学生课程分数的Spark SQL分析
读学生课程分数文件chapter4-data01.txt,创建DataFrame。
url = "file:///D:/chapter4-data01.txt"
rdd = spark.sparkContext.textFile(url).map(lambda line:line.split(','))
rdd.take(3) from pyspark.sql.types import IntegerType,StringType,StructField,StructType
from pyspark.sql import Row #生成“表头”
fields = [StructField('name',StringType(),True),StructField('course',StringType(),True),StructField('score',IntegerType(),True)]
schema = StructType(fields) # 生成“表中的记录”
data = rdd.map(lambda p:Row(p[0],p[1],int(p[2]))) # 把“表头”和“表中的记录”拼接在一起
df_scs = spark.createDataFrame(data,schema)
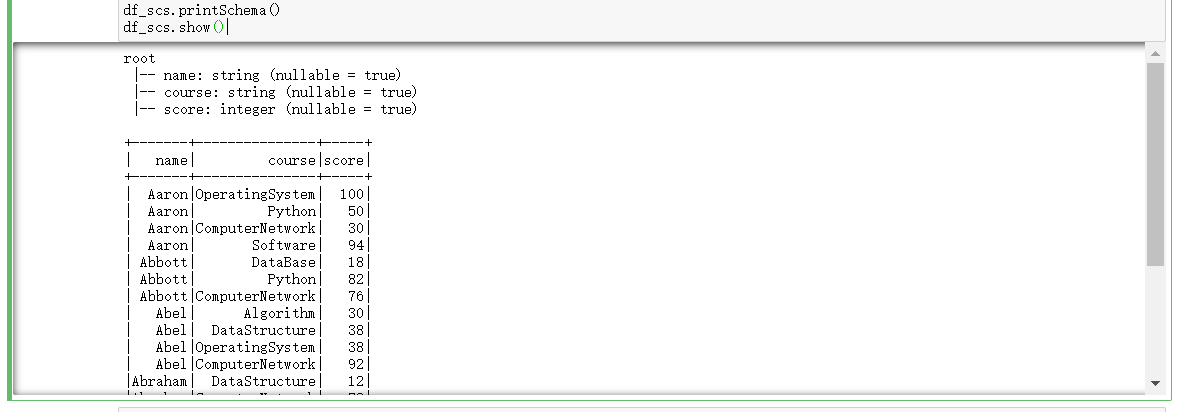
df_scs.printSchema()
df_scs.show()
一:用DataFrame的操作或SQL语句完成以下数据分析要求,并和用RDD操作的实现进行对比:
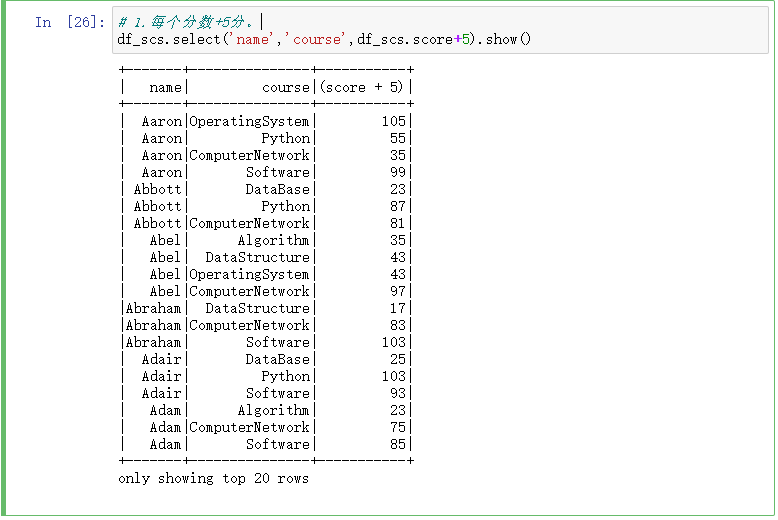
1.每个分数+5分。
# 1.每个分数+5分。
df_scs.select('name','course',df_scs.score+5).show()
2.总共有多少学生?
# 2.总共有多少学生?
df_scs.select(df_scs.name).distinct().count() df_scs.select(df_scs['name']).distinct().count() df_scs.select('name').distinct().count()

