spark性能调优(四) spark shuffle中JVM内存使用及配置内幕详情
转载:http://www.cnblogs.com/jcchoiling/p/6494652.html
引言
Spark 从1.6.x 开始对 JVM 的内存使用作出了一种全新的改变,Spark 1.6.x 以前是基于静态固定的JVM内存使用架构和运行机制,如果你不知道 Spark 到底对 JVM 是怎么使用,你怎么可以很有信心地或者是完全确定地掌握和控制数据的缓存空间呢,所以掌握Spark对JVM的内存使用内幕是至关重要的。很多人对 Spark 的印象是:它是基于内存的,而且可以缓存一大堆数据,显现 Spark 是基于内存的观点是错的,Spark 只是优先充分地利用内存而已。如果你不知道 Spark 可以缓存多少数据,你就误乱地缓存数据的话,肯定会有问题。
在数据规模已经确定的情况下,你有多少 Executor 和每个 Executor 可分配多少内存 (在这个物理硬件已经确定的情况下),你必须清楚知道你的內存最多能够缓存多少数据;在 Shuffle 的过程中又使用了多少比例的缓存,这样对于算法的编写以及业务实现是至关重要的!!!
文章的后部份会介绍 Spark 2.x 版本 JVM 的内存使用比例,它被称之为 Spark Unified Memory,这是统一或者联合的意思,但是 Spark 没有用 Shared 这个字,因为 A 和 B 进行 Unified 和 A 和 B 进行 Shared 其实是两个不同的概念, Spark 在运行的时候会有不同类型的 OOM,你必须搞清楚这个 OOM 背后是由什么导致的。 比如说我们使用算子 mapPartition 的时候,一般会创建一些临时对象或者是中间数据,你这个时候使用的临时对象和中间数据,是存储在一个叫 UserSpace 里面的用户操作空间,那你有没有想过这个空间的大小会导致应用程序出现 OOM 的情况,在 Spark 2.x 中 Broadcast 的数据是存储在什么地方;ShuffleMapTask 的数据又存储在什么地方,可能你会认为 ShuffleMapTask 的数据是缓存在 Cache 中。这篇文章会介绍 JVM 在 Spark 1.6.X 以前和 2.X 版本对 Java 堆的使用,还会逐一解密上述几个疑问,也会简单介绍 Spark 1.6.x 以前版本在 Spark On Yarn 上内存的使用案例,希望这篇文章能为读者带出以下的启发:
- 了解 JVM 内存使用架构剖析
- 了解 JVM 在 Spark 1.6.x 以前和 Spark 2.x 中可以缓存多少数据
- 了解 Spark Unified Memory 的原理与机制还有它三大核心空间的用途
- 了解 Shuffle 在 Spark 1.6.x 以前和 Spark 2.x 中可以使用多少缓存
- 了解 Spark1.6.x 以前 on Yarn 对内存的使用
- 了解 在 Spark 1.6.x 以前和 Spark 2.x Shuffle 的参数配置
一、JVM内存使用架构剖析
JVM 有很多不同的区,最开始的时候,它会通过类装载器把类加载进来,在运行期数据区中有 "本地方法栈","程序计数器","Java 栈"、"Java 堆"和"方法区"以及本地方法接口和它的本地库。从 Spark 的角度来谈代码的运行和数据的处理,主要是谈 Java 堆 (Heap) 空间的运用。
