Spark任务调度初识
前置知识
spark任务模型
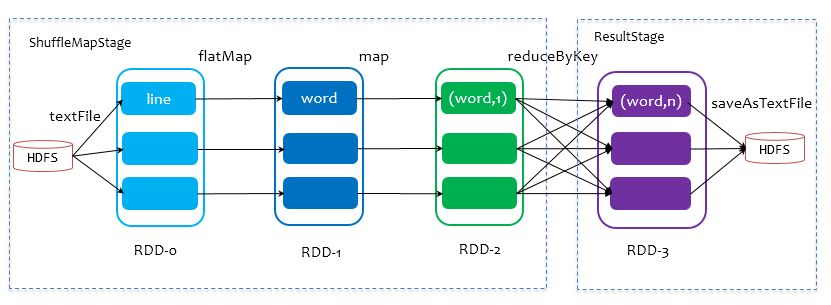
- job:action的调用,触发了DAG的提交和整个job的执行。
- stage:stage是由是否shuffle来划分,如果发生shuffle,则分为2个stage。
- taskSet:每一个stage对应1个taskset.1个taskset有多个task, 由RDD的partition数据决定,并行度就是各自RDD的partition数目。
- task:同一个stage中同一个partition中的数据与处理过程,视为1个task. task从横向上看,与partition数量一致;从纵向上看,task包含1个stage中的处理过程,如下面中的mapstage中的flatmap、map、reduceBykey.
spark资源模型
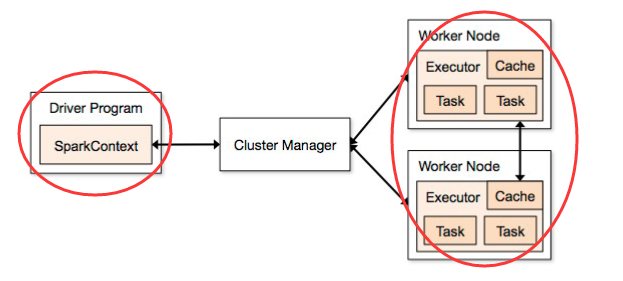
Executor是真正执行任务的进程,本身拥有若干cpu和内存,可以执行以线程为单位的计算任务,它是资源管理系统能够给予的最小单位。
yarn资源

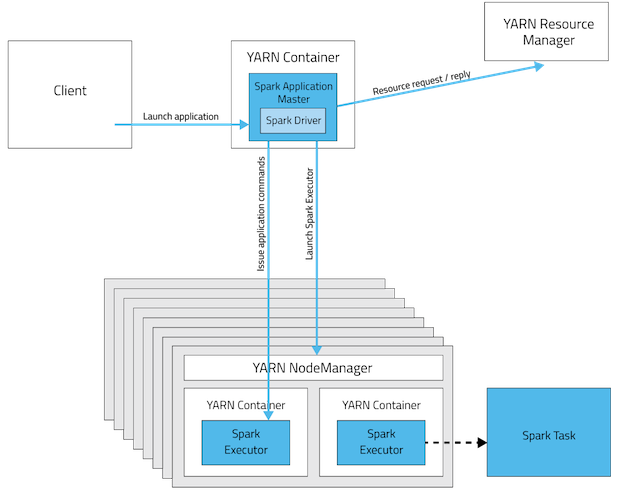
YARN的基本组成结构,YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等几个组件构成。
ResourceManager是Master上一个独立运行的进程,负责集群统一的资源管理、调度、分配等等;
NodeManager是Slave上一个独立运行的进程,负责上报节点的状态;
App Master和Container是运行在Slave上的组件,Container是yarn中分配资源的一个单位,包涵内存、CPU等等资源,yarn以Container为单位分配资源。
spark executor与yarn container的关系
Running Spark Applications on YARN
When running Spark on YARN, each Spark executor runs as a YARN container. 在spark on yarn模式,每个executor运行在1个yarn container上。
- Cluster Deployment Mode
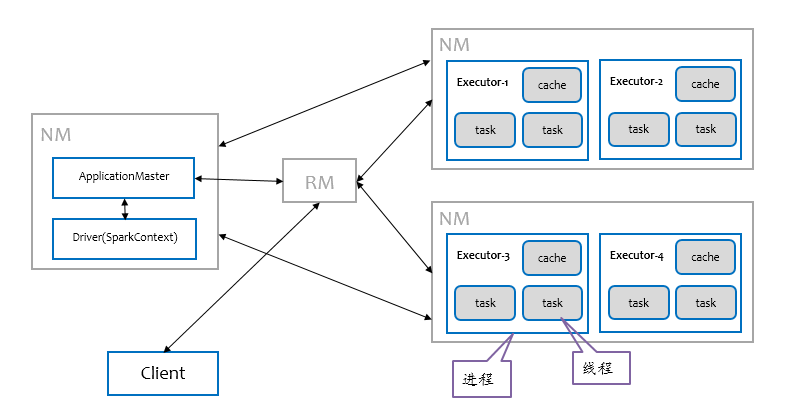
两层模型
spark的任务模型与资源模型是如何匹配?
