Spark编程模型(博主推荐)
福利 => 每天都推送
不多说,直接上干货!
从博客分为Spark编程模型(上)、Spark编程模型(中)和Spark编程模型(下)。
一、Spark编程模型(上)
从Hadoop MR到Spark
回顾hadoop—mapreduce计算过程
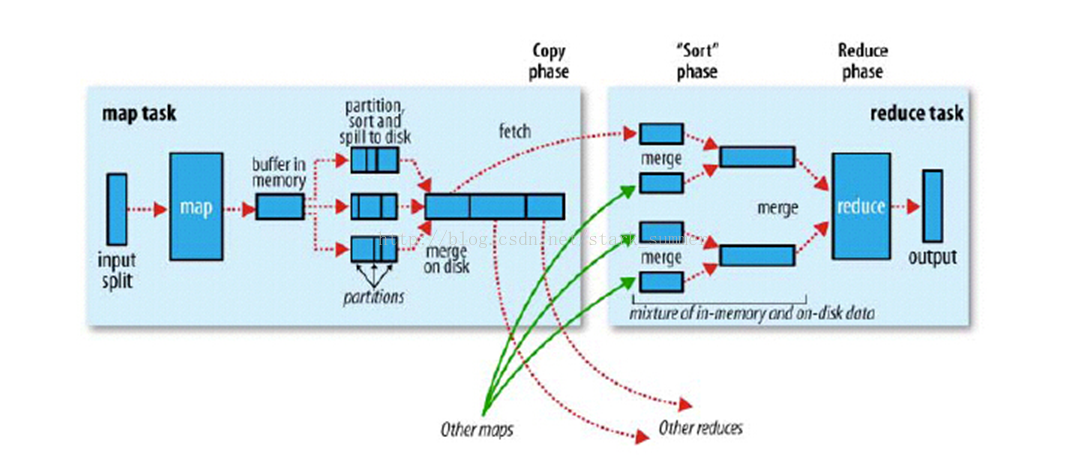
MR VS Spark

Spark编程模型
核心概念

注意:对比mr里的概念来学习。
这些概念,大家一定要好好理解!!!
Spark Application的组成
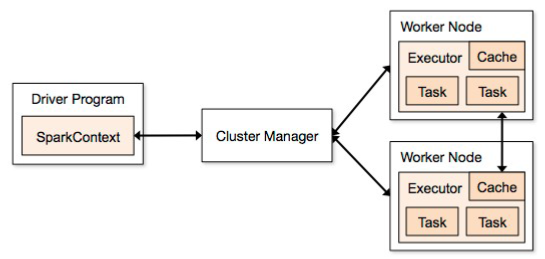
其中,Driver Program是运行main函数并且新建SparkContext的程序
Cluster Manager是在集群上获取资源的外部服务(例如: standalonde、Mesos、Yarn)
Worker Node是集群中任何运行应用代码的节点
Executor是在一个worker node上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或磁盘上。每个应用都有各自独立的executors。
Task是被送到某个executor上的工作单元
Spark应用程序的组成
(1)Driver
(2)Executor
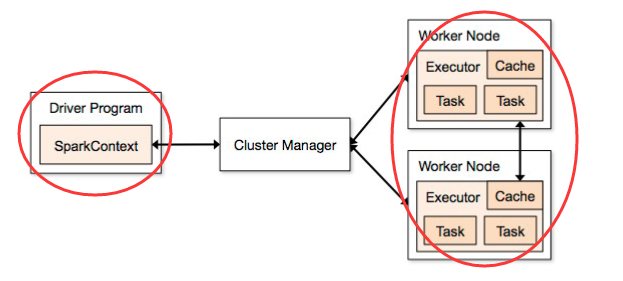
注意:对照helloworld来思考
Spark Application基本概念