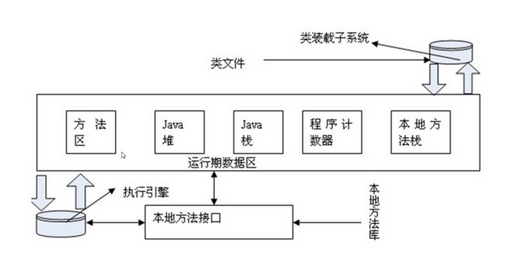
- 本地方法栈:这个是在迭归的时候肯定是至关重要的;
- 程序计数器:这是一个全区计数器,对于线程切换是至关重要的;
- Java 栈 (Stack):Stack 区属于线程私有,高效的程序一般都是并发的,每个线程都会包含一个 Stack 区域,Stack 区域中含有基本的数据类型以及对象的引用,其它线程均不能直接访问该区域;Java 栈分为三大部份:基本数据类型区域、操作指令区域、上下文等;
- Java 堆 (Heap):存储的全部都是 Object 对象实例,对象实例中一般都包含了其数据成员以及与该对象对应类的信息,它会指向类的引用一个,不同线程肯定要操作这个对象;一个 JVM 实例在运行的时候只有一个 Heap 区域,而且该区域被所有的线程共享;补充说明:垃圾回收是回收堆 (heap) 中内容,堆上才有我们的对象。
- 方法区:又名静态成员区域,包含整个程序的 class、static 成员等,类本身的字节码是静态的;它会被所有的线程共享和是全区级别的;
二、Spark 1.6.x 和 2.x 的 JVM 剖析
1、Spark JVM 到底可以缓存多少数据
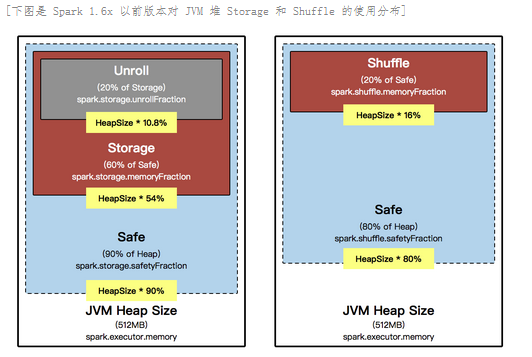
下图显示的是Spark 1.6.x 以前版本对 Java 堆 (heap) 的使用情况,左则是 Storage 对内存的使用,右则是 Shuffle 对内存的使用,这叫 StaticMemoryManagement,数据处理以及类的实体对象都存放在 JVM 堆 (heap) 中。
2、Spark 1.6.x 版本对 JVM 堆的使用
JVM Heap 默认情况下是 512MB,这是取决于 spark.executor.memory 的参数,在回答 Spark JVM 到底可以缓存多少数据这个问题之前,首先了解一下 JVM Heap 在 Spark 中是如何分配内存比例的。无论你定义了 spark.executor.memory 的内存空间有多大,Spark 必然会定义一个安全空间,在默认情况下只会使用 Java 堆上的 90% 作为安全空间,在单个 Executor 的角度来讲,就是 Heap Size x 90%。
埸景一:假设说在一个Executor,它可用的 Java Heap 大小是 10G,实际上 Spark 只能使用 90%,这个安全空间的比例是由 spark.storage.safetyFaction 来控制的。(如果你内存的 Heap 非常大的话,可以尝试调高为 95%),在安全空间中也会划分三个不同的空间:一个是 Storage 空间、一个是 Unroll 空间和一个是 Shuffle 空间。
安全空间 (safe):计算公式是 spark.executor.memory x spark.storage.safetyFraction。也就是 Heap Size x 90%,在埸景一的例子中是 10 x 0.9 = 9G;
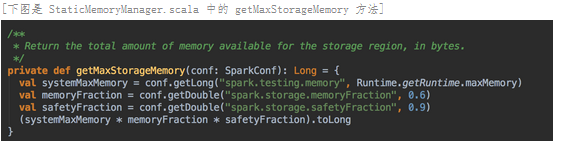
缓存空间 (Storage):计算公式是 spark.executor.memory x spark.storage.safetyFraction x spark.storage.memoryFraction。也就是 Heap Size x 90% x 60%;Heap Size x 54%,在埸景一的例子中是 10 x 0.9 x 0.6 = 5.4G;一个应用程序可以缓存多少数据是由 safetyFraction 和 memoryFraction 这两个参数共同决定的。
