python 爬取豆瓣电影评论,并进行词云展示
python 爬取豆瓣电影评论,并进行词云展示
本文旨在提供爬取豆瓣电影《我不是药神》评论和词云展示的代码样例
- 1、分析URL
- 2、爬取前10页评论
- 3、进行词云展示
1、分析URL
我不是药神 短评
第一页url
https://movie.douban.com/subject/26752088/comments?start=0&limit=20&sort=new_score&status=P
第二页url
https://movie.douban.com/subject/26752088/comments?start=20&limit=20&sort=new_score&status=P
…
…
…
第十页url
https://movie.douban.com/subject/26752088/comments?start=180&limit=20&sort=new_score&status=P
分析发现每次变化的只是…strat=后面的数字,其他内容不变,可以以此遍历每一页的评论。
2、爬取前10页评论
# -*-coding:utf-8-*-
import urllib.request
from bs4 import BeautifulSoup
def getHtml(url):
"""获取url页面"""
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
req = urllib.request.Request(url,headers=headers)
req = urllib.request.urlopen(req)
content = req.read().decode('utf-8')
return content
def getComment(url):
"""解析HTML页面"""
html = getHtml(url)
soupComment = BeautifulSoup(html, 'html.parser')
comments = soupComment.findAll('span', 'short')
onePageComments = []
for comment in comments:
# print(comment.getText()+'\n')
onePageComments.append(comment.getText()+'\n')
return onePageComments
if __name__ == '__main__':
f = open('我不是药神page10.txt', 'w', encoding='utf-8')
for page in range(10): # 豆瓣爬取多页评论需要验证。
url = 'https://movie.douban.com/subject/26752088/comments?start=' + str(20*page) + '&limit=20&sort=new_score&status=P'
print('第%s页的评论:' % (page+1))
print(url + '\n')
for i in getComment(url):
f.write(i)
print(i)
print('\n')
特别的,爬取更多评论需要模拟登陆。
3、进行词云展示
#-*-coding:utf-8-*-
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from scipy.misc import imread
import jieba
text = open("我不是药神page10.txt","rb").read()
#结巴分词
wordlist = jieba.cut(text,cut_all=True)
wl = " ".join(wordlist)
#print(wl)#输出分词之后的txt
#把分词后的txt写入文本文件
#fenciTxt = open("fenciHou.txt","w+")
#fenciTxt.writelines(wl)
#fenciTxt.close()
#设置词云
wc = WordCloud(background_color = "white", #设置背景颜色
mask = imread('shen.jpg'), #设置背景图片
max_words = 2000, #设置最大显示的字数
stopwords = ["的", "这种", "这样", "还是", "就是", "这个"], #设置停用词
font_path = "C:\Windows\Fonts\simkai.ttf", # 设置为楷体 常规
#设置中文字体,使得词云可以显示(词云默认字体是“DroidSansMono.ttf字体库”,不支持中文)
max_font_size = 60, #设置字体最大值
random_state = 30, #设置有多少种随机生成状态,即有多少种配色方案
)
myword = wc.generate(wl)#生成词云
wc.to_file('result.jpg')
#展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()词云图如下
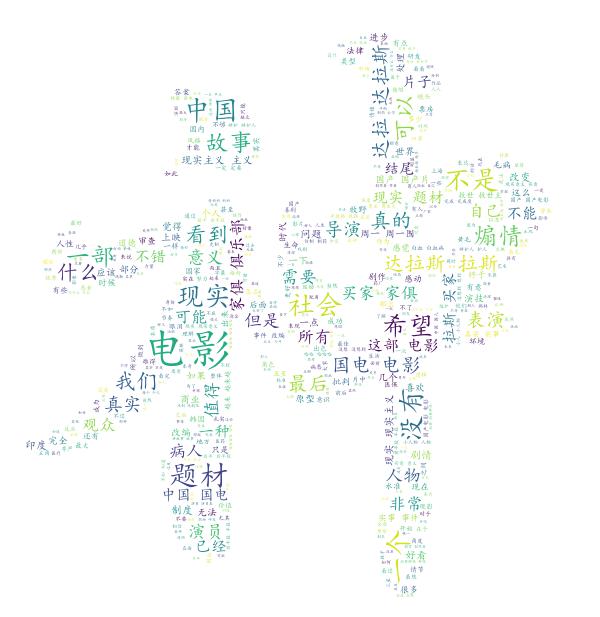
python 爬取豆瓣电影评论,并进行词云展示的更多相关文章
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
- scrapy-redis爬取豆瓣电影短评,使用词云wordcloud展示
1.数据是使用scrapy-redis爬取的,存放在redis里面,爬取的是最近大热电影<海王> 2.使用了jieba中文分词解析库 3.使用了停用词stopwords,过滤掉一些无意义的 ...
