【大数据】了解Hadoop框架的基础知识
介绍
此Refcard提供了Apache Hadoop,这是最流行的软件框架,可使用简单的高级编程模型实现大型数据集的分布式存储和处理。我们将介绍Hadoop最重要的概念,描述其架构,指导您如何开始使用它以及在Hadoop上编写和执行各种应用程序。
简而言之,Hadoop是Apache Software Foundation的一个开源项目,可以安装在服务器集群上,以便这些服务器可以通信并协同工作来存储和处理大型数据集。Hadoop近年来因其有效处理大数据的能力而变得非常成功。它允许公司将所有数据存储在一个系统中,并对这些数据进行分析,否则传统解决方案不可能或非常昂贵。
围绕Hadoop构建的许多配套工具提供了各种各样的处理技术。与辅助系统和实用程序的集成非常出色,使Hadoop的实际工作更轻松,更高效。这些工具共同构成了Hadoop生态系统。
您可以将Hadoop视为大数据操作系统,从而可以在所有庞大的数据集上运行不同类型的工作负载。其范围从离线批处理到机器学习再到实时流处理。
热门提示:访问http://hadoop.apache.org以获取有关项目的更多信息并访问详细文档。
要安装Hadoop,您可以从http://hadoop.apache.org获取代码或(更推荐)使用其中一个Hadoop发行版。三种最广泛使用的来自Cloudera(CDH),Hortonworks(HDP)和MapR。Hadoop发布是Hadoop生态系统捆绑在一起的一组工具,由相应的供应商保证,可以很好地协同工作。此外,每个供应商都提供工具(开源或专有)来配置,管理和监控整个平台。
设计理念
为了解决处理和存储大型数据集的挑战,Hadoop是根据以下核心特征构建的:
分发 - 存储和处理不是构建一台大型超级计算机,而是分布在一组通信和协同工作的小型机器上。
横向可扩展性 - 只需添加新计算机即可轻松扩展Hadoop集群。每台新机器都会按比例增加Hadoop集群的总存储和处理能力。
容错 - 即使少数硬件或软件组件无法正常工作,Hadoop仍可继续运行。
成本优化 - Hadoop不需要昂贵的高端服务器,无需商业许可即可正常工作。
编程抽象 - Hadoop负责处理与分布式计算相关的所有混乱细节。借助高级API,用户可以专注于实现解决现实问题的业务逻辑。
数据位置 - Hadoop不会将大型数据集移动到运行应用程序的位置,而是运行数据已经存在的应用程序。
Hadoop组件
Hadoop分为两个核心组件:
HDFS - 分布式文件系统。
YARN - 集群资源管理技术。
热门提示:许多执行框架在YARN之上运行,每个框架都针对特定用例进行了调整。最重要的内容将在下面的“YARN Applications”中讨论。
让我们仔细看看他们的架构并描述他们如何合作。
HDFS
HDFS是一个Hadoop分布式文件系统。它可以在您需要的任意数量的服务器上运行 - HDFS可以轻松扩展到数千个节点和数PB的数据。
