虑使⽤动态参 ...
- Error(10028):Can't resolve multiple constant drivers for net “ ” at **.v
两个进程里都有同一个条件判断的话,会产生并行信号冲突的问题. 同一个信号不允许在多个进程中赋值,否则则为多驱动. 进程的并行性决定了多进程不同能对同一个对象进行赋值.
- 循序渐进学.Net Core Web Api开发系列【17】:.Net core自动作业之Hangfire
nuget搜索:Hangfire 安装即可,这里我选择的是 1.7.0-beta1 版本 我是用这个集成到了 mvc api里 这里需要在 Startup 文件里进行如下配置 在配置方法 Config ...
- DQN的第一次尝试 -- 软工结对编程第一次作业
DQN的第一次尝试 在本篇博客中将为大家形象地介绍一下我对DQN的理解,以及我和我的队友如何利用DQN进行黄金点游戏.最后我会总结一下基于我在游戏中看到的结果,得到的dqn使用的注意事项和这次游戏中我 ...
- DBCP重连的问题及解决办法(转)
本文转载:http://lc87624.iteye.com/blog/1734089,欢迎大家阅读原文. 使用数据库连接池时,免不了会遇到断网.数据库挂掉等异常状况,当网络或数据库恢复时,若无法恢复连 ...
- scrollHeight与offsetHeight
offsetXxx 是 HTMLElement 的属性, HTMLElement 接口表示所有的 HTML 元素,scrollXxx 是 Element 的属性,Element 是一个通用性非常强的基 ...