单链表ADT
本博客第一篇学术性博客,所以还是写点什么东西;
首先这篇博客以及以后的博客中的代码尽量百分之90是自己写过的;
可能有部分图片和代码是我认为别人更好的故摘抄下来,
本人三观正确,所以一定会表明来源;
—————————华丽的分割线——————————————
参考书籍——《数据结构于算法分析(C语言描述)》
链表是最基本的数据结构之一,当我们学习完C语言后就会涉及到一点点链表的知识;
本篇博客主要记录链表的一些简单思路以及它的一些主要例程;
按照c的约定我们先将链表的函数原型以及一些typedef定义都放在一个Lish.h头文件里
List.h:
#ifndef LIST_H
#define LIST_H typedef char ElementType; struct Node;
typedef struct Node *PtrToNode;
typedef PtrToNode Position;
typedef PtrToNode List; List MakeEmpty(List L);
int IsLast(Position P, List L);
int IsEmpty(List L);
Position FindPrevious(List L, ElementType x);
Position Find(List L, ElementType x);
void Delete(List L, ElementType x);
void Insert(List L, ElementType x, Position P);
void InsertToTail(List L, ElementType x);
void InsertToHead(List L, ElementType x);
void PrintList(List L);
void DeleteList(List L);
void Reverse(List L); #endif
本篇中的代码所建立的链表都是带有头节点的链表,而使用表头属于个人习惯,我们不再这里做深究
下面的函数尽量满足ADT的想法,没有写CreateList函数是因为该函数功能是对一个已经创建好了的链表的操作而不是一个纯练习的文件,这是个人对此的理解如有更好的解释请大方私信我!谢谢!
添加了两个Insert函数分别是InsertToTail和InsertToHead,从字面上来看就是尾插法和头插法,考虑到M.A.W的Insert例程需要传入位置P,而此举往往很麻烦,于是加上了一个直接插入到尾部和头部的函数
使整个ADT的想法更加完善。
操作图示:
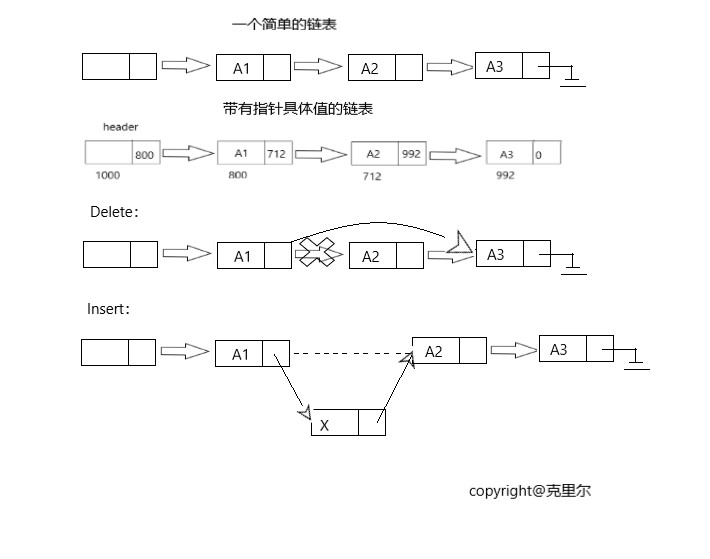
这里主要将链表的一些主要例程写出来,并将这些函数封装在一个.c文件里增强复用性!