HDFS设置越大,某些磁盘,服务器或网络交换机出现故障的概率就越大。HDFS通过在多个服务器上复制数据来幸免于这些类型的故障。HDFS自动检测给定组件是否已发生故障,并采取对用户透明的必要恢复操作。
HDFS设计用于存储数百兆字节或千兆字节的大型文件,并为它们提供高吞吐量的流数据访问。最后但同样重要的是,HDFS支持一次写入多次读取模型。对于这个用例,HDFS就像一个魅力。但是,如果您需要存储大量具有随机读写访问权限的小文件,那么其他系统(如RDBMS和Apache HBase)可以做得更好。
注意:HDFS不允许您修改文件的内容。只支持在文件末尾附加数据。但是,Hadoop设计的HDFS是众多可插拔存储选项之一 - 例如,使用专有文件系统MapR-F,文件完全可读写。其他HDFS替代品包括Amazon S3,Google Cloud Storage和IBM GPFS。
HDFS的体系结构
HDFS由在选定群集节点上安装和运行的以下守护程序组成:
NameNode - 负责管理文件系统命名空间(文件名,权限和所有权,最后修改日期等)以及控制对存储在HDFS中的数据的访问的主进程。如果NameNode已关闭,则无法访问您的数据。幸运的是,您可以配置多个NameNode,以确保此关键HDFS进程的高可用性。
DataNodes - 安装在集群中每个工作节点上的从属进程,负责存储和提供数据。
图1说明了在4节点集群上安装HDFS。其中一个节点托管NameNode守护程序,而其他三个运行DataNode守护程序。
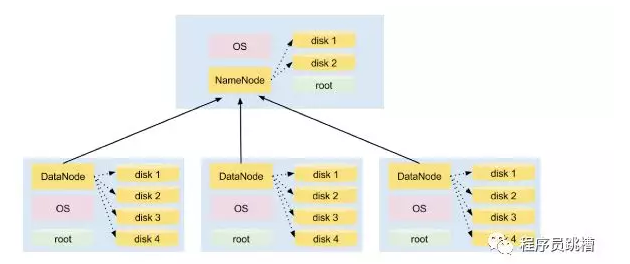
注意:NameNode和DataNode是在Linux发行版之上运行的Java进程,例如RedHat,Centos,Ubuntu等。他们使用本地磁盘存储HDFS数据。
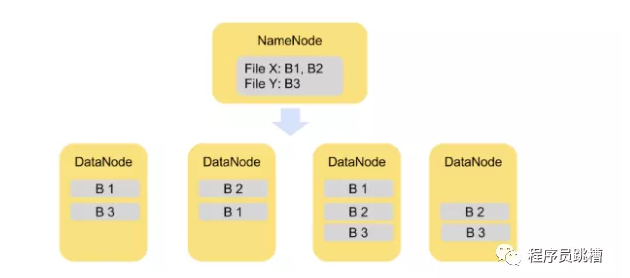
HDFS将每个文件拆分为一系列较小但仍然较大的块(默认块大小等于128MB - 较大的块意味着更少的磁盘搜索操作,从而导致更大的吞吐量)。每个块都冗余地存储在三个DataNode上以实现容错(每个文件的副本数量是可配置的)。
图2说明了将文件拆分为块的概念。文件X被分成块B1和B2,文件Y仅包括一个块B3。所有块都在群集中复制两次。
与HDFS交互
HDFS提供了一个简单的POSIX类接口来处理数据。您使用hdfs dfs命令执行文件系统操作。
热门提示:要开始使用Hadoop,您不必完成设置整个群集的过程。Hadoop可以在一台机器上以所谓的伪分布式模式运行。您可以下载已安装所有HDFS组件的沙盒虚拟机,并立即开始使用Hadoop!只需按照以下链接之一:
http://www.mapr.com/products/mapr-sandbox-hadoop
http://hortonworks.com/products/hortonworks-sandbox/#install
https://www.cloudera.com/downloads/quickstart_vms/5-12.html