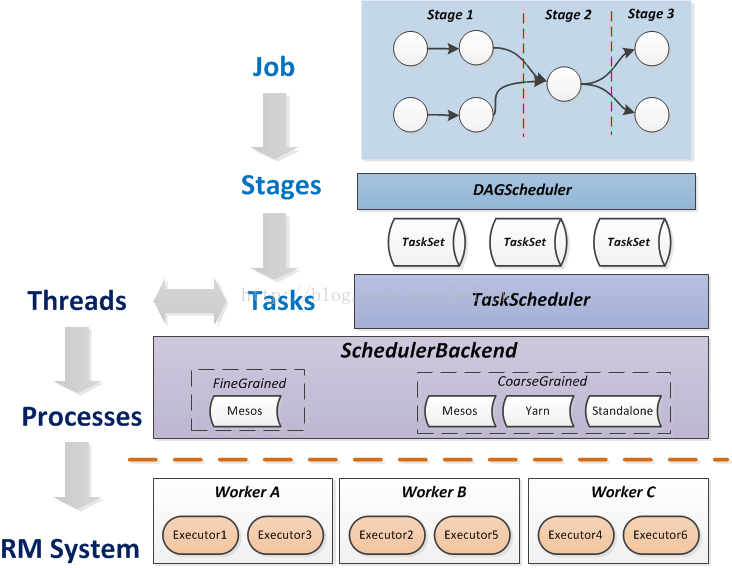
如上图所示:关键在于TaskScheduler与SchedulerBackend,由它们来适配task与executor。
spark的任务模型将提交的job分解成最小的任务单位task, 由TaskScheduler根据调度策略和task的资源申请情况来调用具体的SchedulerBackend(如yarn)。
SchedulerBackend的最小资源管理单位是executor。看workers中executros的资源“够不够”,“符不符合”task,ok的话task就被正式launch起来。注意,这里资源"够不够"是很好判断的,在TaskScheduler里设置了每个task启动需要的cpu个数,默认是1,所以只需要做核数的大小判断和减1操作就可以遍历分配下去。而"符不符合"这件事情,取决于每个tasks的locality设置。
task的locality有五种,按优先级高低排:PROCESS_LOCAL,NODE_LOCAL,NO_PREF,RACK_LOCAL,ANY。也就是最好在同个进程里,次好是同个node(即机器)上,再次是同机架,或任意都行。task有自己的locality,如果本次资源里没有想要的locality资源,怎么办呢?spark有一个spark.locality.wait参数,默认是3000ms。对于process,node,rack,默认都使用这个时间作为locality资源的等待时间。所以一旦task需要locality,就可能会触发delay scheduling。
SchedulerBackend是管“粮食”的,同时它在启动后会定期地去“询问”TaskScheduler有没有任务要运行,也就是说,它会定期地“问”TaskScheduler“我有这么余量,你要不要啊”,TaskScheduler在SchedulerBackend“问”它的时候,会从调度队列中按照指定的调度策略选择TaskSetManager去调度运行。
调度策略
- FIFO(默认): 谁先提交谁先执行,后面的任务需要等待前面的任务执行。
- FAIR: 支持在调度池中为任务进行分组,不同的调度池权重不同,任务可以按照权重来决定执行顺序。
参考文献
Spark任务调度初识的更多相关文章
- Spark任务调度流程及调度策略分析
Spark任务调度 TaskScheduler调度入口: (1) CoarseGrainedSchedulerBackend 在启动时会创建DriverEndPoint. 而DriverE ...