SingleLinkedList.c:
#include"List.h"
#include<stdio.h>
#include<stdlib.h> struct Node{
ElementType Element;
PtrToNode Next;
}; List MakeEmpty(List L)
{
if(NULL != L)
{
L->Next = NULL;
}
return L;
} int IsLast(Position P, List L)//L is unused
{
return P->Next == NULL;
} int IsEmpty(List L)
{
return L->Next == NULL;
} Position FindPrevious(List L, ElementType x)
{
Position P;
P = L;
while(P->Next && P->Next->Element != x)
P = P->Next;
return P;
} Position Find(List L, ElementType x)
{
Position P;
P = L->Next;
while(P && P->Element != x)
P = P->Next;
return P;
} void Delete(List L, ElementType x)
{
Position Pre, Tmpcell; Pre = FindPrevious(L, x);//we need find the previous of deleted element
if(!IsLast(Pre, L))
{
Tmpcell = Pre->Next;
Pre->Next = Tmpcell->Next;
free(Tmpcell);
}
} //we insert the element after the position p
void Insert(List L, ElementType x, Position P)
{
Position NewCell;
TmpCell = (List)malloc(sizeof(struct Node));
if(NULL == NewCell)
printf("No space for allocation!!");
else
{
NewCell->Element = x;
NewCell->Next = P->Next;
P->Next = NewCell;
}
}
//插入链表尾部(尾插法)
void InsertToTail(List L, ElementType x)
{
Position Last, NewCell;
Last = L;
/*遍历链表找到最后一个结点*/
while(NULL != Last->Next)
Last = Last->Next;
Insert(L, x, Last);
}
//插入链表头部(头插法)
void InsertToHead(List L, ElementType x)
{
Insert(L, x, L);
} void PrintList(List L)
{
PtrToNode Tmp;
Tmp = L->Next;
while(Tmp->Next)
{
printf("%c-", Tmp->Element);
Tmp = Tmp->Next;
}
printf("%c\n", Tmp->Element);
} void DeleteList(List L)
{
Position Tmp, P;
P = L->Next;
L->Next = NULL;
while(P != NULL)
{
Tmp = P->Next;
free(P);
P = Tmp;
}
free(L);
} void Reverse(List L)
{
Position CurrentPos, NextPos, PreviousPos; CurrentPos = L->Next;//当前单链表的第一个节点
PreviousPos = NULL;//指向新链表的第一个节点,假设开始为空
while(CurrentPos != NULL)
{
NextPos = CurrentPos->Next;//取得当前节点的下一个节点位置
CurrentPos->Next = PreviousPos;//当前节点连接成新的链表
PreviousPos = CurrentPos;
CurrentPos = NextPos;//遍历到下一个节点
}
L->Next = PreviousPos;//哑元节点连接新链表的头节点
}
//与上述思想差不多,主要在返回上
/*Asumming(假如)is no header and L is not empty*/
//List Reverse(List L)
//{
// Position CurrentPos, NextPos, PreviousPos;
//
// CurrentPos = L;
// PreviousPos = NULL;
// while(CurrentPos != NULL)
// {
// NextPos = CurrentPos->Next;
// CurrentPos->Next = PreviousPos;
// PreviousPos = CurrentPos;
// CurrentPos = NextPos;
// }
// return PreviousPos;
//}
//下面是复杂记忆写法
//void Reverse(List L)//含有头节点
//{
// Position Tmp, P;
// Tmp = L->Next;
// L->Next = NULL;
// while(Tmp != NULL)
// {
// P = Tmp->Next;
// Tmp->Next = L->Next;
// L->Next = Tmp;
// Tmp = P;
// }
//}
//List Reverse(List L)//不含头节点
//{
// PtrToNode Tmp, P;
// P = L;
// L = NULL;
// while(P != NULL){
// Tmp = P->Next;
// P->Next = L;
// L = P;
// P = Tmp;
// }
// return L;
//}
下面贴出自己写的一组测试代码
Test.c:
#include"List.h"
#include<stdio.h>
#include<stdlib.h> int main()
{
ElementType Elem, De, PreElem, Ins;
Position Tmp;
List L;
L = (List)malloc(sizeof(struct Node));
if(NULL == L)
printf("Allocation failure!!!");
L = MakeEmpty(L);
printf("Please enter the element until the end of '#':");
while((Elem = getchar()) != '#')
{
InsertToTail(L, Elem);
}
getchar();
PrintList(L);
//删除并输出
printf("Please enter the element you want to delete:");
scanf("%c", &De);
getchar(); Delete(L, De);
PrintList(L);
//插入并输出
printf("After which element do you want to insert:");
scanf("%c", &PreElem);
getchar();
Tmp = Find(L, PreElem); printf("What element do you want to insert:");
scanf("%c", &Ins);
getchar(); Insert(L, Ins, Tmp);
PrintList(L);
//将整个表倒置
Reverse(L);
printf("Now the reverse list is:");
PrintList(L);
//删除整个表
DeleteList(L);
return ;
}

单链表ADT的更多相关文章
- 数据结构:DHUOJ 单链表ADT模板应用算法设计:长整数加法运算(使用单链表存储计算结果)
单链表ADT模板应用算法设计:长整数加法运算(使用单链表存储计算结果) 时间限制: 1S类别: DS:线性表->线性表应用 题目描述: 输入范例: -5345646757684654765867 ...
- [C++]数据结构:线性表之(单)链表
一 (单)链表 ADT + Status InitList(LinkList &L) 初始化(单)链表 + void printList(LinkList L) 遍历(单)链表 + int L ...
