【Spark篇】---Spark中内存管理和Shuffle参数调优
一、前述
Spark内存管理
Spark执行应用程序时,Spark集群会启动Driver和Executor两种JVM进程,Driver负责创建SparkContext上下文,提交任务,task的分发等。Executor负责task的计算任务,并将结果返回给Driver。同时需要为需要持久化的RDD提供储存。Driver端的内存管理比较简单,这里所说的Spark内存管理针对Executor端的内存管理。
Spark内存管理分为静态内存管理和统一内存管理,Spark1.6之前使用的是静态内存管理,Spark1.6之后引入了统一内存管理。
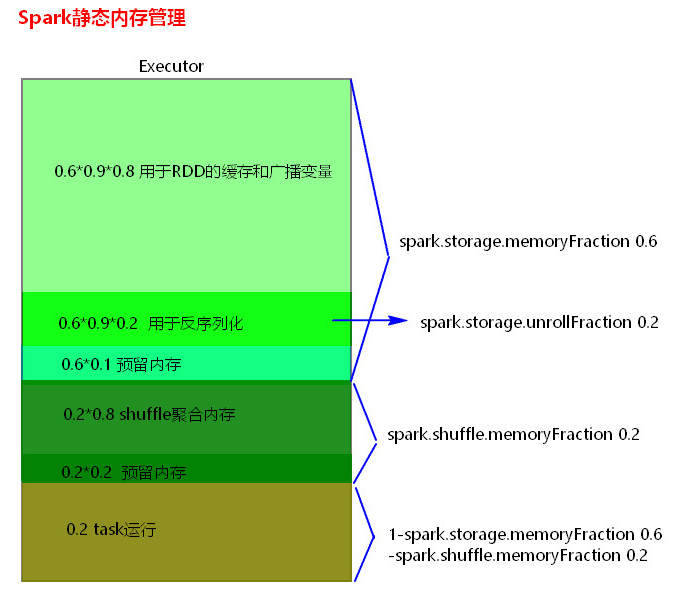
静态内存管理中存储内存、执行内存和其他内存的大小在 Spark 应用程序运行期间均为固定的,但用户可以应用程序启动前进行配置。
统一内存管理与静态内存管理的区别在于储存内存和执行内存共享同一块空间,可以互相借用对方的空间。
Spark1.6以上版本默认使用的是统一内存管理,可以通过参数spark.memory.useLegacyMode 设置为true(默认为false)使用静态内存管理。
二、具体细节
1、静态内存管理分布图
2、统一内存管理分布图

3、reduce 中OOM如何处理?
拉取数据的时候一次都放不下,放下的话可以溢写磁盘
1) 减少每次拉取的数据量
2) 提高shuffle聚合的内存比例
3) 提高Excutor的总内存
4、Shuffle调优
spark.shuffle.file.buffer
默认值:32k
参数说明:该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k,一定是成倍的增加),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.reducer.maxSizeInFlight
默认值:48m
参数说明:该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。
调优建议:如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.shuffle.io.maxRetries
默认值:3
参数说明:shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。
调优建议:对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。
shuffle file not find taskScheduler不负责重试task,由DAGScheduler负责重试stage
spark.shuffle.io.retryWait
默认值:5s
参数说明:具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是5s。
调优建议:建议加大间隔时长(比如60s),以增加shuffle操作的稳定性。
spark.shuffle.memoryFraction
默认值:0.2
参数说明:该参数代表了Executor内存中,分配给shuffle read task进行聚合操作的内存比例,默认是20%。
调优建议:在资源参数调优中讲解过这个参数。如果内存充足,而且很少使用持久化操作,建议调高这个比例,给shuffle read的聚合操作更多内存,以避免由于内存不足导致聚合过程中频繁读写磁盘。在实践中发现,合理调节该参数可以将性能提升10%左右。
spark.shuffle.manager
默认值:sort|hash
参数说明:该参数用于设置ShuffleManager的类型。Spark 1.5以后,有三个可选项:hash、sort和tungsten-sort。HashShuffleManager是Spark 1.2以前的默认选项,但是Spark 1.2以及之后的版本默认都是SortShuffleManager了。tungsten-sort与sort类似,但是使用了tungsten计划中的堆外内存管理机制,内存使用效率更高。
调优建议:由于SortShuffleManager默认会对数据进行排序,因此如果你的业务逻辑中需要该排序机制的话,则使用默认的SortShuffleManager就可以;而如果你的业务逻辑不需要对数据进行排序,那么建议参考后面的几个参数调优,通过bypass机制或优化的HashShuffleManager来避免排序操作,同时提供较好的磁盘读写性能。这里要注意的是,tungsten-sort要慎用,因为之前发现了一些相应的bug。
spark.shuffle.sort.bypassMergeThreshold
默认值:200
参数说明:当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值(默认是200),则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。
调优建议:当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量。那么此时就会自动启用bypass机制,map-side就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
spark.shuffle.consolidateFiles
默认值:false
参数说明:如果使用HashShuffleManager,该参数有效。如果设置为true,那么就会开启consolidate机制,会大幅度合并shuffle write的输出文件,对于shuffle read task数量特别多的情况下,这种方法可以极大地减少磁盘IO开销,提升性能。
调优建议:如果的确不需要SortShuffleManager的排序机制,那么除了使用bypass机制,还可以尝试将spark.shffle.manager参数手动指定为hash,使用HashShuffleManager,同时开启consolidate机制。在实践中尝试过,发现其性能比开启了bypass机制的SortShuffleManager要高出10%~30%。
5、Shuffle调优设置
SparkShuffle调优配置项如何使用?