- python爬取豆瓣流浪地球影评,生成词云
代码很简单,一看就懂. (没有模拟点击,所以都是未展开的) 地址: https://movie.douban.com/subject/26266893/reviews?rating=&star ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- python爬取豆瓣电影Top250(附完整源代码)
初学爬虫,学习一下三方库的使用以及简单静态网页的分析.就跟着视频写了一个爬取豆瓣Top250排行榜的爬虫. 网页分析 我个人感觉写爬虫最重要的就是分析网页,找到网页的规律,找到自己需要内容所在的地方, ...
随机推荐
- 在 CentOS 8 上使用 FirewallD 设置防火墙
简介 一个 Linux 防火墙可用于保护您的工作站或服务器免受不需要的流量干扰.您可以设置规则来阻止或允许流量通过.CentOS 8 带有一个动态的.可定制的基于主机的防火墙和一个 D-Bus 接口. ...
- 6.第五篇 安装keepalived与Nginx
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI1MDgwNzQ1MQ==&mid=2247483796&idx=1&sn=347664de ...
- 3.配置Grafana Dashboard
本次我们通过部署 Grafana 来进行图形展示,Grafana 为我们提供了非常多的图形模板. Grafana 官网:https://grafana.com/ 1.下载安装 Grafana 我们使用 ...
- 【设计模式】Java设计模式 - 命令模式
Java设计模式 - 命令模式 生命不息,写作不止 继续踏上学习之路,学之分享笔记 总有一天我也能像各位大佬一样 一个有梦有戏的人 @怒放吧德德 分享学习心得,欢迎指正,大家一起学习成长! 目录 Ja ...
- Git、TortoiseGit中文安装教程,如何注册Gitee账号进行代码提交,上传代码后主页贡献度没显示绿点(详解)
今天给大家分享的是 Git 软件和 TortoiseGit 图形化软件的详细安装教程以及如何在 gitee 上进行代码提交. 首先我也是个刚接触 gitee 的一个小白用户,这些都是自己一边学一边记录 ...
- instanceof的使用和向下转型
x instanceof A:检验x是否为类A的对象,返回值为boolean型 使用情境:为了避免在向下转型时出现ClassCastException的异常,我们在向下转型之前,先进行instance ...
- jquery+bootstrap学习笔记
最近小颖接了个私活,客户要求用jquery和bootstrap来实现业务需求,小颖总结了下在写的过程中的一下坑,来记录一下 1.动态加载html文件 switch (_domName) { case ...
- rocky二进制安装mysql8.0
(ubuntu的有点问题) 点击查看代码 #!/bin/bash Version=`cat /etc/os-release |awk -F'"| ' '/^NAME/{print $2}'` ...
- Python处理刚刚,分钟,小时,天前等时间
简介 用爬虫获取目标网站数据后可能会遇见时间为处理刚刚,分钟,小时,天前等时间格式,如图 解决问题: 写了一个工具类来处理该问题,其中封装了两个函数 1. 将时间中的中文数字转换成阿拉伯数字 def ...
- 「浙江理工大学ACM入队200题系列」问题 F: 零基础学C/C++39——求方程的解
本题是浙江理工大学ACM入队200题第四套中的F题 我们先来看一下这题的题面. 由于是比较靠前的题目,这里插一句.各位新ACMer朋友们,请一定要养成仔细耐心看题的习惯,尤其是要利用好输入和输出样例. ...