大数据笔记(四)——操作HDFS
一.Web Console:端口50070
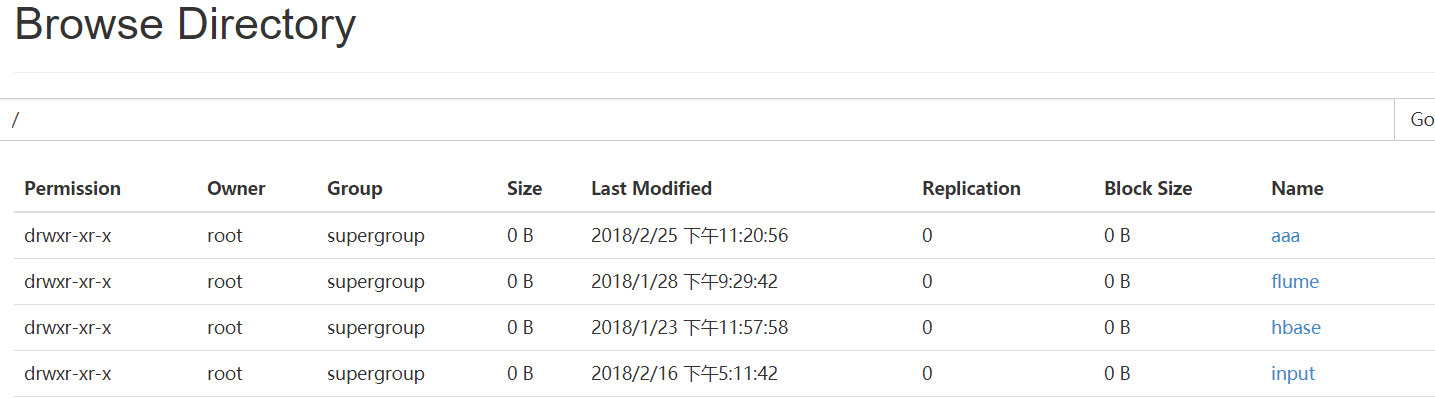
二.HDFS的命令行操作
(一)普通操作命令
HDFS 操作命令帮助信息: hdfs dfs + Enter键
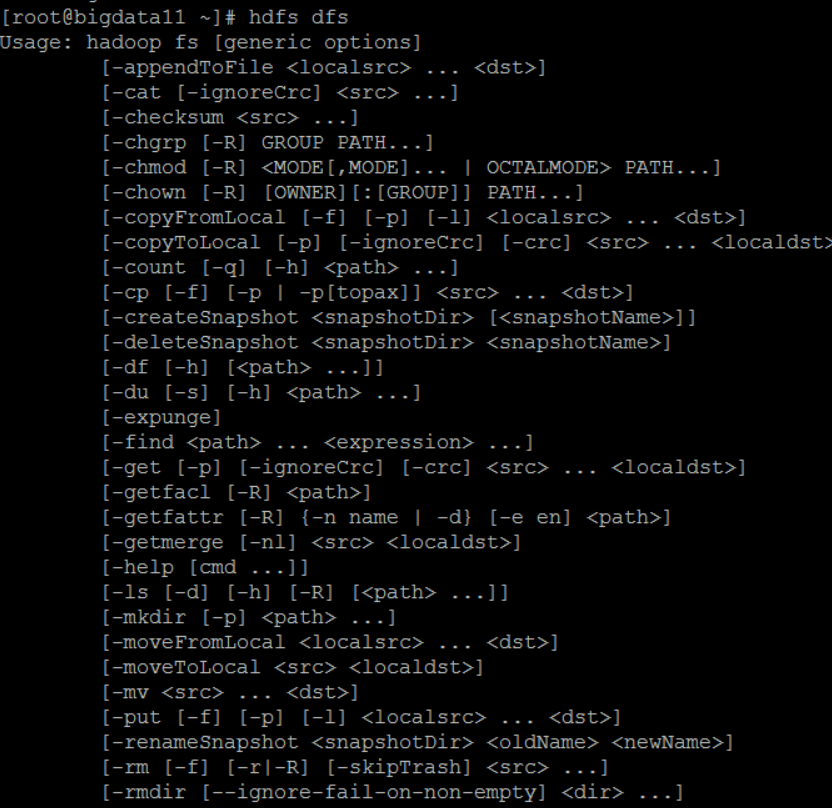
常见命令
1. -mkdir
- 在HDFS上创建目录:hdfs dfs -mkdir /aaa
- 如果父目录不存在,使用 -p 命令先创建父目录:

2. -ls /
查看hdfs文件系统根目录下的目录和文件:

3.-ls -R /
查看所有目录和文件:

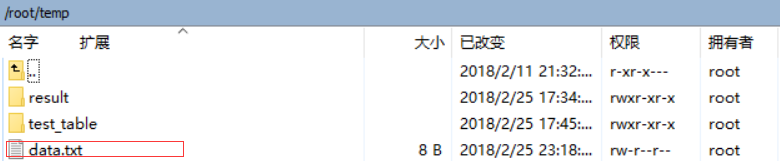
4.-put
上传数据:将本地Linux文件data.txt上传到HDFS的aaa目录下
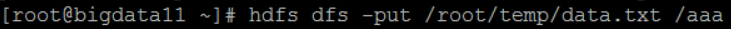
-copyFromLocal 上传数据,类似-put
-moveFromLocal 上传数据,类似-put,相当于ctrl+x
5.-get 下载数据(刚才上传数据时已经有data.txt,所以要把Linux目录下的data.txt先删除)

6.-rm: 删除目录
-rmr: 删除目录,包括子目录
hdfs dfs -rmr /bbb

7. -getmerge:把某个目录下的文件,合并后再下载
8.-cp:拷贝 hdfs dfs -cp /input/data.txt /input/data2.txt
9.-mv:移动 hdfs dfs -cp /input/data.txt /aaa/a.txt
10.-count 统计hdfs对应路径下的目录个数,文件个数,文件总计大小:hdfs dfs -count /students

11.-du 显示hdfs对应路径下每个文件夹和目录的大小 hdfs dfs -du /students

12.-cat 查看文本的内容 hdfs dfs -cat /input/data.txt

13.balancer:平衡操作 如果管理员发现某些DataNode上保存数据过多,某些过少,就可以采取此操作
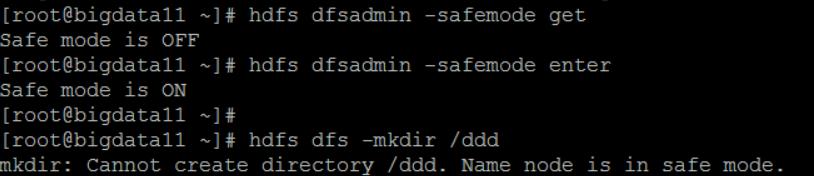
(二)管理命令:hdfs dfsadmin
举例:
1.-report 打印hdfs的报告 hdfs dfsadmin -report
2.-safemode:安全模式(安全模式下对hdfs只能进行只读操作)

三.JavaAPI
通过HDFS提供的JavaAPI,我们可以完成以下的功能:
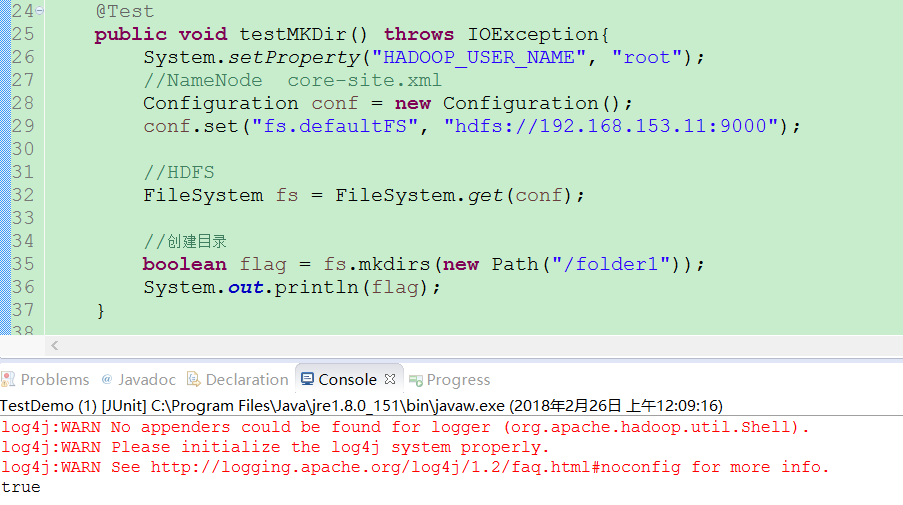
(一)在HDFS上创建目录
(二)写入数据(上传文件)
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test; import com.jcraft.jsch.Buffer; public class TestUpload { @Test
public void testUpload() throws IOException{
System.setProperty("HADOOP_USER_NAME", "root");
//NameNode core.site.xml
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.153.11:9000"); //构造一个输入流 <---HDFS
FileSystem fs = FileSystem.get(conf); InputStream in = new FileInputStream("D:\\temp\\hadoop-2.7.3.tar.gz"); //构造一个输出流------> HDFS
OutputStream out = fs.create(new Path("/tools/hadoop-2.7.3.tar.gz")); byte[] buffer = new byte[1024];
int len = 0; while ((len=in.read(buffer)) > 0) {
out.write(buffer, 0, len);
} out.flush(); in.close();
out.close(); }
}
(三)通过 FileSystem API 读取数据(下载文件)
(四)查看目录及文件信息
(五)查找某个文件在HDFS集群的位置
(六)删除数据
(七)获取HDFS集群上所有数据节点信息