Spark Application编程模型
Spark 应用程序编程模型

– Driver Program ( SparkContext )
– Executor ( RDD 操作)
(1)输入Base-> RDD
(2)Transformation RDD->RDD
(3)Action RDD->driver or Base
(4)缓存 Persist or cache()
– 共享变量
(1)broadcast variables(广播变量)
(2)accumulators(累加器)
回顾Spark Hello World
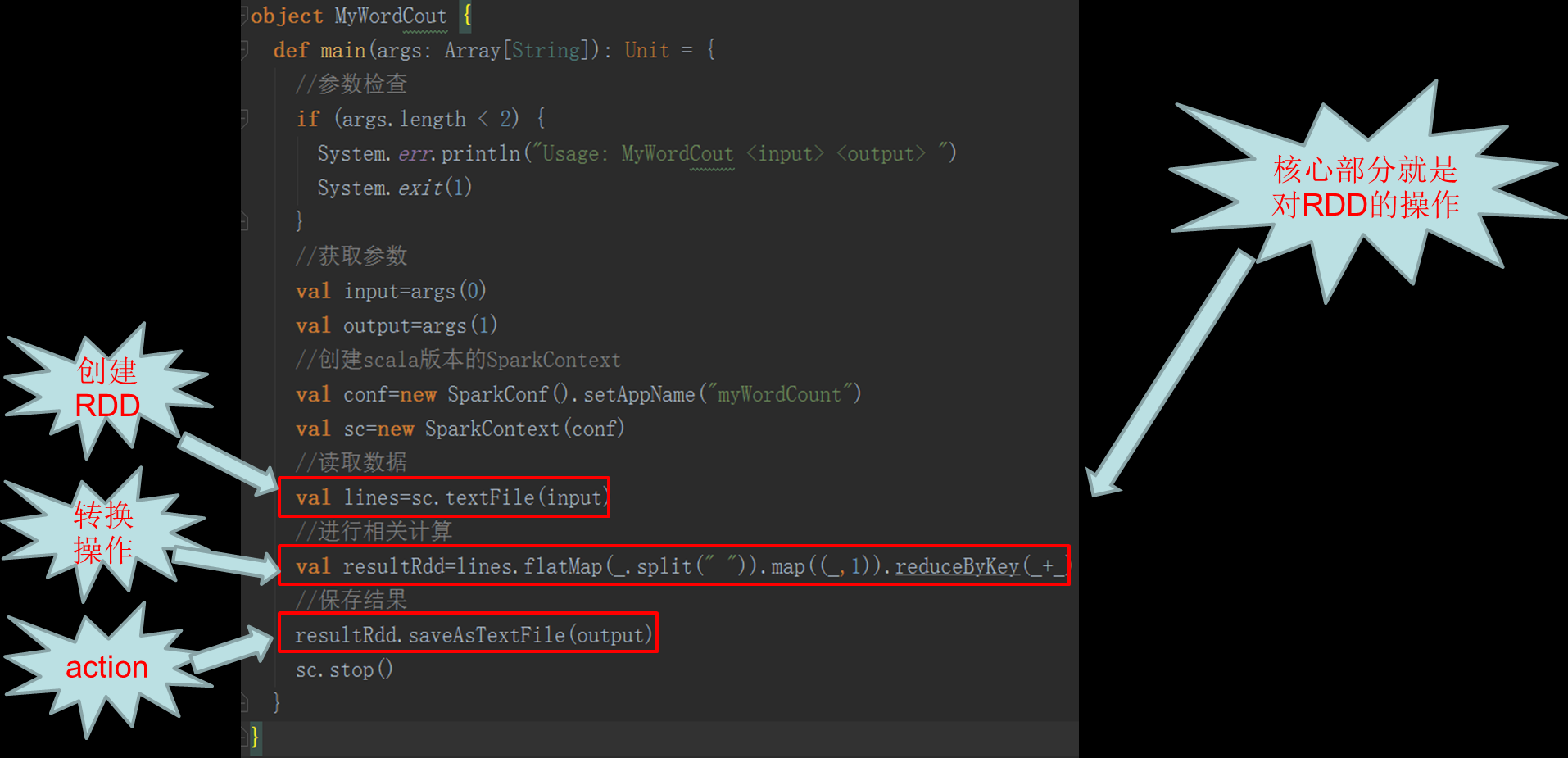
初识RDD
什么是RDD
定义:Resilient distributed datasets (RDD), an efficient, general-purpose and fault-tolerant abstraction for sharing data in cluster applications.
RDD 是只读的。
RDD 是分区记录的集合。
RDD 是容错的。--- lineage
RDD 是高效的。
RDD 不需要物化。---物化:进行实际的变换并最终写入稳定的存储器上
RDD 可以缓存的。---课指定缓存级别
RDD是spark的核心,也是整个spark的架构基础,RDD是弹性分布式集合(Resilient Distributed Datasets)的简称,是分布式只读且已分区集合对象。这些集合是弹性的,如果数据集一部分丢失,则可以对它们进行重建。
RDD接口
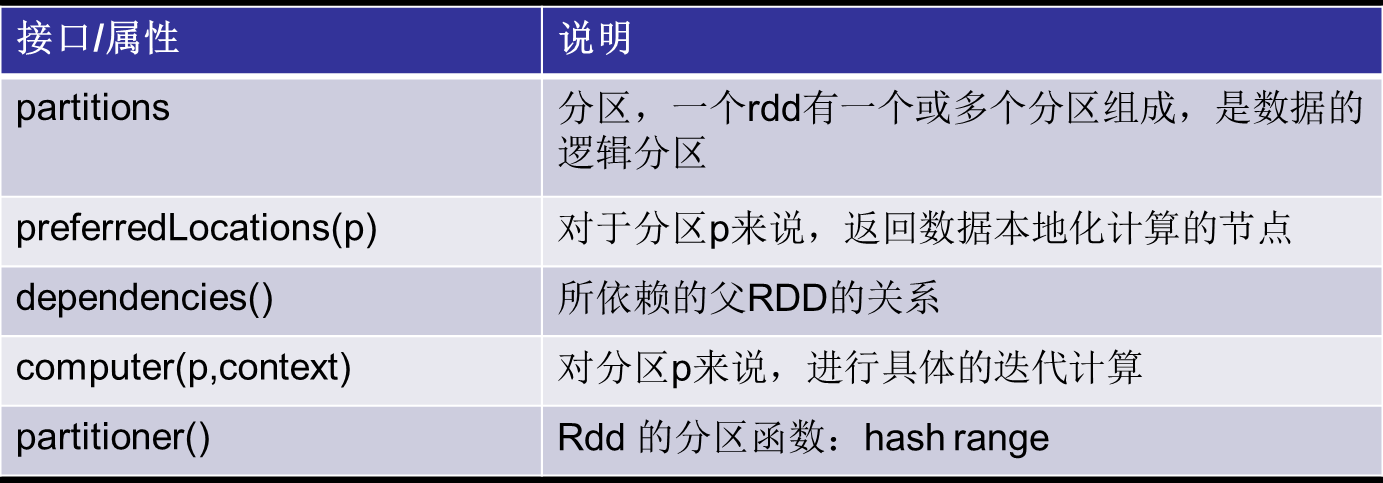
RDD的本质特征