3.总共开设了哪些课程?
# 3.总共开设了哪些课程?
df_scs.select('course').distinct().show()

4.每个学生选修了多少门课?
# 4.每个学生选修了多少门课?
df_scs.groupBy('name').count().show()

5.每门课程有多少个学生选?
# 5.每门课程有多少个学生选?
df_scs.groupBy('course').count().show()

6.每门课程大于95分的学生人数?
# 6.每门课程大于95分的学生人数?
df_scs.filter(df_scs.score>95).groupBy('course').count().show()

7.Tom选修了几门课?每门课多少分?
# 7.Tom选修了几门课?每门课多少分?
df_scs.filter(df_scs.name=='Tom').show()

8.Tom的成绩按分数大小排序。
# 8.Tom的成绩按分数大小排序。
df_scs.filter(df_scs.name=='Tom').orderBy(df_scs.score).show()

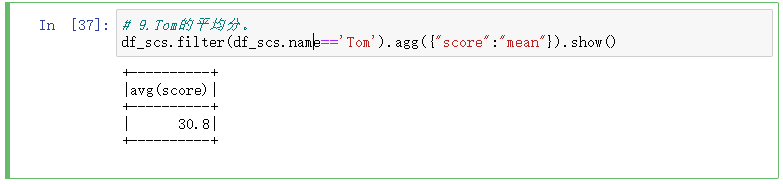
9.Tom的平均分。
# 9.Tom的平均分。
df_scs.filter(df_scs.name=='Tom').agg({"score":"mean"}).show()
10.求每门课的平均分,最高分,最低分。
# 10.求每门课的平均分,最高分,最低分。
df_scs.groupBy("course").agg({"score": "mean"}).show() df_scs.groupBy("course").agg({"score": "max"}).show() df_scs.groupBy("course").agg({"score": "min"}).show()

