【大数据面试】Flink 03-窗口、时间语义和水印、ProcessFunction底层API
三、窗口
1、窗口的介绍
(1)含义
将无限的流式数据切割为有限块处理,以便于聚合等操作
(2)图解
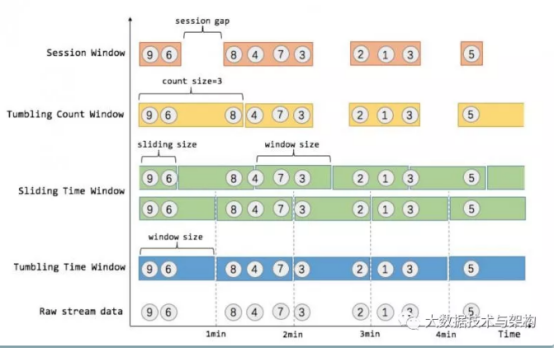
2、窗口的分类
(1)按性质分
Flink 支持三种划分窗口的方式,time、count和会话窗口(Session Windows):session间隔定义了非活跃周期的长度,一段时间没有接收到新数据就会生成新的窗口。如果根据时间划分窗口,那么它就是一个time-window(时间窗口);如果根据数据划分窗口,那么它就是一个count-window(数量窗口)。一段时间没有接收到新数据就会生成新的窗口,则为会话窗口。
(2)按类型分
窗口又可以分为滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)和会话窗口(Session Window)。
滚动窗口无重叠数据,而滑动窗口有重叠数据。
3、窗口API
窗口包含两个重要属性(size窗口大小和interval间隔-多久统计一次),如果size=interval,那么就会形成tumbling-window(无重叠数据) 如果size>interval,那么就会形成sliding-window(有重叠数据) 如果size< interval,那么窗口将会丢失数据。
例如:每5秒钟,统计过去3秒的通过路口汽车的数据,将会漏掉2秒钟的数据
组合后可以形成下列四种窗口
time-tumbling-window 无重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5))
time-sliding-window 有重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5), Time.seconds(3))
count-tumbling-window无重叠数据的数量窗口,设置方式举例:countWindow(5)
count-sliding-window 有重叠数据的数量窗口,设置方式举例:countWindow(5,3)
4、API补充
windowfunction:增量聚合(每次到来都计算)、全窗口函数(全部到来再遍历)
其它可选API:.trigger()——触发器、.evitor()——移除器、.allowedLateness()——允许处理迟到的数据、.getSideOutput() —— 获取侧输出流
四、时间语义与水印
1、时间语义分类
流式数据处理的时间可以分为事件时间,进入时间和处理时间三种
Event Time:事件的创建时间,消息本身携带
Ingestion Time:进入时间,以client客户端时间为准
Processing Time:处理时间(默认的时间属性),以服务端时间为准
通常根据日志的生成时间(Event Time)进行统计
引入时间语义:
|
val env = StreamExecutionEnvironment.getExecutionEnvironment // 从调用时刻开始给env创建的每一个stream追加时间特征 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) |
2、Watermark水印
(1)含义
Flink 为了处理 EventTime 窗口延迟计算提出的一种机制,本质是一种时间戳。每条消息都有一个事件时间和一个水印时间(计算得出,例如maxEventTime-t)。
通常与Window一起处理乱序事件。由于网络延迟等原因,不能无限期的等下去,保证特定时间后,必须触发窗口进行计算。
(2)实现原理
添加水印后,窗口会等5秒,再执行计算。若超过5秒,则舍弃。
窗口执行计算时间由水印时间来触发(而非窗口结束时间),当接收到消息的watermark >= endtime时,触发窗口的计算
(3)具体操作
实现TimestampAssigner接口,实现根据事件时间计算水印时间
五、ProcessFunctionAPI(底层API)
1、含义
是flink的底层转换算子,通过这些底层转换算子可以访问数据的时间戳、watermark以及注册定时事件等,还可以输出特定的一些事件,例如超时事件等。
2、组成
ProcessFunction
KeyedProcessFunction
CoProcessFunction
ProcessJoinFunction
BroadcastProcessFunction
KeyedBroadcastProcessFunction
ProcessWindowFunction
ProcessAllWindowFunction
3、调用方式
|
inputData.flatMap(new MySpliter()) .process(new KeyedProcessFunction<String, Sensor, String>() {}) |
所有的Process Function都实现了RichFunction接口,都有open()、close()和getRuntimeContext()等方法
4、KeyedProcessFunction
按照key对元素进行处理,额外提供下列两个方法
processElement(Sensor sensor, Context context, Collector collector), 流中的每个元素都会调用此方法,调用结果将会放在Collector数据类型中输出;context包含上下文信息,包括当前数据的时间戳、key以及时间服务,还可以将数据放到侧输出流
onTimer(long timestamp, OnTimerContext ctx, Collector out)是一个回调函数。当定时器触发时调用。timestamp是定时器的触发时间戳,ctx上下文信息,out收集输出信息
5、TimerService和定时器对象
(1)含义及组成
