kafka概述
kafka概述
Apache Kafka是一个开源 消息 系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为 Producer ,消息接受者称为 Consumer ,此外kafka集群有多个kafka实例组成,每个实例(server)称为 broker。
为什么需要消息队列
- 解耦
- 冗余
- 扩展性
- 灵活性 & 峰值处理能力
- 可恢复性
- 顺序保证
- 缓冲
- 异步通信
kafka内部实现原理

点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此
发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
Kafka架构
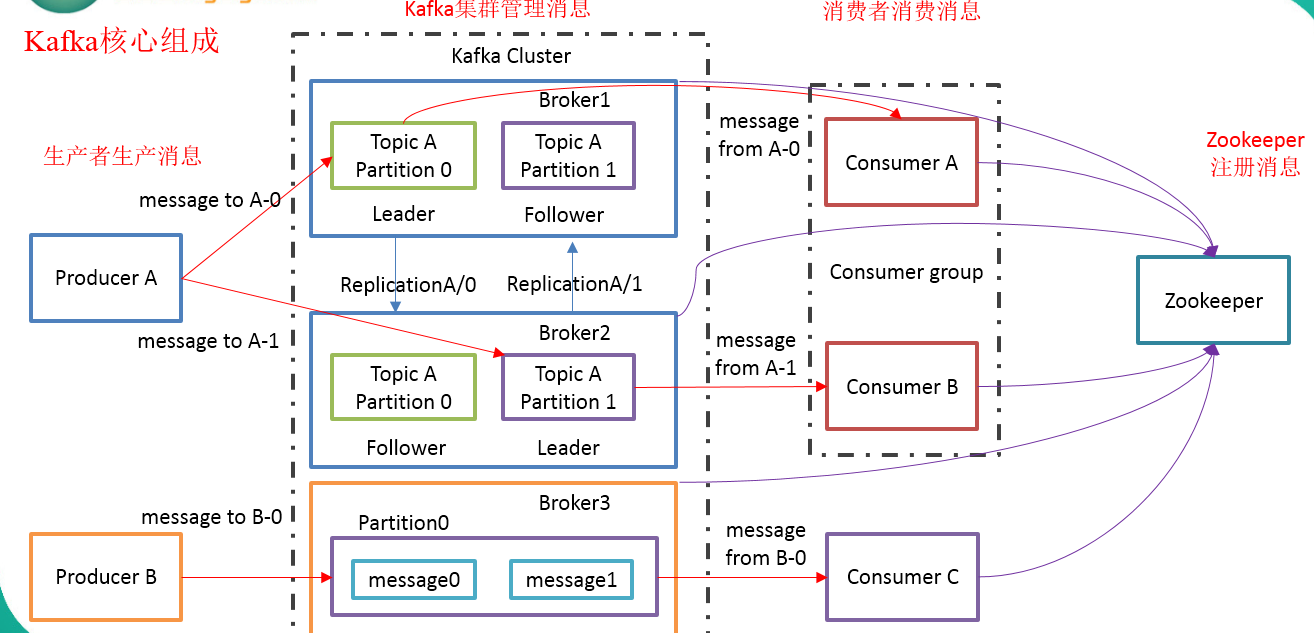
Producer :消息生产者,就是向kafka broker发消息的客户端。
Consumer :消息消费者,向kafka broker取消息的客户端
Topic :可以理解为一个队列。
Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
kafka特点
消息持久化:通过O(1)的磁盘数据结构提供数据的持久化(预读,后写,磁盘的顺序访问还快)
高吞吐量:每秒百万级的消息读写
分布式:扩展能力强
多客户端支持:java、 php、 python、 c++ ……
实时性:生产者生产的message立即被消费者可见
kafka基本组件
Broker:每一台机器叫一个Broker
Producer:日志消息生产者,用来写数据
Consumer:消息的消费者,用来读数据
Topic:不同消费者去指定的Topic中读,不同的生产者往不同的Topic中写(逻辑概念)
Partition:在Topic基础上做了进一步区分分层(物理实现,一文件夹的形式存在)
Producer
生产者可以发布数据到它指定的topic中,并可以指定在topic里哪些消息分配到哪些分区(比如简单的轮流分发各个分区或通过指定分区语义分配key到对应分区)
生产者直接把消息发送给对应分区的broker,而不需要任何路由层。
批处理发送,当message积累到一定数量或等待一定时间后进行发送
- 有两种方式:
- 同步模式:实时
- 异步模式:打到一定条件(时间、数据量)
Consumer
一种更抽象的消费方式:消费组(consumer group)
该方式包含了传统的queue和发布订阅方式
首先消费者标记自己一个消费组名。消息将投递到每个消费组中的某一个消费者实例上。
如果所有的消费者实例都有相同的消费组,这样就像传统的queue方式。
如果所有的消费者实例都有不同的消费组,这样就像传统的发布订阅方式。
消费组就好比是个逻辑的订阅者,每个订阅者由许多消费者实例构成(用于扩展或容错)。