RDD--partitions
Spark中将1~100的数组转换为rdd

通过第15行的size获得rdd的partition的个数,此处创建rdd显式指定定分区个数2,默认数值是这个程序所分配到的资源的cpu核的个数
RDD-preferredLocations
返回此RDD的一个partition的数据块信息,如果一个数据块(block)有多个备份在返回所有备份的location地址信息
主机ip或域名
作用:spark在进行任务调度室尽可能根据block的地址做到本地计算
RDD-dependencies
RDD之间的依赖关系分为两类:
(1)窄依赖
每个父RDD的分区都至多被一个子RDD的分区使用,即为OneToOneDependecies;
(2)宽依赖
多个子RDD的分区依赖一个父RDD的分区,即为ShuffleDependency 。例如,map操作是一种窄依赖,而join操作是一种宽依赖(除非父RDD已经基于Hash策略被划分过了,co-partitioned)
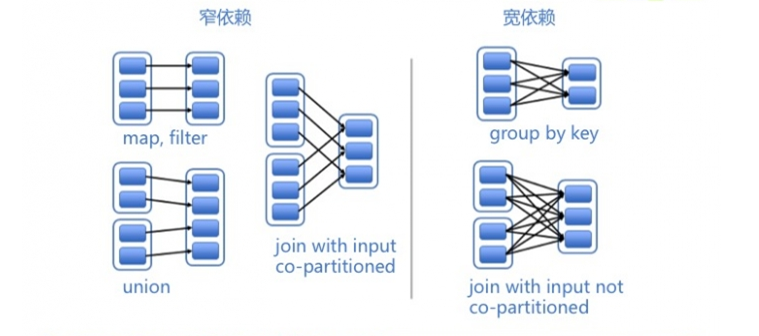
(1)窄依赖相比宽依赖更高效资源消耗更少
(2)允许在单个集群节点上流水线式执行,这个节点可以计算所有父级分区。例如,可以逐个元素地依次执行filter操作和map操作。
(3)相反,宽依赖需要所有的父RDD数据可用并且数据已经通过类MapReduce的操作shuffle完成。
(4) 在窄依赖中,节点失败后的恢复更加高效。因为只有丢失的父级分区需要重新计算,并且这些丢失的父级分区可以并行地在不同节点上重新计算。
(5)与此相反,在宽依赖的继承关系中,单个失败的节点可能导致一个RDD的所有先祖RDD中的一些分区丢失,导致计算的重新执行。
RDD-compute
分区计算
Spark对RDD的计算是以partition为最小单位的,并且都是对迭代器进行复合,不需要保存每次的计算结果
RDD- partitioner
分区函数:目前spark中提供两种分区函数:
(1)HashPatitioner(哈希分区)
(2)RangePatitioner(区域分区)
且partitioner只存在于(K,V)类型的RDD中,rdd本身决定了分区的数量。
RDD- lineage
val lines = sc.textFile("hdfs://...")
// transformed RDDs
val errors = lines.filter(_.startsWith("ERROR"))
val messages = errors.map(_.split("\t")).map(r => r(1))
messages.cache()
// action 1
messages.filter(_.contains("mysql")).count()
// action 2
messages.filter(_.contains("php")).count()