1) 在代码中,不推荐使用,硬编码。
new SparkConf().set(“spark.shuffle.file.buffer”,”64”)
2) 在提交spark任务的时候,推荐使用。
spark-submit --conf spark.shuffle.file.buffer=64 –conf ….
3) 在conf下的spark-default.conf配置文件中,不推荐,因为是写死后所有应用程序都要用。
【Spark篇】---Spark中内存管理和Shuffle参数调优的更多相关文章
- Spark Shuffle原理、Shuffle操作问题解决和参数调优
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark现在的SortShuff ...
- spark 资源参数调优
资源参数调优 了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了.所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使 ...
- spark参数调优
摘要 1.num-executors 2.executor-memory 3.executor-cores 4.driver-memory 5.spark.default.parallelism 6. ...
- spark submit参数调优
在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都可以在spark-submit命令中作为参数设置.很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置 ...
- 【Spark调优】Shuffle原理理解与参数调优
[生产实践经验] 生产实践中的切身体会是:影响Spark性能的大BOSS就是shuffle,抓住并解决shuffle这个主要原因,事半功倍. [Shuffle原理学习笔记] 1.未经优化的HashSh ...
- 【Spark调优】内存模型与参数调优
[Spark内存模型] Spark在一个executor中的内存分为3块:storage内存.execution内存.other内存. 1. storage内存:存储broadcast,cache,p ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优
摘抄自https://tech.meituan.com/spark-tuning-pro.html 一.概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘I ...
- Spark学习之路 (十)SparkCore的调优之Shuffle调优[转]
概述 大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO.序列化.网络数据传输等操作.因此,如果要让作业的性能更上一层楼,就有必要对shuffle过程进行调优 ...
- Spark面试题(八)——Spark的Shuffle配置调优
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
随机推荐
- PHP7.* AES的加密解密
之前写过一篇: PHP AES的加密解密-----[弃用] 使用的是php5.*之前的mcrypt_decrypt 函数,该函数已经在php7.1后弃用了,上马的是openssl的openssl_en ...
- C# Entity To Json
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.Da ...
- disconf使用小结
disconf使用小结 目前我们公司用的分布式配置中心是disconf,对于普通的spring项目集成还是比较方便,主要功能点分布式配置还有配置的动态更新通知 安装disconf服务端 参考地址htt ...
- python正则表达式判断素数【厉害了】
参考: https://www.cnblogs.com/imjustice/p/check_prime_by_using_regular_expression.html for i in range( ...
- 2018-2019 20165235 网络对抗技术 Exp0:kali的安装
2018-2019 20165235 网络对抗技术 Exp0:kali的安装 安装kali 在官网上https://www.kali.org/下载kali 下载之后进行解压 打开VMware-> ...
- linux学习--2019-04-22
1.写命令,vi编辑器 1)vi 文件名 2) 按 ‘i’ 进入编辑模式 3)编写完成后,按Esc,然后输入 “:wq” 推出编辑.(“q!”不存盘,强制退出vi) 2.命令补全 “Tab” 3.获取 ...
- Linux-硬件
1.服务器 计算节点服务器-用于后台逻辑运算,所以cpu,磁盘读写性能要求较高 web服务器-用于用户请求访问一些页面,如果高并发,磁盘读写性能要好,可以使用raid0或raid1或raid5技术(r ...
- 【web安全】-- springboot实现两次MD5加密
一.为什么要做两次MD5 客户端MD5:HTTP在网络上是使用明文传输,用户输入的明文密码直接在网络上传输太危险.所以,在客户端先进行一次MD5(明文+固定盐). 服务端:服务端接受到后,也不是直接写 ...
- 输出九九乘法表(Python、Java、C、C++、JavaScript)
最近在学python的过程中,接触到了循环的知识,以及这个案例,于是写了下!感觉还不错,然后就用其它几种语言也试了下!! 接下来,就跟大家分享下实现方法!! 实现输出九九乘法表,主要用到的是循环的知识 ...
- 蓝桥杯刷题,第四界省赛B组
题头,本内容的题目和部分内容均来自博客:https://blog.csdn.net/ryo_218/article/details/79704030 ,在此感谢. 1. 题目标题:高斯日记大数学家高斯 ...