- 如图:

相对于传统的消息系统,kafka拥有更强壮的顺序保证。
由于topic采用了分区,可在多Consumer进程操作时保证顺序性和负载均衡。
Topic
一个Topic是一个用于发布消息的分类或feed名,kafka集群使用分区的日志,每个分区都是有顺序且不变的消息序列
commit的log可以不断追加,消息在每个分区中都分配一个叫offset的id序列来唯一识别分区中的消息
如图:
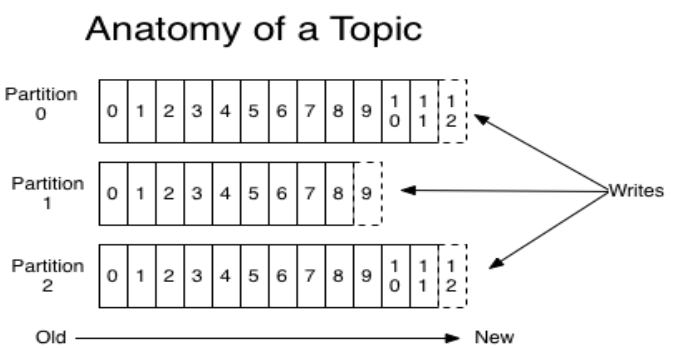
无论发布的消息是否被消费,kafka都会持久化一定时间(可配置)
在每个消费者都持久化这个offset在日志中。通常消费者读消息时会使offset值线性的增长,但实际上其位置是由消费者控制,它可以按任意顺序来消费消息。比如复位到老的offset来重新处理
每个分区代表一个并行单元
各组件之间的关系
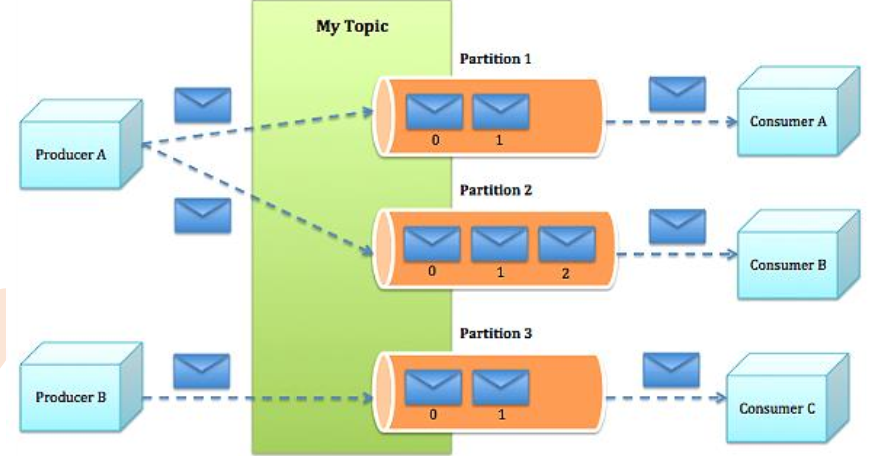
Kafka内部是分布式的、一个Kafka集群通常包括多个Broker
负载均衡:将Topic分成多个分区,每个Broker存储一个或多个Partition(hash)
多个Producer和Consumer同时生产和消费消息
Producer和Broker之间:push模式;Consumer和Broker之间:pull模式;
当一个consumer在读取一个partition时,其他的consumer不允许同时对同一个partition读取数据
kafka依赖zookeeper
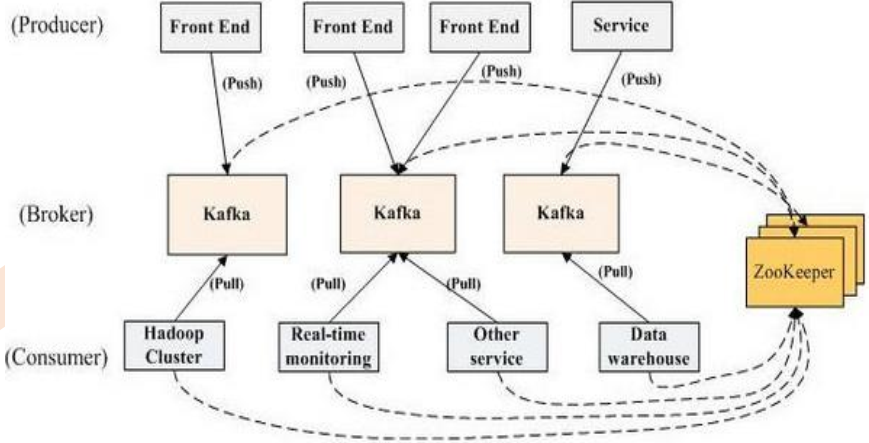
- kafka中只有Broker组件和Consumer组件与zk建立关系,因为Producer在做消息生产时可以自主制定往哪个Broker中写的
kafka消息基本单位:messag
message(消息)是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。如果consumer订阅了这个主题,那么新发布的消息就会广播给这些consumer。
message format:
– message length : 4 bytes (value: 1+4+n)
– "magic" value : 1 byte
– crc : 4 bytes
– payload : n bytes单条消息最大不超过(1M),通过配置(message.max.bytes=1000000B), broker可复制消息的最大字节数--replica.fetch.max.bytes(默认1M),
kafka概述的更多相关文章
- Kafka概述及安装部署
一.Kafka概述 1.Kafka是一个分布式流媒体平台,它有三个关键功能: (1)发布和订阅记录流,类似于消息队列或企业消息传递系统: (2)以容错的持久方式存储记录流: (3)记录发送时处理流. ...