TimerService是Context上下文和OnTimerContext 的对象,均包含下列方法:
|
//返回当前处理时间 long currentProcessingTime(); //返回当前水位线 long currentWatermark(); //注册当前key的process time定时器,process time到达定时时间时触发timer void registerProcessingTimeTimer(long var1); //注册当前key的event time定时器,当watermark大于等于定时时间时触发timer void registerEventTimeTimer(long var1); //删除指定时间戳的process time定时器 void deleteProcessingTimeTimer(long var1); //删除指定时间戳的event time定时器 void deleteEventTimeTimer(long var1); |
(3)举例:温度传感器
传感器温度在1秒内持续升高则发出报警信息。
|
.process(new KeyedProcessFunction<String, Sensor, String>() 实现processElement()方法负责根据值注册和清除定时器 实现onTimer()方法用于发出报警【回调函数】 |
6、侧输出流(SideOutput)
(1)含义
默认算子单一输出,用侧输出流可以产生多条不同数据类型的流
每个输出流可以定义为定义为OutputTag[X]对象,并通过Context对象发射到指定事件或对象
(2)使用方式
|
val monitoredReadings: DataStream[SensorReading] = readings .process(new FreezingMonitor) monitoredReadings .getSideOutput(new OutputTag[String]("freezing-alarms")) .print() //输出指定的流信息 readings.print() //输出全部的流信息 |
(3)FreezingMonitor函数具体实现
|
class FreezingMonitor extends ProcessFunction[SensorReading, SensorReading] { // 定义一个侧输出标签 lazy val freezingAlarmOutput: OutputTag[String] = new OutputTag[String]("freezing-alarms") override def processElement(r: SensorReading, ctx: ProcessFunction[SensorReading, SensorReading]#Context, out: Collector[SensorReading]): Unit = { // 温度在32F以下时,输出警告信息 if (r.temperature < 32.0) { ctx.output(freezingAlarmOutput, s"Freezing Alarm for ${r.id}") } // 所有数据直接常规输出到主流 out.collect(r) } } |
7、CoProcessFunction
(1)含义
使用CoProcessFunction可以合并两条流,根据id将两个流中的数据组合
(2)实现
提供了操作每一个输入流的方法:processElement1()和processElement2()
第一个流ValueState<String>的值不为空,则在第二个流中合并
|
// 流2的处理逻辑与流1的处理逻辑类似 @Override public void processElement2(String value, Context ctx, Collector<Tuple2<String, String>> out) throws Exception { String value1 = state1.value(); if (value1 != null) { out.collect(Tuple2.of(value1, value)); state1.clear(); ctx.timerService().deleteEventTimeTimer(timeState.value()); timeState.clear(); } else { state2.update(value); long time = 1111L + 60000; timeState.update(time); ctx.timerService().registerEventTimeTimer(time); } } //在定时器中将value不为空的tag进行输出 |
【大数据面试】Flink 03-窗口、时间语义和水印、ProcessFunction底层API的更多相关文章
- 面试系列二:精选大数据面试真题JVM专项-附答案详细解析
公众号(五分钟学大数据)已推出大数据面试系列文章-五分钟小面试,此系列文章将会深入研究各大厂笔面试真题,并根据笔面试题扩展相关的知识点,助力大家都能够成功入职大厂! 大数据笔面试系列文章分为两种类型: ...
- LAXCUS大数据操作系统3.03版本发布,欢迎使用试用
LAXCUS大数据操作系统3.03正式发布,欢迎下载使用试用.LAXCUS大数据操作系统,集成虚拟化.大数据.数据库.容器.中间件的多集群多用户多任务全栈通用系统软件,运行.开发.维护管理为一体的平台 ...
- Hadoop大数据面试--Hadoop篇
本篇大部分内容參考网上,当中性能部分參考:http://blog.cloudera.com/blog/2009/12/7-tips-for-improving-mapreduce-performanc ...
- [java大数据面试] 2018年4月百度面试经过+三面算法题:给定一个数组,求和为定值的所有组合.