Unroll 空间:
计算公式是 spark.executor.memory x spark.storage.safetyFraction x spark.storage.memoryFraction x spark.storage.unrollFraction
也就是 Heap Size x 90% x 60% x 20%;Heap Size x 10.8%,在埸景一的例子中是 10 x 0.9 x 0.6 x 0.2 = 1.8G,你可能把序例化后的数据放在内存中,当你使用数据时,你需要把序例化的数据进行反序例化。

对 cache 缓存数据的影响是由于 Unroll 是一个优先级较高的操作,进行 Unroll 操作的时候会占用 cache 的空间,而且又可以挤掉缓存在内存中的数据 (如果该数据的缓存级别是 MEMORY_ONLY 的话,否则该数据会丢失)。
Shuffle 空间:
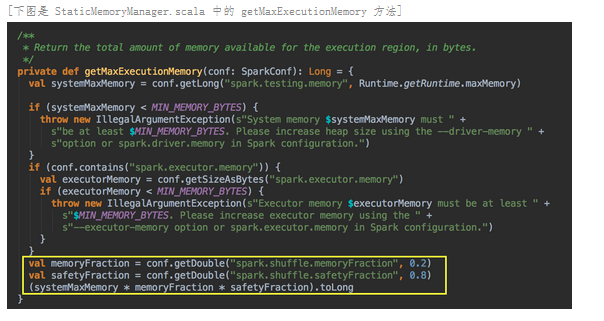
计算公式是 spark.executor.memory x spark.shuffle.memoryFraction x spark.shuffle.safteyFraction。在 Shuffle 空间中也会有一个默认 80% 的安全空间比例,所以应该是 Heap Size x 20% x 80%;Heap Size x 16%,在埸景一的例子中是 10 x 0.2 x 0.8 = 1.6G;从内存的角度讲,你需要从远程抓取数据,抓取数据是一个 Shuffle 的过程,比如说你需要对数据进行排序,显现在这个过程中需要内存空间。
3、Spark Unified Memory 原理和运行机制
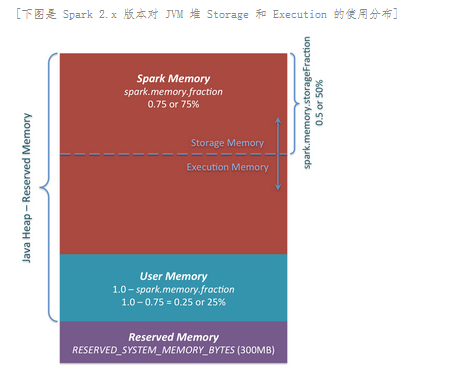
下图是一种叫联合内存 (Spark Unified Memeory),数据缓存与数据执行之间的内存可以相互移动,这是一种更弹性的方式,下图显示的是 Spark 2.x 版本对 Java 堆 (heap) 的使用情况,数据处理以及类的实体对象存放在 JVM 堆 (heap) 中。
spark性能调优(四) spark shuffle中JVM内存使用及配置内幕详情的更多相关文章
- [Spark性能调优] 第四章 : Spark Shuffle 中 JVM 内存使用及配置内幕详情
本课主题 JVM 內存使用架构剖析 Spark 1.6.x 和 Spark 2.x 的 JVM 剖析 Spark 1.6.x 以前 on Yarn 计算内存使用案例 Spark Unified Mem ...
- Spark Shuffle 中 JVM 内存使用及配置内幕详情
本课主题 JVM 內存使用架构剖析 Spark 1.6.x 和 Spark 2.x 的 JVM 剖析 Spark 1.6.x 以前 on Yarn 计算内存使用案例 Spark Unified M ...
- [Spark性能调优] 第二章:彻底解密Spark的HashShuffle
本課主題 Shuffle 是分布式系统的天敌 Spark HashShuffle介绍 Spark Consolidated HashShuffle介绍 Shuffle 是如何成为 Spark 性能杀手 ...