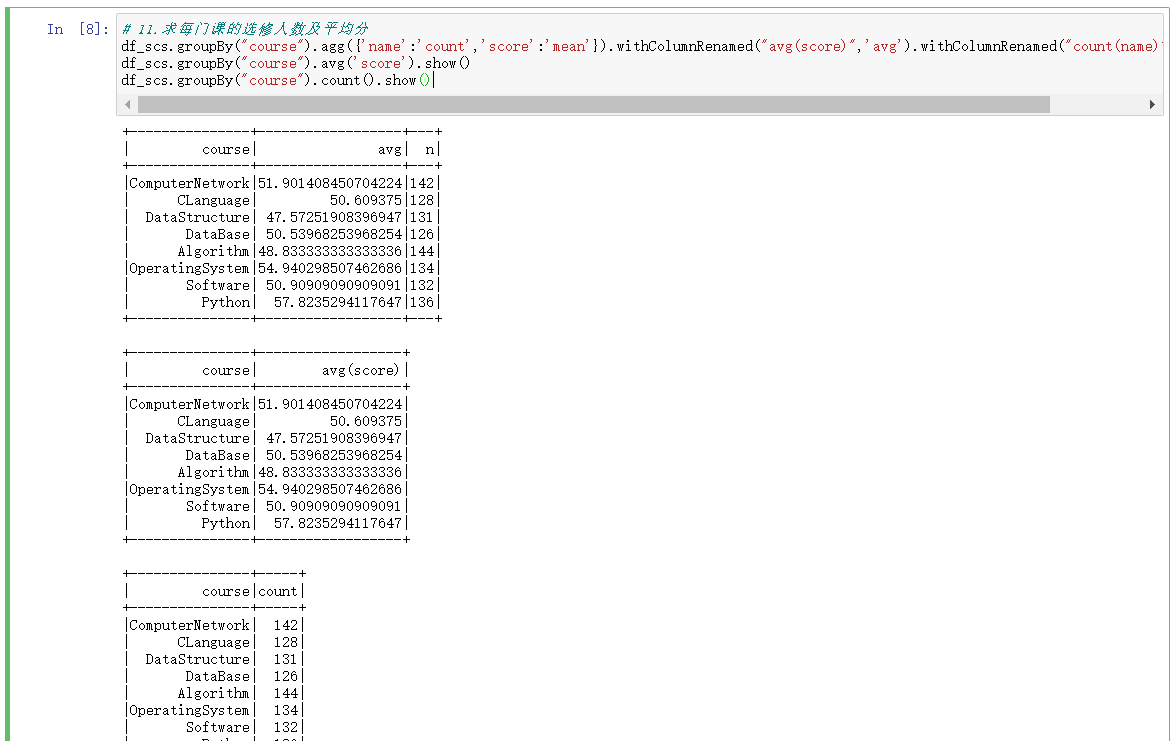
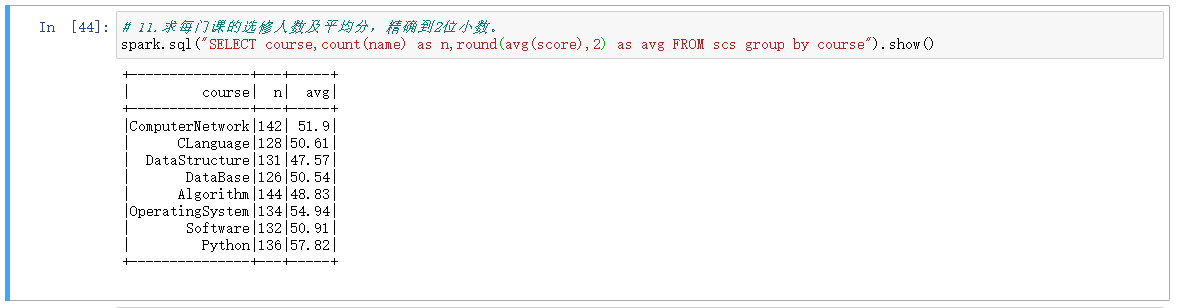
11.求每门课的选修人数及平均分,精确到2位小数。
# 11.求每门课的选修人数及平均分,精确到2位小数。
df_scs.select(countDistinct('name').alias('学生人数'),countDistinct('course').alias('课程数'),round(mean('score'),2).alias('所有课的平均分')).show()

12.每门课的不及格人数,通过率
# 12.每门课的不及格人数,通过率
df_scs.filter(df_scs.score<60).groupBy('course').count().show()

13.结果可视化。
二、用SQL语句完成以上数据分析要求
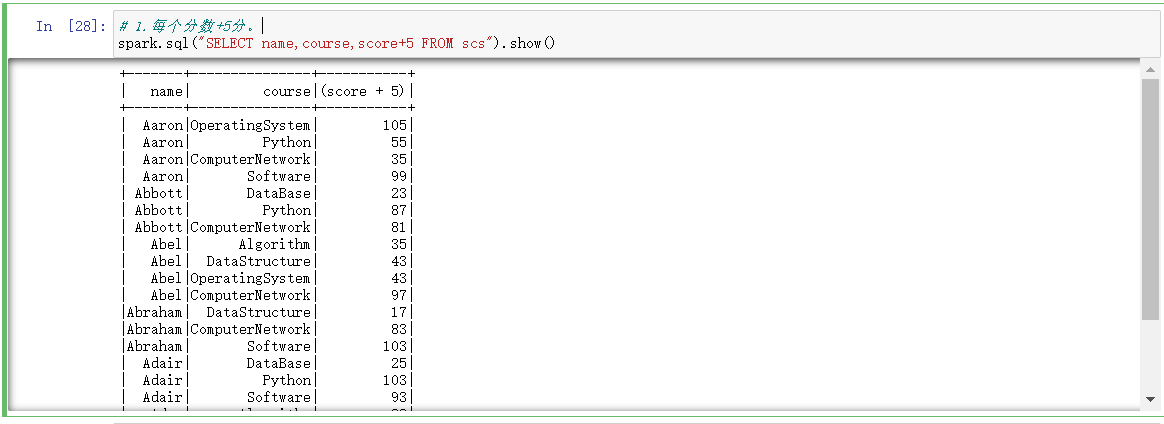
1.每个分数+5分。
# 1.每个分数+5分。
spark.sql("SELECT name,course,score+5 FROM scs").show()
2.总共有多少学生?
# 2.总共有多少学生?
spark.sql("SELECT course,count(name) as n FROM scs group by course").show()