以下步骤说明了HDFS用户可以执行的典型操作:
列出主目录的内容:
$ hdfs dfs -ls /user/adam
将文件从本地文件系统上传到HDFS:
$ hdfs dfs -put songs.txt /user/adam
从HDFS读取文件的内容:
$ hdfs dfs -cat /user/adam/songs.txt
更改文件的权限:
$ hdfs dfs -chmod 700 /user/adam/songs.txt
将文件的复制因子设置为4:
$ hdfs dfs -setrep -w 4 /user/adam/songs.txt
检查文件的大小:
`$ hdfs dfs -du -h /user/adam/songs.txt
在主目录中创建一个子目录。请注意,相对路径始终引用执行命令的用户的主目录。HDFS上没有“当前”目录的概念(换句话说,没有相当于“cd”命令):
$ hdfs dfs -mkdir songs
将文件移动到新创建的子目录:
$ hdfs dfs -mv songs.txt songs/
从HDFS中删除目录:
$ hdfs dfs -rm -r songs
注意:已删除的文件和目录将移至回收站(HDFS上主目录中的.Trash)并保留一天,直到它们被永久删除。您只需将它们从.Trash复制或移动到原始位置即可恢复它们。
热门提示:您可以在不使用任何参数的情况下键入hdfs dfs,以获取可用命令的完整列表。
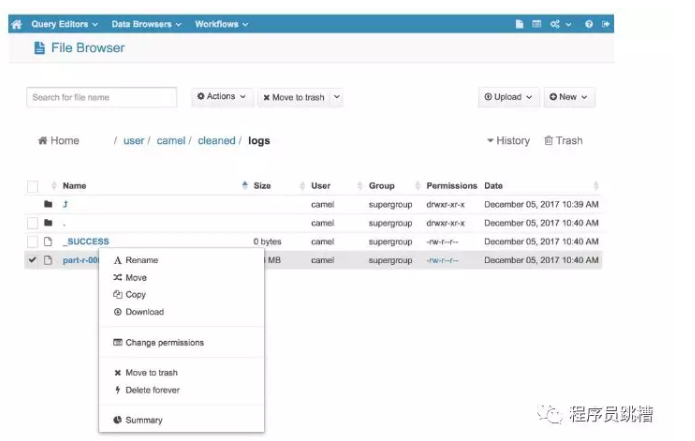
如果您更喜欢使用图形界面与HDFS交互,您可以查看免费和开源的HUE(Hadoop用户体验)。它包含一个方便的“文件浏览器”组件,允许您浏览HDFS文件和目录并执行基本操作。
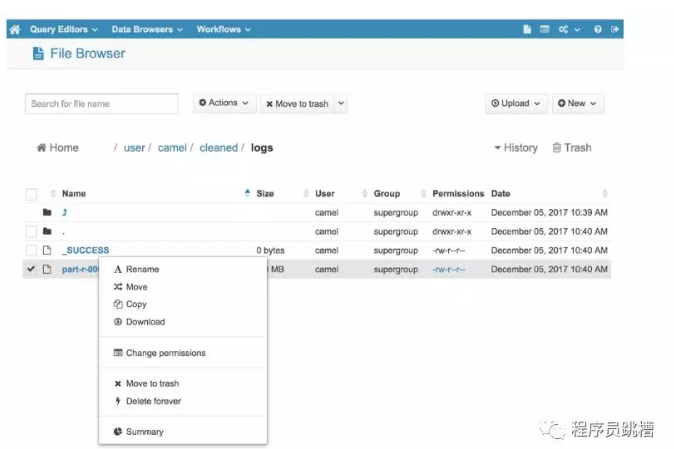
您还可以使用HUE通过“上传”按钮直接从计算机将文件上传到HDFS。
YARN(Yet Another Resource Negotiator)负责管理Hadoop集群上的资源,并支持运行处理存储在HDFS上的数据的各种分布式应用程序。
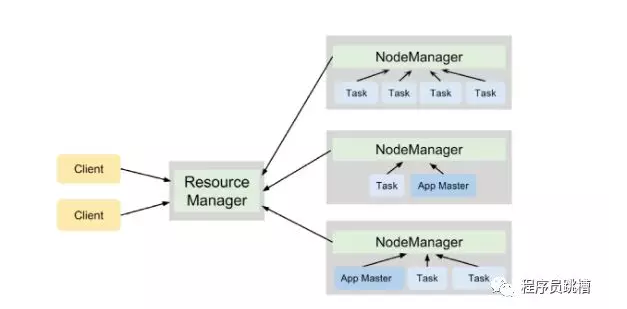
与HDFS类似,YARN遵循主从设计,ResourceManager进程充当主设备,多个NodeManager充当工作者。他们有以下责任:
的ResourceManager
跟踪实时NodeManagers以及群集中每台服务器上的可用计算资源量。
为应用程序分配可用资源。
监视Hadoop集群上所有应用程序的执行情况。
节点管理器
管理Hadoop集群中单个节点上的计算资源(RAM和CPU)。
运行各种应用程序的任务,并强制它们在指定的计算资源的限制范围内。
YARN以资源容器的形式将集群资源分配给各种应用程序,资源容器表示RAM量和CPU核心数量的组合。