- 单链表 C++ 实现 - 含虚拟头节点
本文例程下载链接:ListDemo 链表 vs 数组 链表和数组的最大区别在于链表不支持随机访问,不能像数组那样对任意一个(索引)位置的元素进行访问,而需要从头节点开始,一个一个往后访问直到查找到目标 ...
- 动态单链表的传统存储方式和10种常见操作-C语言实现
顺序线性表的优点:方便存取(随机的),特点是物理位置和逻辑为主都是连续的(相邻).但是也有不足,比如:前面的插入和删除算法,需要移动大量元素,浪费时间,那么链式线性表 (简称链表) 就能解决这个问题. ...
- python数据结构与算法之单链表
表的抽象数据类型 ADT list: #一个表的抽象数据类型 List(self) #表的构造操作,创建一个空表 is_empty ...
- JAVA实现具有迭代器的线性表(单链表)
一,迭代器的基本知识: 1,为什么要用迭代器?(迭代:即对每一个元素进行一次“问候”) 比如说,我们定义了一个ADT(抽象数据类型),作为ADT的一种实现,如单链表.而单链表的基本操作中,大部分需要用 ...
- 单链表-Python实现-jupyter->markdown 格式测试
单链表引入 顺序表 理解Python变量的本质: 变量存储的不是值,是值的地址 理解Python的 "="表示的是指向关系 案例: 交换a,b的值, a=10, b=20 a, b ...
- C++泛化单链表
泛型单链表 单链表将每个数据分为节点,每个节点存储数据和指向下一个节点的指针.这样数据就不用在内存中使用连续的存储空间,有更大的灵活性. 这里将单链表分为节点类(Node)和链表类(singleLin ...
- 时间复杂度分别为 O(n)和 O(1)的删除单链表结点的方法
有一个单链表,提供了头指针和一个结点指针,设计一个函数,在 O(1)时间内删除该结点指针指向的结点. 众所周知,链表无法随机存储,只能从头到尾去遍历整个链表,遇到目标节点之后删除之,这是最常规的思路和 ...
随机推荐
- Tomcat每日报错
本次针对tomcat端口占用所产生的8080:8009:8000报错 1.打开CMD命令提示符(win+R). 2.输入指令netstat str -ano|findstr 8080(8080这里可以 ...
- Vue中使用Cropper.js裁剪图片
Cropper.js是一款很好用的图片裁剪工具,可以对图片的尺寸.宽高比进行裁剪,满足诸如裁剪头像上传.商品图片编辑之类的需求. github: https://github.com/fengyuan ...
- anaconda中安装mmdetection
1.新建conda环境(有则跳过) conda create -n py36 python=3.6 && source activate py36 2.安装pytorch ...
- word模板导出的几种方式:第一种:占位符替换模板导出(只适用于word中含有表格形式的)
1.占位符替换模板导出(只适用于word中含有表格形式的): /// <summary> /// 使用替换模板进行到处word文件 /// </summary> public ...
- 271. 杨老师的照相排列【线性DP】
杨老师希望给他的班级拍一张合照. 学生们将站成左端对齐的多排,靠后的排站的人数不能少于靠前的排. 例如,12名学生(从后向前)可以排列成每排5,3,3,1人,如下所示: X X X X X X X X ...
- P2495 [SDOI2011]消耗战
思路 虚树上DP 虚树相当于一颗包含了所有询问的关键点信息的树,包含的所有点只有询问点和它们的LCA,所以点数是\(2k\)级别的,这样的话复杂度就是\(O(\sum k)\),复杂度就对了 虚树重点 ...
- jQuery_$方法、属性、点击切换
jQuery_$方法 1.$.each():遍历数组或对象中的数据 2.$.trim():去除字符串两边的空格 3.$.type(obj):得到数据的类型 4.$.isArray(obj):判断是否为 ...
- 【HNOI 2018】转盘
Problem Description 一次小 \(G\) 和小 \(H\) 原本准备去聚餐,但由于太麻烦了于是题面简化如下: 一个转盘上有摆成一圈的 \(n\) 个物品(编号 \(1\) 至 \(n ...
- ssm框架中文请求乱码get
<bean id="utf8Charset" class="java.nio.charset.Charset" factory-method=" ...
- 网络流(dinic算法)
网络最大流(dinic) 模型 在一张图中,给定一个源点s,给定汇点t,点之间有一些水管,每条水管有一个容量,经过此水管的水流最大不超过容量,问最大能有多少水从s流到t(s有无限多的水). 解法 di ...