RDD经过trans或action后产生一个新的RDD,RDD之间的通过lineage来表达依赖关系,lineage是rdd容错的重要机制,rdd转换后的分区可能在转换前分区的节点内存中
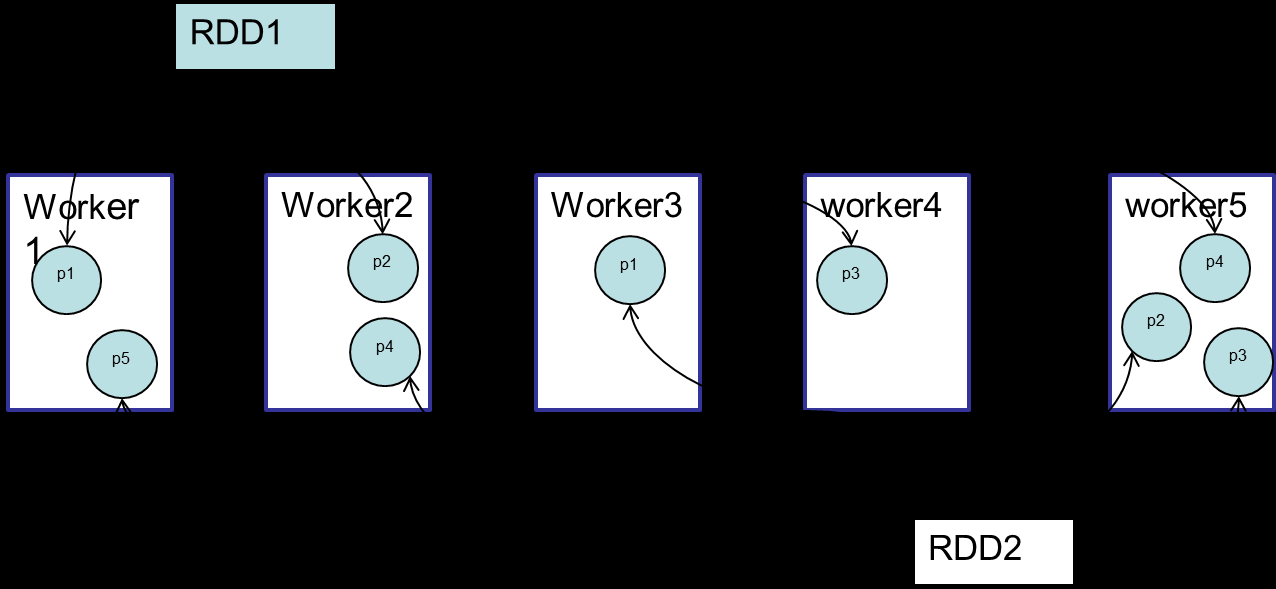
典型RDD的特征