在YARN群集上执行的每个应用程序都有自己的ApplicationMaster进程。在群集上调度应用程序并协调此应用程序中所有任务的执行时,此过程开始。
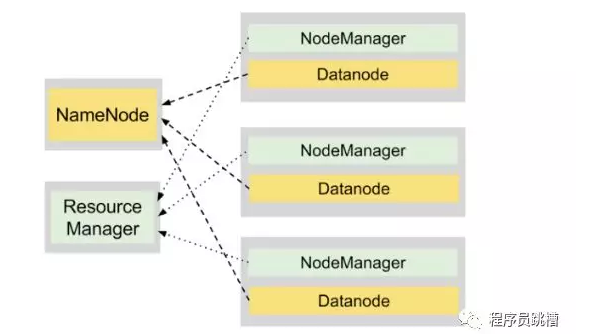
图3说明了YARN守护程序在运行两个应用程序的4节点集群上的合作,这些应用程序总共产生了7个任务。
Hadoop = HDFS + YARN
在同一群集上运行的HDFS和YARN守护程序为我们提供了一个用于存储和处理大型数据集的强大平台。
DataNode和NodeManager进程在同一节点上并置以启用数据位置。这种设计使得能够在存储数据的机器上执行计算,从而最小化通过网络发送大块数据的必要性,这导致更快的执行时间。
YARN应用程序
YARN只是一个资源管理器,它知道如何将分布式计算资源分配给在Hadoop集群上运行的各种应用程序。换句话说,YARN本身不提供任何可以分析HDFS中数据的处理逻辑。因此,必须将各种处理框架与YARN集成(通过提供ApplicationMaster的特定实现)以在Hadoop集群上运行并处理来自HDFS的数据。
下面列出了最流行的分布式计算框架的简短描述,这些框架可以在由YARN支持的Hadoop集群上运行。
MapReduce - Hadoop的传统和最古老的处理框架,将计算表示为一系列map和reduce任务。它目前正被Spark或Flink等更快的引擎所取代。
Apache Spark - 一种用于大规模数据处理的快速通用引擎,可通过在内存中缓存数据来优化计算(后面部分将详细介绍)。
Apache Flink - 高吞吐量,低延迟的批处理和流处理引擎。它以其强大的实时处理大数据流的能力而着称。您可以在这篇全面的文章中找到Spark和Flink之间的差异:https://dzone.com/articles/apache-hadoop-vs-apache-spark
Apache Tez - 一个旨在加快Hive执行SQL查询的引擎。它可以在Hortonworks数据平台上获得,它将MapReduce替换为Hive的执行引擎。
监控YARN应用程序
可以使用ResourceManager WebUI跟踪在Hadoop集群上运行的所有应用程序的执行,默认情况下,该管理程序在端口8088上公开。
对于每个应用程序,您都可以阅读一些重要信息。
如果单击“ID”列中的条目,您将获得有关所选应用程序执行的更详细的指标和统计信息。
热门提示:使用ResourceManager WebUI,您可以检查可用于处理的RAM总量和CPU核心数以及当前的Hadoop集群负载。查看页面顶部的“群集指标”。
————————————————————
推荐阅读:
【大数据】了解Hadoop框架的基础知识的更多相关文章
- 大数据和hadoop的一些基础知识
一.前言 大数据这个概念不用我提大家也听过很多了,前几年各种公开论坛.会议等场合言必及大数据,说出来显得很时髦似的.有意思的是最近拥有这个待遇的名词是“人工智能/AI”,当然这是后话. 众所周知,大数 ...