给定一个数组,求和为定值的所有组合, 这道算法题在leetcode应该算是中等偏下难度, 对三到五年工作经验主要做业务开发的同学来说, 一般较难的也就是这种程度了. 简述经过: 不算hr面,总计四面, ...
- 大数据学习(03)——HDFS的高可用
高可用架构图 先上一张搜索来的图. 如上图,HDFS的高可用其实就是NameNode的高可用. 上一篇里,SecondaryNameNode是NameNode单节点部署才会有的角色,它只帮助NameN ...
- 大数据面试(HR电话了解)
1什么是HA集群? 所谓HA,即高可用(7*24小时不中断服务) HA集群是hadoop高可用集群,即有两个namenode,一个active,一个stanby,active的name挂掉之后,sta ...
- 【大数据系列】windows环境下搭建hadoop开发环境使用api进行基本操作
前言 搭建完hadoop集群之后在windows环境下搭建java项目进行测试 操作hdfs中的文件 版本一 package com.slp.hadoop274.hdfs; import java.i ...
- 大数据时代,银行BI应用的方案探讨
大数据被誉为21世纪发展创造的新动力,BI(商业智能)成为当下最热门的数据应用方案.据资料显示:当前中国大数据IT投资最高的为五个行业中,互联网最高.其次是电信.金融.政府和医疗.而在金融行业中,银行 ...
- 大数据技术 - MapReduce的Shuffle及调优
本章内容我们学习一下 MapReduce 中的 Shuffle 过程,Shuffle 发生在 map 输出到 reduce 输入的过程,它的中文解释是 “洗牌”,顾名思义该过程涉及数据的重新分配,主要 ...
- 为什么说LAXCUS颠覆了我的大数据使用体验
切入正题前,先做个自我介绍. 本人是从业三年的大数据小码农一枚,在帝都一家有点名气的广告公司工作,同时兼着大数据管理员的职责. 平时主要的工作是配合业务部门,做各种广告大数据计算分析工作,然后制成各种 ...
随机推荐
- 使用Metricbeat监控zookeeper遇到的问题
1.metricbeat中启动自动加载模块 metricbeat.config.modules: path: ${path.config}/modules.d/*.yml reload.enabled ...
- Elasticsearch:Elasticsearch SQL介绍及实例(二)
转载自:https://blog.csdn.net/UbuntuTouch/article/details/105699014
- 第一个Django应用 - 第六部分:静态文件
前面我们编写了一个经过测试的投票应用,现在让我们给它添加一张样式表和一张背景图片. 除了由服务器生成的HTML文件外,WEB应用一般需要提供一些其它的必要文件,比如图片文件.JavaScript脚本和 ...
- centos7使用yum方式安装redis6
yum -y install epel-release wget make gcc-c++ cd /opt wget https://download.redis.io/releases/redis- ...
- 《3-D Deep Learning Approach for Remote Sensing Image Classification》论文笔记
论文题目<3-D Deep Learning Approach for Remote Sensing Image Classification> 论文作者:Amina Ben Hamida ...
- localStorage概要
在HTML5中,新加入了一个localStorage特性,这个特性主要是用来作为本地存储来使用的,解决了cookie存储空间不足的问题(cookie中每条cookie的存储空间为4k),localSt ...
- 【Java8新特性】- Stream流
Java8新特性 - Stream流的应用 生命不息,写作不止 继续踏上学习之路,学之分享笔记 总有一天我也能像各位大佬一样 一个有梦有戏的人 @怒放吧德德 分享学习心得,欢迎指正,大家一起学习成长! ...
- 手把手教你使用LabVIEW OpenCV dnn实现物体识别(Object Detection)含源码
前言 今天和大家一起分享如何使用LabVIEW调用pb模型实现物体识别,本博客中使用的智能工具包可到主页置顶博客LabVIEW AI视觉工具包(非NI Vision)下载与安装教程中下载 一.物体识别 ...
- Vue中组件化编码 完成任务的添加、删除、统计、勾选需求(实战练习三完结)
上一个章节实现数据在组件之间的传递 .这一章主要是完成添加任务到任务栏.删除任务栏.统计任务完成情况.主要还是参数在各个组件之间的传递. 上一章节的链接地址:https://blog.csdn.net ...
- LcdToos如何在线调屏PORCH参数
在点屏过程中,我们会经常碰到画面对不齐现象,在这种情况下需要多次尝试修调屏的PORCH参数来使画面显示正常:通常的做法是修改完PORCH参数下载到PG,点亮看效果,这种方法无疑效率很低,对于现象的表现 ...