- Spark任务调度
不多说,直接上干货! Spark任务调度 DAGScheduler 构建Stage—碰到shuffle就split 记录哪个RDD 或者Stage 输出被物化 重新提交shuffle 输出丢失的sta ...
- 【Spark】Spark任务调度相关知识
文章目录 准备知识 DAG 概述 shuffle 概述 SortShuffleManager 普通机制 bypass机制 Spark任务调度 流程 准备知识 要弄清楚Spark的任务调度流程,就必须要 ...
- 【Spark工作原理】Spark任务调度理解
Spark内部有若干术语(Executor.Job.Stage.Task.Driver.DAG等),需要理解并搞清其内部关系,因为这是性能调优的基石. 节点类型有: 1. Master 节点: 常 ...
- spark任务调度和资源分配
Spark调度模式 FIFO和FAIR Spark中的调度模式主要有两种:FIFO和FAIR. 默认情况下Spark的调度模式是FIFO(先进先出),谁先提交谁先执行,后面的任务需要等待 ...
- spark udf 初识初用
直接上代码,详见注释 import org.apache.spark.sql.hive.HiveContext import org.apache.spark.{SparkContext, Spark ...
- spark任务调度模式,动态资源分配
官网链接: http://spark.apache.org/docs/latest/job-scheduling.html 主要介绍: 1 application级调度方式 2 单个applicati ...
- spark中资源调度任务调度
在spark的资源调度中 1.集群启动worker向master汇报资源情况 2.Client向集群提交app,向master注册一个driver(需要多少core.memery),启动一个drive ...
- Spark 性能相关参数配置详解-任务调度篇
随着Spark的逐渐成熟完善, 越来越多的可配置参数被添加到Spark中来, 本文试图通过阐述这其中部分参数的工作原理和配置思路, 和大家一起探讨一下如何根据实际场合对Spark进行配置优化. 由于篇 ...
随机推荐
- 鼠标拖拉div宽度
先看效果 先进入页面 当鼠标停留在中间div时,鼠标变成双箭头 点击拖拉 往右边拉 往最左边拉 代码 <!DOCTYPE html> <html> <head> & ...
- POJ 3660 Cow Contest【floyd】
题目链接: http://poj.org/problem?id=3660 题目大意: 给出n头牛,m个关系,关系为a的战力比b高.求最后可以确定排名的牛的数量 思路: 1.如果一头牛跟其他所有牛都确定 ...
- Java基础篇---多线程
内容导航: 1.多线程的实现方式 2.线程安全问题 3.线程间通信 4.生产者消费者模式 第一部分多线程的实现方式 在java中多线程实现方式有2种 一.自定义一个类A,继承Thread类 publi ...
- Python基础总结之第十天开始【认识模块、包和库】(新手可相互督促)
每天都有一种备课的赶脚~~~ 什么是模块? 在实际的开发过程中,代码量肯定有成千上万行的代码,甚至十几万行代码也很正常吧... 那么这么多的代码如果放在一个文件中,肯定是很不合适的,为了以后程序的编写 ...
- VS2013:error C1069: 无法读取编译器命令行
前一阵搞python和matlab,没用VS 2013,今天打开一个C++程序想跑一跑,突然蹦出这么个错误,然后发现电脑上所有的程序都会这样了. 后来发现是TMP/TEMP环境变量路径有空格的问题,更 ...
- Centos6.5下安装jumpserver-1.4.1报错AttributeError: module 'gssapi' has no attribute 'GSSException'
报错: >>> import paramiko Traceback (most recent call last): File "<stdin>", ...
- 使用kubeadm进行单master(single master)和高可用(HA)kubernetes集群部署
kubeadm部署k8s 使用kubeadm进行k8s的部署主要分为以下几个步骤: 环境预装: 主要安装docker.kubeadm等相关工具. 集群部署: 集群部署分为single master(单 ...
- 关于Linux fontconfig 字体库的坑
01.安装字体软件 yum -y install fontconfig 然后把字体拷过去就行了 cd /usr/share/fonts fc-list 这是查看 02.拷贝字体到指定目录 cp sim ...
- python基础知识0-1
绝对值:abs age = -19 age.__abs__() 19 相加: add age.__add__() 与运算:and age.__add__() 比较两个数大小:cmp age._cmp_ ...
- C# Base64 操作类
using System; using System.Text; namespace VWFC.IT.CUP.BLL.Util { /// <summary> /// Base64 too ...