- 大数据之hadoop框架知识
https://blog.csdn.net/zytbft/article/details/79285500
- 大数据和Hadoop生态圈
大数据和Hadoop生态圈 一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop ...
- Hadoop专业解决方案-第1章 大数据和Hadoop生态圈
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop生态圈小组已经翻译完成,在此 ...
- 细细品味大数据--初识hadoop
初识hadoop 前言 之前在学校的时候一直就想学习大数据方面的技术,包括hadoop和机器学习啊什么的,但是归根结底就是因为自己太懒了,导致没有坚持多长时间,加上一直为offer做准备,所以当时重心 ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- 大数据和hadoop有什么关系?
本文资料来自百度文库相关文档 Hadoop,Spark和Storm是目前最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Storm常用于 ...
- 大数据除了Hadoop还有哪些常用的工具?
大数据除了Hadoop还有哪些常用的工具? 1.Hadoop大数据生态平台Hadoop 是一个能够对大量数据进行分布式处理的软件框架.但是 Hadoop 是以一种可靠.高效.可伸缩的方式进行处理的.H ...
随机推荐
- 基础select语句详解
在数据库操作语句中,使用最频繁,也被认为最重要的是 SELECT 查询语句.我们已经在不少地方用到了 SELECT * FROM table_name; 这条语句用于查看一张表中的所有内容. 而 SE ...
- Swift与C++混编 OpenCV初体验 图片打码~
OpenCV初体验,给图片打码 提到OpenCV,相信大多数人都听说过,应用领域非常广泛,使用C++开发,天生具有跨平台的优势,我们学习一次,就可以在各个平台使用,这个还是很具有诱惑力的.本文主要记录 ...
- 微信小程序ios点击状态栏返回顶部不好使
最近做了一款微信小程序,各方面感觉都很完美(萝卜一直这么自信),今天设计总监告诉我你的小程序怎么返回顶部不好使呀,吓得我赶紧拿手机试试,没毛病啊,我手机(苦逼的安卓机)上点两下就回去了呀,遂去找他理论 ...
- 【二代示波器教程】第14章 uCOS-III操作系统版本二代示波器实现
第14章 uCOS-III操作系统版本二代示波器实现 本章教程为大家讲解uCOS-III操作系统版本的二代示波器实现.主要讲解RTOS设计框架,即各个任务实现的功能,任务间的通信方案选择,任 ...
- Javascript高级编程学习笔记(87)—— Canvas(4)绘制路径
绘制路径 2D上下文支持许多在画布上绘制路径的方法 通过路径可以创造出复杂的形状和线条,要绘制路径首先必须调用beginPath()方法,表示开始绘制路径 然后再通过下列的方法绘制路径: arc(x, ...
- JAVA设计模式—观察者模式和Reactor反应堆模式
被观察者(主题)接口 定义主题对象接口 /**抽象主题角色: 这个主题对象在状态上发生变化时,会通知所有观察者对象 也叫事件对象 */ public interface Subject { //增加一 ...
- Oracle数据库备份及还原
Oracle数据库备份 1:找到Oracle安装路径我的就是默认C盘 C:\app\wdjqc\admin\orcl\adump 2:执行文件:back.bat 文件内容如下: @echo off ...
- [Swift]LeetCode170.两数之和III - 数据结构设计 $ Two Sum III - Data structure design
Design and implement a TwoSum class. It should support the following operations:add and find. add - ...
- [Swift]LeetCode172. 阶乘后的零 | Factorial Trailing Zeroes
Given an integer n, return the number of trailing zeroes in n!. Example 1: Input: 3 Output: 0 Explan ...
- [Swift]LeetCode673. 最长递增子序列的个数 | Number of Longest Increasing Subsequence
Given an unsorted array of integers, find the number of longest increasing subsequence. Example 1: I ...