- [Spark性能调优] 第三章 : Spark 2.1.0 中 Sort-Based Shuffle 产生的内幕
本課主題 Sorted-Based Shuffle 的诞生和介绍 Shuffle 中六大令人费解的问题 Sorted-Based Shuffle 的排序和源码鉴赏 Shuffle 在运行时的内存管理 ...
- Spark性能调优
Spark性能优化指南——基础篇 https://tech.meituan.com/spark-tuning-basic.html Spark性能优化指南——高级篇 https://tech.meit ...
- [Spark性能调优] 源码补充 : Spark 2.1.X 中 Unified 和 Static MemoryManager
本课主题 Static MemoryManager 的源码鉴赏 Unified MemoryManager 的源码鉴赏 引言 从源码的角度了解 Spark 内存管理是怎么设计的,从而知道应该配置那个参 ...
- Spark性能调优之Shuffle调优
Spark性能调优之Shuffle调优 • Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外内存(netty是零拷贝),所以使用了堆外内存. ...
- spark性能调优(二) 彻底解密spark的Hash Shuffle
装载:http://www.cnblogs.com/jcchoiling/p/6431969.html 引言 Spark HashShuffle 是它以前的版本,现在1.6x 版本默应是 Sort-B ...
- Spark性能调优之JVM调优
Spark性能调优之JVM调优 通过一张图让你明白以下四个问题 1.JVM GC机制,堆内存的组成 2.Spark的调优为什么会和JVM的调 ...
随机推荐
- 2017-2018-4 20155203《网络对抗技术》Exp3 免杀原理与实践
1.基础问题回答 (1)杀软是如何检测出恶意代码的? 分析恶意程序的行为特征,分析其代码流将其性质归类于恶意代码 (2)免杀是做什么? 使恶意代码避免被查杀,也就是要掩盖恶意代码的特征 (3)免杀的基 ...
- Kubernetes学习之路(二十五)之Helm程序包管理器
目录 1.Helm的概念和架构 2.部署Helm (1)下载helm (2)部署Tiller 3.helm的使用 4.chart 目录结构 5.chart模板 6.定制安装MySQL chart (1 ...
- ElasticSearch入门 第八篇:存储
这是ElasticSearch 2.4 版本系列的第八篇: ElasticSearch入门 第一篇:Windows下安装ElasticSearch ElasticSearch入门 第二篇:集群配置 E ...
- centos7 部署LNMP
1.安装Nginx 使用Nginx官方提供的rpm包 [root@nginx ~]# cat /etc/yum.repos.d/nginx.repo [nginx] name=nginx repo b ...
- Scrapy的日志等级和请求传参
日志等级 日志信息: 使用命令:scrapy crawl 爬虫文件 运行程序时,在终端输出的就是日志信息: 日志信息的种类: ERROR:一般错误: WARNING:警告: INFO:一般的信息: ...
- 《杜增强讲Unity之Tanks坦克大战》11-游戏流程控制
11 游戏流程控制 使用协程来控制游戏流程 11.1 添加MessageText 首先添加一个Text来显示文字 image 设置GameMgr image 11.2 游戏整体流程 下面Gam ...
- linux一切皆文件之tcp socket描述符(三)
一.知识准备 1.在linux中,一切皆为文件,所有不同种类的类型都被抽象成文件(比如:块设备,socket套接字,pipe队列) 2.操作这些不同的类型就像操作文件一样,比如增删改查等 二.环境准备 ...
- Nodejs如何把接收图片base64格式保存为文件存储到服务器上
app.post('/upload', function(req, res){ //接收前台POST过来的base64 var imgData = req.body.imgData; //过滤data ...
- 20170831 php
今天开始学习php 发现这个网站教程感觉入门很轻松 http://www.php.cn/code/25.html 配置环境遇到了端口占用的问题 解决方案: http://www.weekdian.co ...
- 使用git进行代码的推送
首先是对于锐捷墙的问题,登陆github有时可以有时又连不上,网络又非常慢,所以用了十足的耐心才fork完了代码库.链接https://github.com/niconiconiconi/hellow ...