- kafka学习汇总系列(一)kafka概述
一.kafka概述 在流式计算中,kafka是用来缓存数据的,storm通过消费kafka的数据进行计算.kafka的初心是,为处理实时数据提供一个统一.高通量.低等待的平台: 1.kafka是一个分 ...
- Kafka概述与设计原理
kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性: 1. 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能. 2 .高吞吐量:即使是 ...
- Kafka概述(一)
一.消息队列 客户端A给客户端B发送数据,若是直接发的话,客户端A给客户端B需要同步. 例如, 1) A在给B发送数据的时候,B挂掉了,此时的A是没有办法给B发送数据的: 2) A发送10M/s, ...
- Apache Kafka 概述
kafka教程,完全参照w3school: https://www.w3cschool.cn/apache_kafka/apache_kafka-dac11yot.html 以下是入门学习过程中摘录的 ...
- kafka概述与下一代消息队列
常用的消息中间件 消息中间件是当前处理大数据的一个非常重要的组件,用来解决应用解耦.异步通信.流量控制等问题,从而构建一个高效.灵活.消息同步和异步传输处理.存储转发.可伸缩和最终一致性的稳定系统.目 ...
- 1、kafka概述
一.关于消息队列 消息队列是一种应用间的通信方式,消息就是是指在应用之间传送的数据,它也是进程通信的一种重要的方式. 1.消息队列的基本架构 producer:消息生产者. broker:消息处理中心 ...
- Kafka 概述
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域. Kafka 中,客户端和服务器之间的通信是通过 TCP 协议完成的. 一.传统消息 ...
- Kafka(一)【概述、入门、架构原理】
目录 一.Kafka概述 1.1 定义 二.Kafka快速入门 2.1 安装部署 2.2 配置文件解析 2.3Kafka群起脚本 2.4 topic(增删改查) 2.5 生产和消费者命令行操作 三.K ...
随机推荐
- GitHub无法push的问题
问题背景 换了台别人用过的电脑想要将文件push到github上,出现下面报错 remote: Permission to *****(我的)/gittest.git denied to *****( ...
- 生成centos7 安装脚本
[root@us-1-217 install]# cat gen7.py #!/usr/bin/env python # -*- coding: utf-8 -*- import os, crypt ...
- visual studio 调试 不进断点 断点失效 提示当前不会命中该断点等问题解决
1.首先看一下 当前调试模式是否为debug 2. 点击[调试]>[选项和设置] 将[要求源文件与原始文件完全匹配]勾选掉 3.点击调试的最后一个选项 点击[web] 将调试器内部勾选上需要测 ...
- .NET部分知识点整理
.Net学习 Visual Studio2018 企业版:NJVYC-BMHX2-G77MM-4XJMR-6Q8QF 专业版:KBJFW-NXHK6-W4WJM-CRMQB-G3CDH 开发工具常用V ...
- 【Leetcode】【Easy】Roman to Integer
Given a roman numeral, convert it to an integer. Input is guaranteed to be within the range from 1 t ...
- HCNA实验OSPF基础
1.拓扑图 方法: 1.配置接口IP 2.配置OSPF协议: [R2]ospf 100 [R2-ospf-100]area 0 [R2-ospf-100-area-0.0.0.0]network 12 ...
- HttpClient拉取连载小说
上午刚入手的小说,下午心血来潮想从网站上拉取下来做成电子书,呵呵,瞎折腾-说做就做- [抓包] 这一步比什么都重要,如果找不到获取真正资源的那个请求,就什么都不用做了- 先是打算用迅雷把所有页面都下载 ...
- Git的认识与学习
第一部分:我的git地址是https://github.com/monkeyDyang 第二部分:我对git的认识 Git是一种良好的.支持分支管理的代码管理方式,能很好地解决团队之间协作的问题.每个 ...
- CRUD全栈式编程架构之数据层的设计
CodeFirst 一直以来我们写应用的时候首先都是创建数据库 终于在orm支持codefirst之后,我们可以先建模. 通过模型去创建数据库,并且基于codefirst可以实现方便的 实现数据库迁移 ...
- Xpath定位_1:子找父以及contains的用法
先上xml代码,如下图,在写自动化脚本时,需要定位到数字为10334的td元素.td元素的父元素.父的父元素以及属性值都一样:只有同胞元素的元素值不同.以此可以通过先定位到同胞元素,在找到父元素下的期 ...