不同角度看RDD
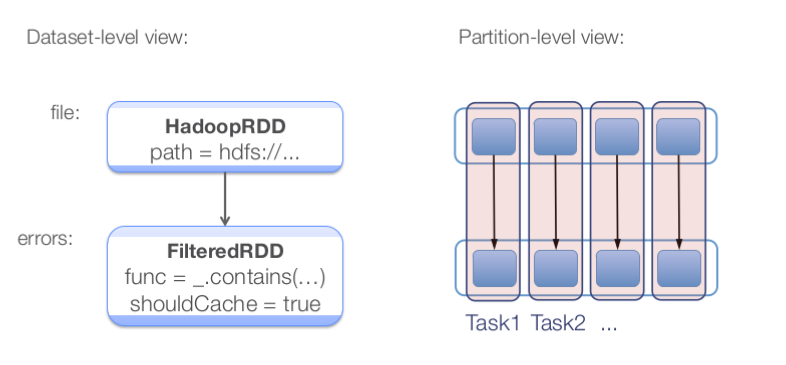
Scheduler Optimizations
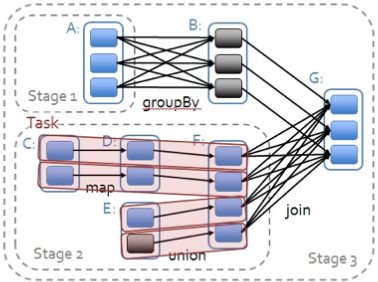
Spark编程模型(中)
创建RDD
方式一:从集合创建RDD
(1)makeRDD
(2)Parallelize
注意:makeRDD可以指定每个分区perferredLocations参数,而parallelize则没有。
方式二:读取外部存储创建RDD
Spark与Hadoop完全兼容,所以对Hadoop所支持的文件类型或者数据库类型,Spark同样支持。
(1)多文件格式支持:

(2)多文件系统支持:
1)本地文件系统
2)S3
3)HDFS
(3)数据库
1)JdbcRDD
2)spark-cassandra-connector(datastax/spark-cassandra-connector)
3)org.apache.hadoop.hbase.mapreduce.TableInputFormat(SparkContext.newAPIHadoopRDD)
4)Elasticsearch-Hadoop
transformation操作
惰性求值
(1)RDD 的转化操作都是惰性求值的。这意味着在被调用行动操作之前Spark 不会开始计算
(2)读取数据到RDD的操作也是惰性的
(3)惰性求值的好处:
a.Spark 使用惰性求值可以把一些操作合并到一起来减少计算数据的步骤。在类似 Hadoop MapReduce 的系统中,开发者常常花费大量时间考虑如何把操作组合到一起,以减少MapReduce 的周期数。
b.而在Spark 中,写出一个非常复杂的映射并不见得能比使用很多简单的连续操作获得好很多的性能。因此,用户可以用更小的操作来组织他们的程序,这样也使这些操作更容易管理。
转换操作
RDD 的转化操作是返回新RDD 的操作
我们不应该把RDD 看作存放着特定数据的数据集,而最好把每个RDD 当作我们通过转化操作构建出来的、记录如何计算数据的指令列表。
基本转换操作1

基本转换操作2

控制操作
(1)persist操作,可以将RDD持久化到不同层次的存储介质,以便后续操作重复使用。
1)cache:RDD[T]
2)persist:RDD[T]
3)Persist(level:StorageLevel):RDD[T]
(2)checkpoint
将RDD持久化到HDFS中,与persist操作不同的是checkpoint会切断此RDD之前的依赖关系,而persist依然保留RDD的依赖关系。
注意:控制操作的细节会在后续博客专门讲解
action操作

Spark编程模型(下)
什么是Pair RDD
(1)包含键值对类型的RDD被称作Pair RDD
(2)Pair RDD通常用来进行聚合计算
(3)Pair RDD通常由普通RDD做ETL转换而来
创建Pair RDD
Python语言
pairs = lines.map(lambda x: (x.split(" ")[0], x))
scala语言
val pairs = lines.map(x => (x.split(" ")(0), x))
Java语言
PairFunction keyData =
new PairFunction() {
public Tuple2 call(String x) {
return new Tuple2(x.split(" ")[0], x);
}
};
JavaPairRDD pairs = lines.mapToPair(keyData);
Pair RDD的transformation操作
Pair RDD转换操作1
Pair RDD 可以使用所有标准RDD 上转化操作,还提供了特有的转换操作。

Pair RDD转换操作2

Pair RDD的action操作
Pair RDD转换操作1
所有基础RDD 支持的行动操作也都在pair RDD 上可用

Pair RDD的分区控制
Pair RDD的分区控制
(1) Spark 中所有的键值对RDD 都可以进行分区控制---自定义分区
(2)自定义分区的好处:
1)避免数据倾斜
2)控制task并行度
自定义分区方式
class DomainNamePartitioner(numParts: Int) extends Partitioner {
override def numPartitions: Int = numParts
override def getPartition(key: Any): Int = {
val domain = new Java.net.URL(key.toString).getHost()
val code = (domain.hashCode % numPartitions)
if(code < 0) {
code + numPartitions // 使其非负
}else{
code
}
}
// 用来让Spark区分分区函数对象的Java equals方法
override def equals(other: Any): Boolean = other match {
case dnp: DomainNamePartitioner =>
dnp.numPartitions == numPartitions
case _ =>
false
}
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()