大数据笔记(四)——操作HDFS的更多相关文章
- 大数据学习——java操作hdfs环境搭建以及环境测试
1 新建一个maven项目 打印根目录下的文件的名字 添加pom依赖 pom.xml <?xml version="1.0" encoding="UTF-8&quo ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- Dapper学习(四)之Dapper Plus的大数据量的操作
这篇文章主要讲 Dapper Plus,它使用用来操作大数量的一些操作的.比如插入1000条,或者10000条的数据时,再使用Dapper的Execute方法,就会比较慢了.这时候,可以使用Dappe ...
- 大数据笔记04:大数据之Hadoop的HDFS(基本概念)
1.HDFS是什么? Hadoop分布式文件系统(HDFS),被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点. 2.HDFS ...
- 大数据笔记09:大数据之Hadoop的HDFS使用
1. HDFS使用: HDFS内部中提供了Shell接口,所以我们可以以命令行的形式操作HDFS
- 大数据-hadoop生态之-HDFS
一.HDFS初识 hdfs的概念: HDFS,它是一个文件系统,用于存储文件,通过目录树定位文件,其次,他是分布式的,由很多服务器联合起来 实现功能,集群中的服务器各有各自的角色 HDFS设计适合一次 ...
- 大数据 - hadoop基础概念 - HDFS
Hadoop之HDFS的概念及用法 1.概念介绍 Hadoop是Apache旗下的一个项目.他由HDFS.MapReduce.Hive.HBase和ZooKeeper等成员组成. HDFS是一个高度容 ...
- 大数据【二】HDFS部署及文件读写(包含eclipse hadoop配置)
一 原理阐述 1' DFS 分布式文件系统(即DFS,Distributed File System),指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连.该系统架构 ...
- 大数据【四】MapReduce(单词计数;二次排序;计数器;join;分布式缓存)
前言: 根据前面的几篇博客学习,现在可以进行MapReduce学习了.本篇博客首先阐述了MapReduce的概念及使用原理,其次直接从五个实验中实践学习(单词计数,二次排序,计数器,join,分 ...
- 大数据:Hadoop(HDFS 的设计思路、设计目标、架构、副本机制、副本存放策略)
一.HDFS 的设计思路 1)思路 切分数据,并进行多副本存储: 2)如果文件只以多副本进行存储,而不进行切分,会有什么问题 缺点 不管文件多大,都存储在一个节点上,在进行数据处理的时候很难进行并行处 ...
随机推荐
- 防抖和节流 lodash插件
lodash.debounce lodash.debounce(function(){ },1000) 函数防抖原理 调用函数时,马上清理定时器.然后再设置一个定时器包含函数
- Luogu P4040 [AHOI2014/JSOI2014]宅男计划
题目 显然存活天数与叫外卖次数的函数是凸函数. 所以三分买外卖的次数. 然后把食品按保质期升序排序. 并且单调栈搞一下,把又贵又保质期短的丢掉. 那么随着保质期的增加,食品的价格一定上涨. 所以我们从 ...
- MySQL索引面试题分析(索引分析,典型题目案例)
[建表语句] create table test03( id int primary key not null auto_increment, c1 char(10), c2 char(10), c3 ...
- 18.Linux-CentOS系统根目录空间使用率100%问题?
问题描述:发现服务器根目录爆满100%? 排查步骤:1.先检查文件索引节点iNode使用率情况,[root@localhost ~]# df -hTi2.查看无用文件是否居多:[root@localh ...
- Python核心技术与实战——八|匿名函数
今天我们来学习一下匿名函数.在学习了上一节的自定义函数后,是时候了解一下匿名函数了.他们往往非常简短,就一行,而且有个关键字:lambda.这就是弥明函数. 一.匿名函数基础 匿名函数的基本格式是这样 ...
- php理解递归
递归有一段时间很让人难已理解,突然发现一个很好的办法来理解,现在跟大家分享一下: <?php function fact(n){ if( n == 1){ return 1; } retrun ...
- CF1151F Sonya and Informatics (计数dp+矩阵优化)
题目地址 Solution (duyi是我们的红太阳) (这里说一句:这题看上去是一个概率dp,鉴于这题的概率dp写法看上去不好写,我们其实可以写一个计数dp) 首先拿到这个题目我们要能设出一个普通d ...
- 前端之JQuery:JQuery文档操作
jquery之文档操作 一.相关知识点总结1.CSS .css() - .css("color") -> 获取color css值 - .css("color&qu ...
- POJ-1459-Pwoer Network(最大流Dinic, 神仙输入)
链接: https://vjudge.net/problem/POJ-1459 题意: A power network consists of nodes (power stations, consu ...
- 【leetcode】1074. Number of Submatrices That Sum to Target
题目如下: Given a matrix, and a target, return the number of non-empty submatrices that sum to target. A ...