3.总共开设了哪些课程?
# 3.总共开设了哪些课程?
spark.sql("SELECT course FROM scs group by course").show()

4.每个学生选修了多少门课?
# 4.每个学生选修了多少门课?
spark.sql("SELECT name,count(course) FROM scs group by name").show()

5.每门课程有多少个学生选?
# 5.每门课程有多少个学生选?
spark.sql("SELECT course,count(name) FROM scs group by course").show()

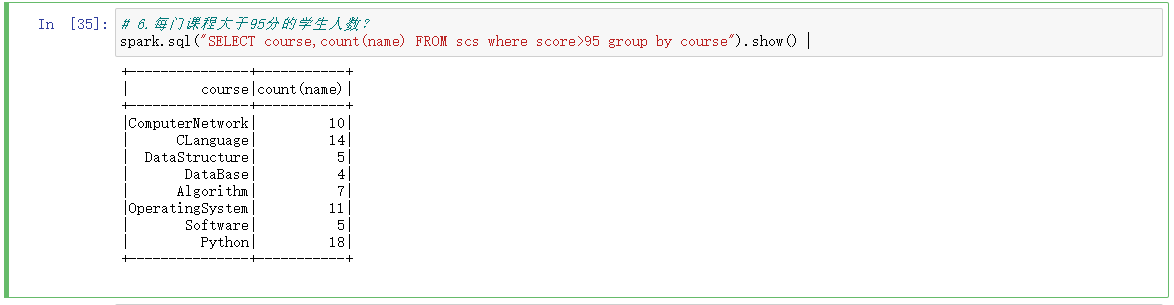
6.每门课程大于95分的学生人数?
# 6.每门课程大于95分的学生人数?
spark.sql("SELECT course,count(name) FROM scs where score>95 group by course").show()
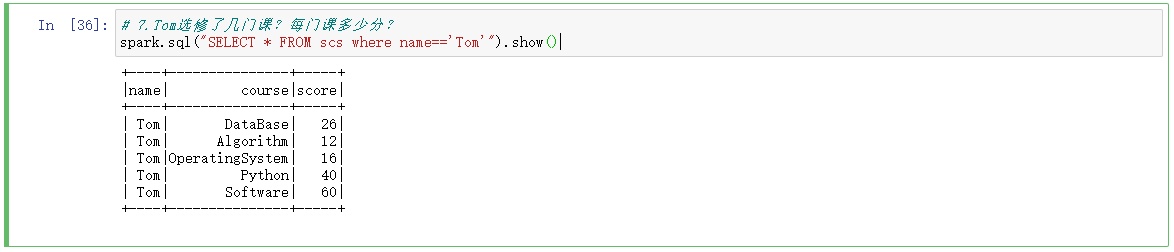
7.Tom选修了几门课?每门课多少分?
# 7.Tom选修了几门课?每门课多少分?
spark.sql("SELECT * FROM scs where name=='Tom'").show()
8.Tom的成绩按分数大小排序。
# 8.Tom的成绩按分数大小排序。
spark.sql("SELECT * FROM scs where name=='Tom' order by score desc").show()

9.Tom的平均分。
# 9.Tom的平均分。
spark.sql("SELECT avg(score) as avg FROM scs where name=='Tom'").show()