打开百度App,扫码,精彩文章每天更新!欢迎关注我的百家号: 九月哥快讯
Spark编程模型(博主推荐)的更多相关文章
- 使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码(博主强烈推荐)
前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. 准备工作 1.sca ...
- Spark on YARN简介与运行wordcount(master、slave1和slave2)(博主推荐)
前期博客 Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz +hadoop-2.6.0.tar.gz)(master.slave1和slave2)(博主 ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
- 再谈spark部署搭建和企业级项目接轨的入门经验(博主推荐)
进入我这篇博客的博友们,相信你们具备有一定的spark学习基础和实践了. 先给大家来梳理下.spark的运行模式和常用的standalone.yarn部署.这里不多赘述,自行点击去扩展. 1.Spar ...
- Spark编程模型(下)
创建Pair RDD 什么是Pair RDD 包含键值对类型的RDD类型被称作Pair RDD: Pair RDD通常用来进行聚合计算: Pair RDD通常由普通RDD做ETL转化而来. Pytho ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--3.Spark编程模型(下)--IDEA搭建及实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 . 安装IntelliJ IDEA IDEA 全称 IntelliJ IDEA,是java语 ...
- Spark:Spark 编程模型及快速入门
http://blog.csdn.net/pipisorry/article/details/52366356 Spark编程模型 SparkContext类和SparkConf类 代码中初始化 我们 ...
- 如何在IDEA里给大数据项目导入该项目的相关源码(博主推荐)(类似eclipse里同一个workspace下单个子项目存在)(图文详解)
不多说,直接上干货! 如果在一个界面里,可以是单个项目 注意:本文是以gradle项目的方式来做的! 如何在IDEA里正确导入从Github上下载的Gradle项目(含相关源码)(博主推荐)(图文详解 ...
随机推荐
- Android 自定义EditText实现类iOS风格搜索框
最近在项目中有使用到搜索框的地方,由于其样式要求与iOS的UISearchBar的风格一致.默认情况下,搜索图标和文字是居中的,在获取焦点的时候,图标和文字左移.但是在Android是并没有这样的控件 ...
- PostgreSQL Replication之第三章 理解即时恢复(4)
3.4 重放事务日志 一旦我们创建了一个我们自己的初始基础备份,我们可以收集数据库创建的XLOG.当时间到时,我们可以使用所有这些XLOG 文件并执行我们所期望的恢复进程.这就像本节描述的一样工作. ...
- python制造模块
制造模块: 方法一: 1.mkdir /xxcd /xx 2.文件包含: 模块名.py setup.py setup.py内容如下:#!/usr/bin/env pythonfrom distutil ...
- python、js 时间日期模块time
python 参考链接:https://www.runoob.com/python/python-date-time.html 时间戳 >>> print(time.time())# ...
- WHU 1548 Home 2-SAT
---恢复内容开始--- 题意: N个人想回家在至少一个时刻.至多两个时刻.并且,他们每个人都能独自回家. 定义:ai表示第i个人回家的时间, xij = abs(ai - aj) (i != j). ...
- 移动端开发ios和安卓兼容问题
移动端开发ios和安卓兼容问题 最近做移动端混合开的时候遇到一些安卓和iOS的兼容性问题,兼容想问题不仅在浏览器存在也在APP开发当中也会经常遇到这样的情况. 最近看了一下内容很不错的移动端开发相关的 ...
- Java代码规范文档
NOTE:以下部分为一个简要的编码规范,更多规范请参考 ORACLE 官方文档. 地址:http://www.oracle.com/technetwork/java/codeconventions-1 ...
- intellij idea中快速抽取方法
Intellij Idea使用教程汇总篇 问题:有时候一个方法里面嵌套了很多逻辑,想拆分为多个方法方便调用:或者一个方法复用性很高,这时,这个方法嵌套在局部方法里面肯定是不方便的,如何快速抽取出这个方 ...
- COGS 577 蝗灾 线段树+CDQ分治
第一次写cdq分治 感谢hhd<y 这20亿对CP的指导(逃) 其实 就是 递归看左半部分对右半部分的贡献 (树状数组写挂了--临时改的线段树[大写的尴尬]) //By SiriusRen ...
- POJ 3256 DFS水题
枚举点 每次都搜一遍 //By SiriusRen #include <cstdio> #include <cstring> #include <algorithm> ...