五 web爬虫,scrapy模块,解决重复ur——自动递归url
一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过
记录url可以是缓存,或者数据库,如果保存数据库按照以下方式:
id URL加密(建索引以便查询) 原始URL
保存URL表里应该至少有以上3个字段
1、URL加密(建索引以便查询)字段:用来查询这样速度快,
2、原始URL,用来给加密url做对比,防止加密不同的URL出现同样的加密值
自动递归url

# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from scrapy.selector import Selector class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['hao.360.cn']
start_urls = ['https://hao.360.cn/'] def parse(self, response): #这里做页面的各种获取以及处理 #递归查找url循环执行
hq_url = Selector(response=response).xpath('//a/@href') #查找到当前页面的所有a标签的href,也就是url
for url in hq_url: #循环url
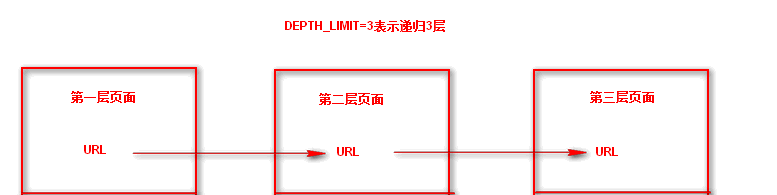
yield scrapy.Request(url=url, callback=self.parse) #每次循环将url传入Request方法进行继续抓取,callback执行parse回调函数,递归循环 #这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
这样就会递归抓取url并且自动执行了,但是需要在settings.py 配置文件中设置递归深度,DEPTH_LIMIT=3表示递归3层
五 web爬虫,scrapy模块,解决重复ur——自动递归url的更多相关文章
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 爬虫scrapy模块
首先下载scrapy模块 这里有惊喜 https://www.cnblogs.com/bobo-zhang/p/10068997.html 创建一个scrapy文件 首先在终端找到一个文件夹 输入 s ...
- 十五 web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式 urllib库中使用xpath表 ...
- (4)分布式下的爬虫Scrapy应该如何做-规则自动爬取及命令行下传参
本次探讨的主题是规则爬取的实现及命令行下的自定义参数的传递,规则下的爬虫在我看来才是真正意义上的爬虫. 我们选从逻辑上来看,这种爬虫是如何工作的: 我们给定一个起点的url link ,进入页面之后提 ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- 二 web爬虫,scrapy模块以及相关依赖模块安装
当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip install Scrapy 手动源码安装,比较麻烦要自己手动安 ...
随机推荐
- Java HashMap工作原理及实现(转载)
https://yikun.github.io/2015/04/01/Java-HashMap工作原理及实现/
- rest_framework之url控制器详解
一 自定义路由(原始方式) from django.conf.urls import url from app01 import views urlpatterns = [ url(r'^books/ ...
- python多线程的两种写法
1.一般多线程 import threading def func(arg): # 获取当前执行该函数的线程的对象 t = threading.current_thread() # 根据当前线程对象获 ...
- Linux下套接字具体解释(九)---poll模式下的IO多路复用server
參照 poll调用深入解析-从poll的实现来讲poll多路复用模型,非常有深度 poll多路复用 poll的机制与select相似,与select在本质上没有多大差别.管理多个描写叙述符也是进行轮询 ...
- MYSQL SET ENUM字段类型
show create table stu;//显示建表语句 create table t1(t enum('a','b','c')); insert into t1 values('a'); cre ...
- Linux的进程/线程通信方式总结(转)
Linux系统中的进程通信方式主要以下几种: 同一主机上的进程通信方式 * UNIX进程间通信方式: 包括管道(PIPE), 有名管道(FIFO), 和信号(Signal) * System V进程通 ...
- 安装vue-cli脚手架
一.安装node.js 1.什么是node.js? Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境. Node.js 使用了一个事件驱动.非阻塞式 I/O 的模 ...
- 关于 sql server 基本使用的建议
1. 把现有的表插入到新表,(表不能存在),为表备份. -- select * into NewTable from OldTable (NewTable 在select 查询的 ...
- laravel queue队列使用
一篇文章: laravel中的队列服务跟其他队列服务也没有什么不同,都是最符合人类思维的最简单最普遍的流程:有一个地方存放队列信息,一个PHP进程在运行时将任务写入,另外一个PHP守护进程轮询队列信息 ...
- LeetCode:二叉搜索树中的搜索【700】
LeetCode:二叉搜索树中的搜索[700] 题目描述 给定二叉搜索树(BST)的根节点和一个值. 你需要在BST中找到节点值等于给定值的节点. 返回以该节点为根的子树. 如果节点不存在,则返回 N ...