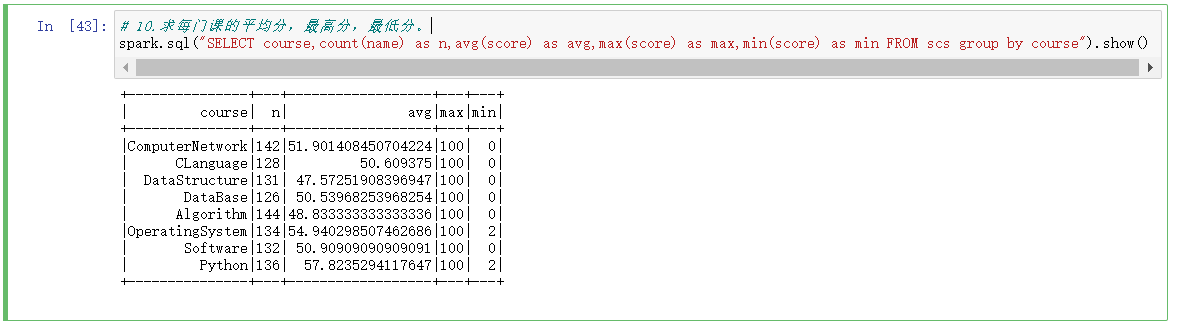
10.求每门课的平均分,最高分,最低分。
# 10.求每门课的平均分,最高分,最低分。
spark.sql("SELECT course,count(name) as n,avg(score) as avg,max(score) as max,min(score) as min FROM scs group by course").show()
11.求每门课的选修人数及平均分,精确到2位小数。
# 11.求每门课的选修人数及平均分,精确到2位小数。
spark.sql("SELECT course,count(name) as n,round(avg(score),2) as avg FROM scs group by course").show()

12.每门课的不及格人数,通过率
# 12.每门课的不及格人数,通过率
spark.sql("SELECT course,count(name) as n,avg(score) as avg FROM scs group by course").createOrReplaceTempView("a")
spark.sql("SELECT course,count(score) as notPass FROM scs where score<60 group by course").createOrReplaceTempView("b")
spark.sql("SELECT * from a left join b on a.course=b.course").show() spark.sql("select a.course,round(a.avg,2),b.notPass,round((a.n-b.notPass)/a.n,2) as passRat from a left join b on a.course=b.course").show()

三、对比分别用RDD操作实现、用DataFrame操作实现和用SQL语句实现的异同。(比较两个以上问题)
例如:每门课的选修人数与平均分
1.RDD实现
# 方法一 combineByKey()
course = words.combineByKey(lambda v:(int(v),1),lambda c,v:(c[0]+int(v),c[1]+1),lambda c1,c2:(c1[0]+c2[0],c1[1]+c2[1])) #每门课的选修人数及所有人的总分。combineByKey()
course.map(lambda x:(x[0],x[1][1],round(x[1][0]/x[1][1],2))).collect() #每门课的选修人数及平均分,精确到2位小数。 #方法二 reduceByKey()
lines.map(lambda line:line.split(',')).map(lambda x:(x[1],(int(x[2]),1))).reduceByKey(lambda a,b:(a[0]+b[0],a[1]+b[1])).collect()

2.DataFrame实现
df_scs.groupBy("course").agg({'name':'count','score':'mean'}).withColumnRenamed("avg(score)",'avg').withColumnRenamed("count(name)",'n').show()
df_scs.groupBy("course").avg('score').show()
df_scs.groupBy("course").count().show()
3.SQL语句
spark.sql("SELECT course,count(name) as n,avg(score) as avg FROM scs group by course").show()
四、结果可视化。
函数:http://spark.apache.org/docs/2.2.0/api/python/pyspark.sql.html#module-pyspark.sql.functions
学生课程分数的Spark SQL分析的更多相关文章
- 08 学生课程分数的Spark SQL分析
读学生课程分数文件chapter4-data01.txt,创建DataFrame. 用DataFrame的操作或SQL语句完成以下数据分析要求,并和用RDD操作的实现进行对比: 每个分数+5分. 总共 ...
- hive Spark SQL分析窗口函数
Spark1.4发布,支持了窗口分析函数(window functions).在离线平台中,90%以上的离线分析任务都是使用Hive实现,其中必然会使用很多窗口分析函数,如果SparkSQL支持窗口分 ...
- Spark SQL大数据处理并写入Elasticsearch
SparkSQL(Spark用于处理结构化数据的模块) 通过SparkSQL导入的数据可以来自MySQL数据库.Json数据.Csv数据等,通过load这些数据可以对其做一系列计算 下面通过程序代码来 ...
- 05 RDD练习:词频统计,学习课程分数
.词频统计: 1.读文本文件生成RDD lines 2.将一行一行的文本分割成单词 words flatmap() 3.全部转换为小写 lower() 4.去掉长度小于3的单词 filter() 5. ...
- 小菜菜mysql练习解读分析1——查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数
查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数 好的,第一道题,刚开始做,就栽了个跟头,爽歪歪,至于怎么栽跟头的 ——需要分析题目,查询的是 ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- Spark SQL慕课网日志分析(1)--系列软件(单机)安装配置使用
来源: 慕课网 Spark SQL慕课网日志分析_大数据实战 目标: spark系列软件的伪分布式的安装.配置.编译 spark的使用 系统: mac 10.13.3 /ubuntu 16.06,两个 ...
- Mysql--查询"01"课程比"02"课程成绩高的学生的信息及课程分数
今天在写Mysql代码作业时,写到这个题,感觉值得分享!!!!!!! 查询"01"课程比"02"课程成绩高的学生的信息及课程分数 分析如下: 首先先查询&quo ...
- Spark SQL概念学习系列之Spark SQL 架构分析(四)
Spark SQL 与传统 DBMS 的查询优化器 + 执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用的 Spark 作为执行引擎. Spark SQL 的查询优化是Catalyst ...
- Spark SQL 源代码分析之 In-Memory Columnar Storage 之 in-memory query
/** Spark SQL源代码分析系列文章*/ 前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的. 那么基于以上存储结构,我们查询cache ...
随机推荐
- window.onload / onscroll/onresize 事件
onload当文档加载完成后执行一些操作 window.onload = function(){ console.log("页面加载完成") } onscroll当页面发生滚动时执 ...
- R语言文本数据挖掘(三)
文本分词,就是对文本进行合理的分割,从而可以比较快捷地获取关键信息.例如,电商平台要想了解更多消费者的心声,就需要对消费者的文本评论数据进行内在信息的数据挖掘分析,而文本分词是文本挖掘的重要步骤.R语 ...
- 逍遥自在学C语言 | 逻辑运算符
前言 一.人物简介 第一位闪亮登场,有请今后会一直教我们C语言的老师 -- 自在. 第二位上场的是和我们一起学习的小白程序猿 -- 逍遥. 二.构成和表示方式 逻辑运算符是用来比较和操作布尔值的运算符 ...
- Charlotte Holmes series
Charlotte Holmes Novel The charactors are adorable. Jamie and Charlotte are a very cute couple. More ...
- Java设计模式 —— 面向对象设计原则
1 设计模式概述 1.1 设计模式的定义与分类 设计模式的定义 Design patterns are descriptions of communicating objects and classe ...
- Idea快捷键——查找源码
双击shift 输入要查找源码类 相当于查 java_jdk_chm Ctrl+F12 :浏览类
- devops|中小公司不要做研发效能度量
我特别反感那些不顾公司现状一上来就想要做研发效能度量的人,尤其是想把研发效能度量当成锤子四处去敲打螺丝钉的人. 没几个人的小公司上来就做研发效能度量,就如同普通人一上来直接问媒婆怎么能娶到迪丽热巴.解 ...
- 非关系型数据库---Redis安装与基本使用
一.数据库类型 关系数据库管理系统(RDBMS) 非关系数据库管理系统(NoSQL) 按照预先设置的组织机构,将数据存储在物理介质上(即:硬盘上) 数据之间可以做无关联操作 (例如: 多表查询,嵌套查 ...
- 一天吃透JVM面试八股文
什么是JVM? JVM,全称Java Virtual Machine(Java虚拟机),是通过在实际的计算机上仿真模拟各种计算机功能来实现的.由一套字节码指令集.一组寄存器.一个栈.一个垃圾回收堆和一 ...
- .NET周报 【4月第5期 2023-04-30】
国内文章 基于 Github 平台的 .NET 开源项目模板. 嘎嘎实用! https://www.cnblogs.com/NMSLanX/p/17326728.html 大家好,为了使开源项目的维护 ...